老生常谈的话题了,所以直接看demo吧
/**
* 1.递归实现1-1000的累加
* 从最大的开始往下加
*/
public int sum(int num) {
if (num == 1) {
return 1;
} else
return num + sum(num - 1);
}
/**
* 2.for循环实现1-1000的累加
* 从最小的开始往上加
*/
public int sum2(int num) {
int sum = 0;
for (int i = 1; i <= num; i++) {
sum += i;
}
return sum;
}
/**
* 3.利用高斯定理实现1-1000的累加
* 不往上不往下,首尾成对计算和
*/
public int sum3(int num){
/*
* 判断成对的依据By对2求余
*/
int flag = num%2;
//如果成对的话,直接利用首尾相加*对数
if(flag==0){
//如果成对的话
int group = num/2;
return group*(1+num);
}
//否则的话 凑够偶数对 减去 那个凑个的数
return sum3(num+1)-(num+1);
}
@Test
public void Test10() {
System.out.println("最不推荐的方式:"+sum (1000)+" by 递归 ");
System.out.println("最常用的方式 :"+sum2(1000)+" by for循环");
System.out.println("最快的方式 :"+sum3(1000)+" by 高斯定理");
}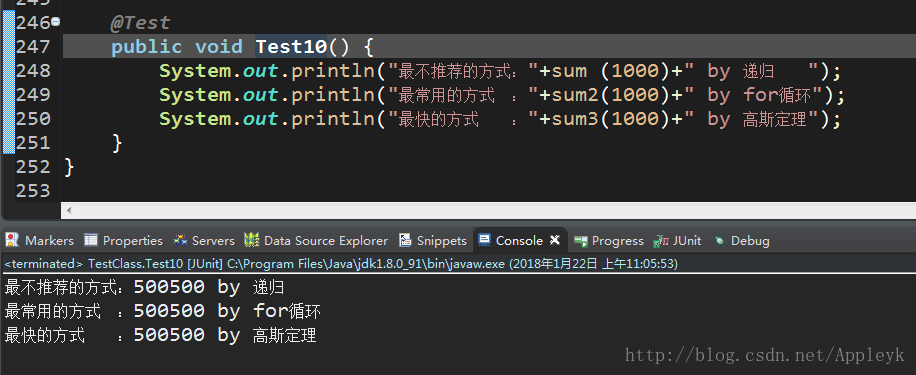
一、为什么最快的是高斯定理了,有图为证,

在这里,感谢我的一位大学室友红星,为我打开了"高斯定理"的思路,真的很棒!
思路很重要,如果我只会写代码,我永远不会想到要使用高斯定理来计算1到1000自然数的累加!
二、为什么不推荐用递归呢?
针对方法1(递归):我们试着计算更大的数,比如10000以内的连续自然数的和,为了防止整数溢出,我们调整函数返回值和参数值的类型,改为Long(长整型)类型,demo如下
/**
* 1.递归实现1-1000的累加
* 从最大的开始往下加
*/
public long sum(Long num) {
if (num == 1) {
return 1;
} else
return num + sum(num - 1);
}
@Test
public void Test10() {
System.out.println("最不推荐的方式:"+sum (10000L)+" by 递归 ");
}表面上看着没问题,其实已经挖下了坑,填上了一颗雷

以下内容摘自其他网博:
JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K
1.程序计数器
每一个Java线程都有一个程序计数器来用于保存程序执行到当前方法的哪一个指令
2.线程栈
线程的每个方法被执行的时候,都会同时创建一个帧(Frame)用于存储本地变量表、操作栈、动态链接、方法出入口等信息。每一个方法的调用至完成,就意味着一个帧在VM栈中的入栈至出栈的过程。如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverfloweError异常;如果VM栈可以动态扩展(VM Spec中允许固定长度的VM栈),当扩展时无法申请到足够内存时则抛出OutOfMemoryError异常。
因此,当我们的num达到10000,采用递归的方法计算sum时,此时递归的深度已经超出了当前VM栈所能允许的深度(栈只进不出,最后爆满,再也push不进去了)
换句话说就是:方法一直在向下执行,直到满足条件时才return,但VM栈却不领情:你小子我已经给你1M了,你还嫌不够吗,赶快给我停下!!! 于是乎异常StackOverfloweError出现了,程序崩掉!
所以,如果我们在程序中使用了递归方法的话,最好还是换成其他方式,比如本篇的其他两种方法,当然,有些时候,我们可以小心翼翼的使用递归方法,比如,利用递归列出指定路径下面的所有文件(不包括文件夹):
/**
* 递归获取指定路径下所有文件(文件夹信息不返回)
*/
public List<File> getFiles(String path, List<File> fileList) throws Exception {
if(fileList == null) {
fileList = new ArrayList<>();
}
//目标集合fileList
File file = new File(path);
if(file.isDirectory()){
File []files = file.listFiles();
for(File fileIndex : files){
//如果这个文件是目录,则进行递归搜索
if(fileIndex.isDirectory()){
getFiles(fileIndex.getPath(), fileList);
} else {
fileList.add(fileIndex);
}
}
}
return fileList;
}
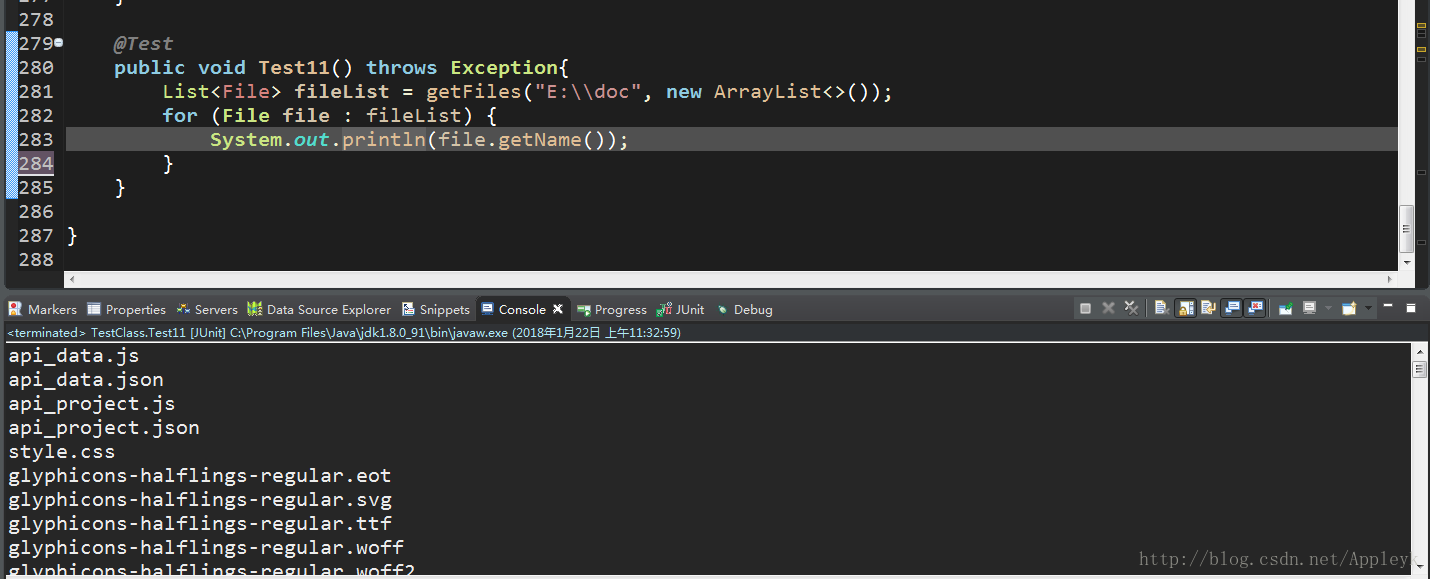
@Test
public void Test11() throws Exception{
List<File> fileList = getFiles("E:\\doc", new ArrayList<>());
for (File file : fileList) {
System.out.println(file.getName());
}
}
一般文件路径不会套的太深,没有谁会套成百上千个甚至更多个文件夹,如果这样的话,岂不是自找麻烦吗?
这也从另外一个角度阐释了什么是“没有绝对的完美,适合即最好”!
2018年1月22日11:45:20,我的第100篇博文诞生:
一路写来,感慨颇多,但拘泥于技术,写的也都只是零零散散,没有大的作为,也没有吸引人的深度,但贵在坚持,我从中受益,成长了不少。
这种坚持,还会持续下去,秉承着" 生命不止,折腾不断! 学习不止,技术创高!"的自我理念,我会继续前行,不断的遇坑,不断的填坑,更重要的是,写代码将不再是2018年工作和学习上的重中之重,反而是辅助工具,那重要的是什么了? 哈哈,卖个关子,容我思考一年再说!