前言
在2017年9到12月份参加了kaggle平台上的一个文本分类比赛:Spooky author identification,这个比赛会给出三个恐怖小说作家作品里的一些英文句子。参赛者所要做的是用训练数据训练出合适的模型,让模型在测试数据上有好的泛化效果。笔者认为这个比赛对于提高文本方面的特征工程能力有挺多启发,因此写下这篇博客。有兴趣的人可以去下载这个比赛的数据集练手。如果因为墙的原因访问速度太慢,可以从我分享的百度网盘链接(密码:kudo)中下载数据。
数据描述
比赛给我们提供的文本数据中一共有三个作者:Edgar Allan Poe,HP Lovecraft和Mary Shelley。分别简写为:EAP,HPL,MWS。取出train.csv中的前10条数据如下:

简单统计了一下,训练文本中单词数最多的有861,最少的只有2,数量的跨度还是比较大的。下面给出一些其他信息的统计图:
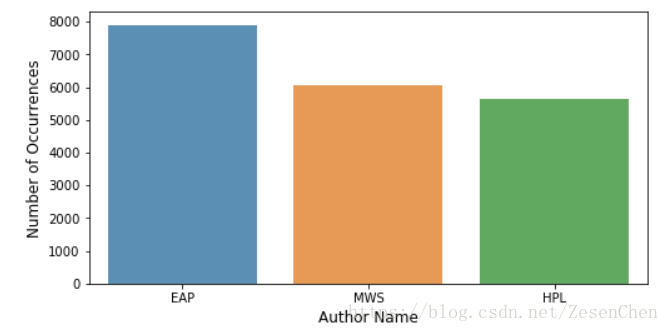
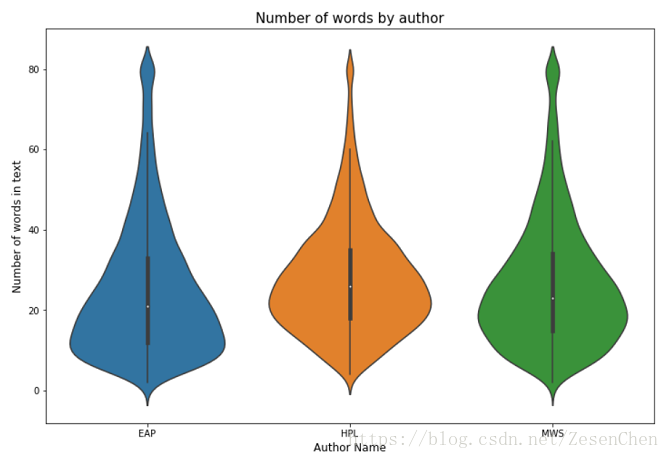
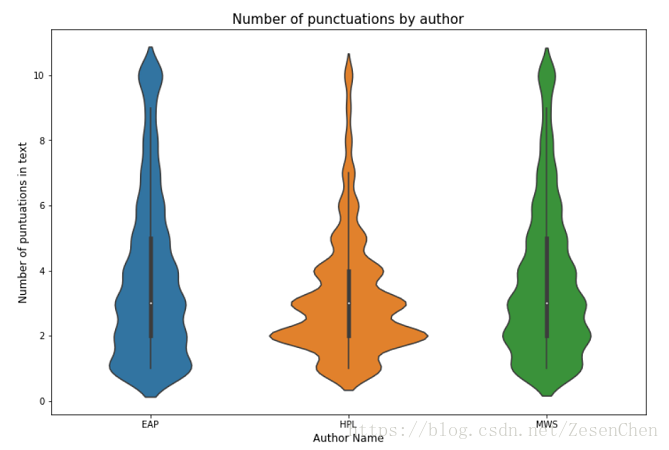
第一张图统计的是各个作者的文本数量;第二张图统计的是文本数据中单词的数量分布,可以看出各个作者的单词数量分布是有一定差异的;最后一张图统计的是各个作者的标点符号使用次数,根据我们的直觉不同人使用标点符号的习惯应该是不一样的,统计结果也印证了我们的判断。
特征工程
元特征
在上面的数据描述中我们可以看出很多各个作者独有的写作特点,比如:单词数量,标点符号数量等,虽然比赛官方给我们截取的文本不一定是完整的句子,但从分布统计图来看这几个特征应该是可行的。这种直观上能想到的特征我们称它们为元特征,下面我列出我所使用的元特征:
| 特征种类 | 特征名称 | 特征维度 |
|---|---|---|
| 元特征 | 单词数目 | 1 |
| 元特征 | 独立单词的数目 | 1 |
| 元特征 | 字符数 | 1 |
| 元特征 | 停用单词数目 | 1 |
| 元特征 | 标点符号数目 | 1 |
| 元特征 | 大写单词数目 | 1 |
| 元特征 | 标题类单词数目 | 1 |
| 元特征 | 单词平均长度 | 1 |
简单解释一下独立单词和停用单词的意思:独立单词的数目是指句子中不重复的单词总数,停用单词是指一些对短语表述不构成直接影响的单词,比如this,the,then等,英文中一共有153个stop words。下面给出提取这些特征的python2.7代码:
import pandas as pd
from nltk.corpus import stopwords
def clean_text(x):
tmp = x.lower()
for p in punctuation:
tmp = tmp.replace(p, '')
return tmp
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
eng_stopwords = set(stopwords.words("english"))
pd.options.mode.chained_assignment = None
punctuation = string.punctuation
train_df['text_cleaned'] = train_df['text'].apply(lambda x: clean_text(x))
test_df['text_cleaned'] = test_df['text'].apply(lambda x: clean_text(x))
train_df["num_words"] = train_df["text"].apply(lambda x: len(str(x).split()))
test_df["num_words"] = test_df["text"].apply(lambda x: len(str(x).split()))
train_df["num_unique_words"] = train_df["text"].apply(lambda x: len(set(str(x).split())))
test_df["num_unique_words"] = test_df["text"].apply(lambda x: len(set(str(x).split())))
train_df["num_chars"] = train_df["text"].apply(lambda x: len(str(x)))
test_df["num_chars"] = test_df["text"].apply(lambda x: len(str(x)))
train_df["num_words_upper"] = train_df['text'].apply(lambda x: len([w for w in str(x).split() if w.isupper()]))
test_df["num_words_upper"] = test_df['text'].apply(lambda x: len([w for w in str(x).split() if w.isupper()]))
train_df["num_stopwords"] = train_df["text_cleaned"].apply(lambda x: len([w for w in str(x).lower().split() if w in eng_stopwords]))
test_df["num_stopwords"] = test_df["text_cleaned"].apply(lambda x: len([w for w in str(x).lower().split() if w in eng_stopwords]))
train_df["num_punctuations"] = train_df["text"].apply(lambda x: len([w for w in str(x) if w in string.punctuation]))
test_df["num_punctuations"] = test_df["text"].apply(lambda x: len([w for w in str(x) if w in string.punctuation]))
train_df["num_words_title"] = train_df["text_cleaned"].apply(lambda x: len([w for w in str(x).split() if w.istitle()]))
test_df["num_words_title"] = test_df["text_cleaned"].apply(lambda x: len([w for w in str(x).split() if w.istitle()]))
train_df["mean_word_len"] = train_df["text_cleaned"].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
test_df["mean_word_len"] = test_df["text_cleaned"].apply(lambda x: np.mean([len(w) for w in str(x).split()]))基于文本的特征
统计特征
上面提到的元特征是我们直观感觉上觉得有用的特征,还有一些是基于文本统计的,物理意义可能没那么明显的特征,这里我们称之为基于文本的特征。最简单的基于文本的特征就是词袋模型,整个文本数据中有多少个单词,词袋向量就有多少个维度,一个句子中哪些单词出现了,对应的元素位置就置为1,其他位置都置0。这种方法非常直白但也是一种有效的文本特征,它的缺点在于仅仅体现了某个单词出现与否,但没办法体现单词的重要程度,比如冠词的重要程度显然比不上人物名字的重要程度。所以一般情况下我们会采用更有效的文本特征。
scikit-learn中有feature extraction模块里面有专门用于文本特征抽取的api:我们用到的是CountVectorizer,TfidfVectorizer。简单来说CountVectorizer就是一个计数函数,对于整个文本数据,它能统计出每个单词出现的次数并将其转换成数值型的特征向量;而TfidfVectorizer不仅能表示单词出现与否,还能表示单词的重要程度以体现出文本之间的区分性。具体细节可参考scikit-learn文档。这里直接给出抽取这两种特征的python代码:
tfidf_vec = TfidfVectorizer(stop_words='english', ngram_range=(1,3))
full_tfidf = tfidf_vec.fit_transform(train_df['text'].values.tolist() + test_df['text'].values.tolist())
train_tfidf = tfidf_vec.transform(train_df['text'].values.tolist())
test_tfidf = tfidf_vec.transform(test_df['text'].values.tolist())
tfidf_vec1 = CountVectorizer(ngram_range=(1,3))
tfidf_vec1.fit(train_df['text'].values.tolist() + test_df['text'].values.tolist())
train_tfidf1 = tfidf_vec.transform(train_df['text'].values.tolist())
test_tfidf1 = tfidf_vec.transform(test_df['text'].values.tolist())这里的代码仅仅是以最简单的形式展现如何提取这两种特征,具体场景下还要参考文档中的参数说明来进行调参。

笔者认为,红圈中的参数都有比较重要的意义,不同的参数组合能够带来不同的特征,而不同的特征,通过合适的stacking方法可以提高模型的最终性能。 比如我通过不同的参数组合得到了10种不同的特征,我可以用贝叶斯分类器训练出10个模型,然后把预测结果作为新的特征,这是kaggle比赛中一种常用的技巧。在博客的最后我会给出一份效果比较好的python代码,有兴趣的可以看看其中的一些参数设置与特征组合的trick。
对于 CountVectorizer和 TfidfVectorizer转换得到的特征维度都是非常高的,如果单纯用个分类器做stacking处理的话每次只能得到3个维度的特征,这肯定是会造成特征浪费的。所以我们不妨把这些高维的特征再做个降维处理,得到新的特征。你可以尝试不同的方法,而我当时用的是SVD:
from sklearn.decomposition import TruncatedSVD
n_comp = 20
svd_obj = TruncatedSVD(n_components=n_comp, algorithm='arpack')
svd_obj.fit(full_tfidf)
train_svd = pd.DataFrame(svd_obj.transform(train_tfidf))
test_svd = pd.DataFrame(svd_obj.transform(test_tfidf))
train_svd.columns = ['svd_word2_'+str(i) for i in range(n_comp)]
test_svd.columns = ['svd_word2_'+str(i) for i in range(n_comp)]
train_df = pd.concat([train_df, train_svd], axis=1)
test_df = pd.concat([test_df, test_svd], axis=1)
del full_tfidf, train_tfidf, test_tfidf, train_svd, test_svdword embedding
关于word embedding的原理在这个博客我不打算多讲,后面考虑单独写一篇进行word embedding的原理介绍和工具的使用介绍。这里简单说一下,文本数据都是非数值型的字符串,要将它们作为数据进行模型训练,势必要把它们转换成维度相同的数值特征向量。word embedding利用了神经网络方法,将每个文本词汇都映射到一个维度恒定的数值特征空间中,这样一来每个单词都能单独表示成一个独一无二的特征向量。那么句子如何表示呢,单词向量的均值+单词向量的方差;这样我们就得到了每个句子的向量化表示。
常用的工具包有word2vec,Glove,Deep Walk,Node2vec,fasttext等,在这里我们使用了Glove方法,链接是Glove的github地址,里面有预训练好的word vec文件,文件中包含了所有单词的数值向量表示,维度是300。
import numpy as np
def sent2vec(s):
words = str(s).lower().decode('utf-8')
words = word_tokenize(words)
words = [w for w in words if not w in eng_stopwords]
words = [w for w in words if w.isalpha()]
M = []
for w in words:
try:
M.append(embeddings_index[w])
except:
continue
M = np.array(M)
v = M.sum(axis=0)
if type(v) != np.ndarray:
return np.zeros(300)
return v / np.sqrt((v ** 2).sum())
f = open('glove.840B.300d.txt')
for line in tqdm(f):
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
xtrain_glove = [sent2vec(x) for x in tqdm(train_df.text)]
xtest_glove = [sent2vec(x) for x in tqdm(test_df.text)]
xtrain_glove = np.array(xtrain_glove)
xtest_glove = np.array(xtest_glove)
train_df = pd.concat([train_df, pd.DataFrame(xtrain_glove)], axis=1)
test_df = pd.concat([test_df, pd.DataFrame(xtest_glove)], axis=1)其他特征
上面说到的那些特征其实有一定参赛经验的人都能想到,一堆特征工程的套路+XGBoost/RF/GBDT/deep learning+stacking已经是习以为常的套路。但如果每个人都这么做的话大家的最后的score大概都会扎堆在一个地方。所以想要在kaggle比赛中取得一个稍微靠前的名次有时就需要一些奇技淫巧。像这个文本分类的比赛,大家基本都会用上面提到的那些features。但有些人就能想到一些其他比较特殊的,举一些例子:
1、26个字母大小写数目的统计,52维的特征;
2、文本中出现的城市名称,这也能构成一类特征;
3、统计文本数据中出现次数最高的30个词语,给出每个句子中这些词语出现次数,这就又多了个30维的特征;
4、统计常用的那些标点符号的出现次数;
结语
笔者与同学合作参加了这个文本分类比赛,使用了上面提到的特征工程思路和技巧,最终取得了还不错的名次,写下这篇博客一方面是复习下文本特征工程的一些技巧,另一方面给参加这方面比赛的人一点参考。
