文件的读写(savetxt(写))、(loadtxt(读))
import numpy as np# a=np.eye(6)# np.savetxt('lianxi.txt',a,fmt='%d')# b=np.loadtxt('lianxi.txt')# print(b)
数组的计算(axis=0,代表操作行,axis=1,代表操作列)
删除数据
# b=np.arange(12).reshape(3,4)# b1=np.delete(b,0,axis=0) #数组元素的计算axis=0,代表操作行,axis=1,代表操作列# print(b1)
计算加权平均数(average)
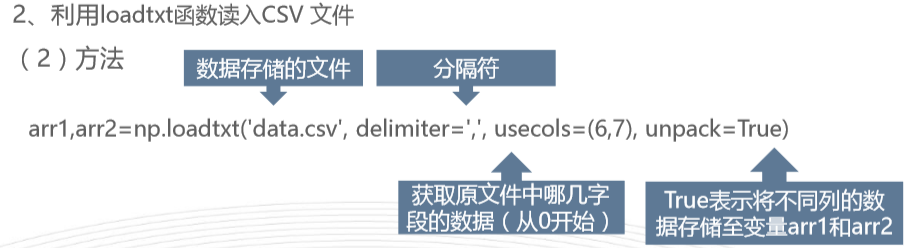
加权平均数的计算(average)np.average(求那一列,weights=将什么做为权重)
计算算数平均值、最大最小值、极差、中位数、方差
# b=np.arange(12).reshape(3,4)# b1=np.delete(b,0,axis=0) #数组元素的计算axis=0,代表操作行,axis=1,代表操作列# print(b1)#加权平均数# b1,b2,b3=np.loadtxt('data.csv',delimiter=',',usecols=(5,6,7),unpack=True)# print(b2)# print(b3)# b4=np.average(b2,weights=b3)# b5=np.average(b2)# print(b4)# b6=np.mean(b2) #算数平均数# print(b6)# print(b5)# b7=max(b2) #最大# b8=min(b2) #最小# print(b8)# print(b7)# b9=np.ptp(b2) #极差# print(b9)## c1=np.median(b2) #中位数# print(c1)## c2=np.var(b2) #计算方差,方差越大波动越大# c3=np.var(b1)# print(c3)# print(c2)
计算股价收益率、年波动率、月波动率 
计算简单收益率、标准差
#简单收益率# syl=np.diff(b2)/b2[:-1]# print(syl)#标准差# bzc=np.std(syl)# print(bzc)
计算对数收益率(先用log函数得到每一个收盘价的对数)
#对数收益率利用log函数获取每天收盘价的对数# dssyl=np.diff(np.log(b2))# print(dssyl)
获取收益率的正值
#获取收益率为正值的值所对应的下标# zsyl=np.where(dssyl>0)# print(zsyl)
股票的年波动率、月波动率 
#计算年波动率(年波动率等于对数收益率的标准差除以其均值,在除以交易日倒数的平方根,通常交易日为252天)# nbdl=np.std(dssyl)/np.mean(dssyl)/np.sqrt(1/252)# print(nbdl)#计算月波动率# ybdl=np.std(dssyl)/np.mean(dssyl)/np.sqrt(1/12)# print(ybdl)
其他常用函数
求数组内元素的乘积(prod)(cumprod)、求和(sum)
#数组的计算a=np.arange(1,21)print(a)a=np.cumprod(a)print(a)b=np.sum(a) #求和print(b)结果:[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20][ 1 2 6 24 120 7205040 40320 362880 3628800 39916800 4790016001932053504 1278945280 2004310016 2004189184 -288522240 -898433024109641728 -2102132736]268040729
数组的修剪(clip) 
数组的压缩 
日期处理函数
#时间日期函数(datetime)# from datetime import datetime# shijian=datetime.strptime('2017-12-31T10:53:49.875z','%Y-%m-%dT%H:%M:%S.%fZ')# print(shijian)#获取年月日# data1=shijian.date()# print(data1)#可以分别获取年、月、日# print(shijian.day)# print(shijian.month)# print(shijian.year)#也可分别获取时、分、秒# print(shijian.hour)# print(shijian.minute)# print(shijian.second)
案例分析






import numpy as npfrom datetime import datetime#获取当前日期的星期几def datestr2num(s):return datetime.strptime(s.decode('ascii'), "%d-%m-%Y").date().weekday()dates,close=np.loadtxt('./excel/data.csv', delimiter=',', usecols=(1,6), converters={1:datestr2num}, unpack=True)print(dates)averages=np.zeros(5)for i in range(5):#获取当天所对应的收盘价xiabiao=np.where(i==dates)spj=np.take(close,xiabiao)avg=np.mean(spj)averages[i]=avgprint("周",str(i+1)," 收盘价:",spj," 平均价为:",avg)#获取评价收盘价,最高是星期几,最低又是星期几print(averages)d1=np.argmax(averages)print(d1)d2=np.argmin(averages)print(d2)
作业
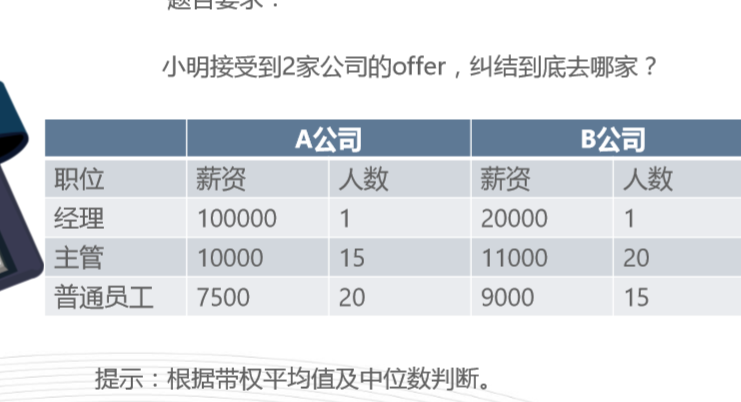
import numpy as npa=np.array([[100000,1,20000,1],[10000,15,11000,20],[7500,20,9000,15]])print(a)#A公司的薪资a1=a[:,0]#A公司所对应人数a2=a[:,1]#A公司的薪资a3=a[:,2]#A公司所对应人数a4=a[:,3]print(a1)print(a2)print(a3)print(a4)#A公司以人数为权重计算工资的平均值b1=np.average(a1,weights=a2)print(b1)#B公司以人数为权重计算工资的平均值b2=np.average(a3,weights=a4)print(b2)#A公司薪资的中位数7500#B公司薪资的中位数11000#A公司加权平均数相对较高,是因为经理的工资占列很大的权重,拉高列平均工资#B公司工资的中位数和众数较高相交之下,会更适合