←←←←←←←←←←←← 快,点关注!
介绍
redis是键值对的数据库,常用的五种数据类型为字符串类型(string),散列类型(hash),列表类型(list),集合类型(set),有序集合类型(zset)
Redis用作缓存,主要两个用途:高性能,高并发,因为内存天然支持高并发
应用场景
分布式锁(string)
setnx key value,当key不存在时,将 key 的值设为 value ,返回1。若给定的 key 已经存在,则setnx不做任何动作,返回0。
当setnx返回1时,表示获取锁,做完操作以后del key,表示释放锁,如果setnx返回0表示获取锁失败,整体思路大概就是这样,细节还是比较多的,有时间单开一篇来讲解
计数器(string)
如知乎每个问题的被浏览器次数
set key 0
incr key // incr readcount::{帖子id} 每阅读一次
get key // get readcount::{帖子id} 获取阅读量
分布式全局唯一id(string)
分布式全局唯一id的实现方式有很多,这里只介绍用redis实现
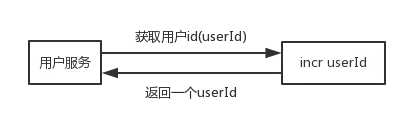
每次获取userId的时候,对userId加1再获取,可以改进为如下形式
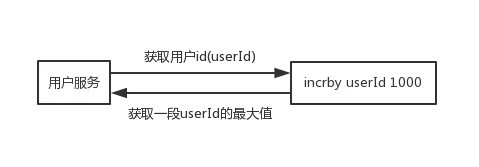
直接获取一段userId的最大值,缓存到本地慢慢累加,快到了userId的最大值时,再去获取一段,一个用户服务宕机了,也顶多一小段userId没有用到
set userId 0
incr usrId //返回1
incrby userId 1000 //返回10001
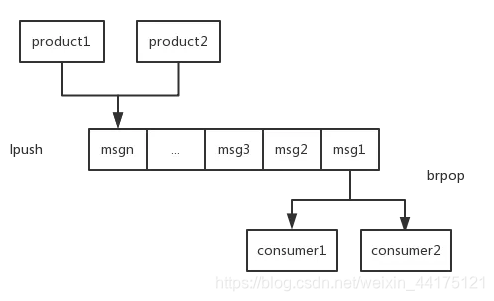
消息队列(list)
在list里面一边进,一边出即可
# 实现方式一
# 一直往list左边放
lpush key value
# key这个list有元素时,直接弹出,没有元素被阻塞,直到等待超时或发现可弹出元素为止,上面例子超时时间为10s
brpop key value 10
# 实现方式二
rpush key value
blpop key value 10
过期策略
定期删除
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
定期删除策略
Redis 默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
从过期字典中随机 20 个 key;
删除这 20 个 key 中已经过期的 key;
如果过期的 key 比率超过 1/4,那就重复步骤 1;
惰性删除
除了定期遍历之外,它还会使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
** 定期删除是集中处理,惰性删除是零散处理。**
为什么要采用定期删除+惰性删除2种策略呢?
如果过期就删除。假设redis里放了10万个key,都设置了过期时间,你每隔几百毫秒,就检查10万个key,那redis基本上就死了,cpu负载会很高的,消耗在你的检查过期key上了
但是问题是,定期删除可能会导致很多过期key到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个key的时候,redis会检查一下 ,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
并不是key到时间就被删除掉,而是你查询这个key的时候,redis再懒惰的检查一下
通过上述两种手段结合起来,保证过期的key一定会被干掉。
所以说用了上述2种策略后,下面这种现象就不难解释了:数据明明都过期了,但是还占有着内存
内存淘汰策略
这个问题可能有小伙伴们遇到过,放到Redis中的数据怎么没了?
因为Redis将数据放到内存中,内存是有限的,比如redis就只能用10个G,你要是往里面写了20个G的数据,会咋办?当然会干掉10个G的数据,然后就保留10个G的数据了。那干掉哪些数据?保留哪些数据?当然是干掉不常用的数据,保留常用的数据了
Redis提供的内存淘汰策略有如下几种:
- noeviction 不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
- volatile-lru 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。(这个是使用最多的)
- volatile-ttl 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl 越小越优先被淘汰。
- volatile-random 跟上面一样,不过淘汰的 key 是过期 key 集合中随机的 key。
- allkeys-lru 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。
- allkeys-random 跟上面一样,不过淘汰的策略是随机的 key。allkeys-random 跟上面一样,不过淘汰的策略是随机的 key。
持久化策略
Redis的数据是存在内存中的,如果Redis发生宕机,那么数据会全部丢失,因此必须提供持久化机制。
Redis 的持久化机制有两种,第一种是快照(RDB),第二种是 AOF 日志。快照是一次全量备份,AOF 日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本。AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。
RDB是通过Redis主进程fork子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化,AOF 日志存储的是 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。即RDB记录的是数据,AOF记录的是指令
RDB和AOF到底该如何选择?
- 不要仅仅使用 RDB,因为那样会导致你丢失很多数据,因为RDB是隔一段时间来备份数据
- 也不要仅仅使用 AOF,因为那样有两个问题,第一,通过 AOF 做冷备没有RDB恢复速度快; 第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug
- 用RDB恢复内存状态会丢失很多数据,重放AOP日志又很慢。Redis4.0推出了混合持久化来解决这个问题。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
缓存雪崩和缓存穿透
缓存雪崩是什么?
假设有如下一个系统,高峰期请求为5000次/秒,4000次走了缓存,只有1000次落到了数据库上,数据库每秒1000的并发是一个正常的指标,完全可以正常工作,但如果缓存宕机了,每秒5000次的请求会全部落到数据库上,数据库立马就死掉了,因为数据库一秒最多抗2000个请求,如果DBA重启数据库,立马又会被新的请求打死了,这就是缓存雪崩。
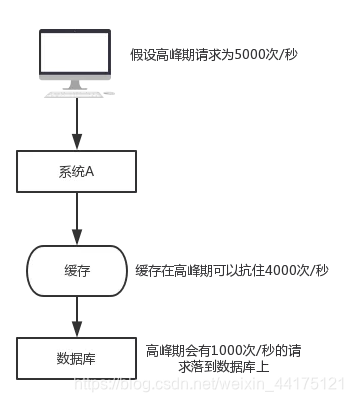
如何解决缓存雪崩
事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
事后:redis持久化,快速恢复缓存数据
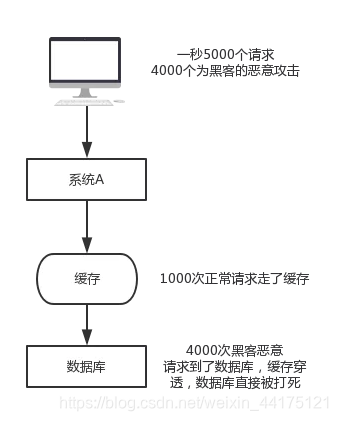
缓存穿透是什么?
假如客户端每秒发送5000个请求,其中4000个为黑客的恶意攻击,即在数据库中也查不到。举个例子,用户id为正数,黑客构造的用户id为负数,
如果黑客每秒一直发送这4000个请求,缓存就不起作用,数据库也很快被打死。
欢迎大家加入粉丝群:963944895,群内免费分享Spring框架、Mybatis框架SpringBoot框架、SpringMVC框架、SpringCloud微服务、Dubbo框架、Redis缓存、RabbitMq消息、JVM调优、Tomcat容器、MySQL数据库教学视频及架构学习思维导图
如何解决缓存穿透
查询不到的数据也放到缓存,value为空,如set -999 “”
总而言之,缓存雪崩就是缓存失效,请求全部全部打到数据库,数据库瞬间被打死。缓存穿透就是查询了一个一定不存在的数据,并且从存储层查不到的数据没有写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。