一、环境介绍
1. 系统环境
rhel6.5 selinux and iptables if disable
server1: 172.25.14.1 pacemaker + haproxy node1
server4: 172.25.14.4 pacemaker + haproxy node2
server2: 172.25.14.2 web1
server3:172.25..14.3 web2
2.前提条件
(因为之前有使用luci图形管理工具搭建高可用集群,所以在做本次实验之前确保这三个服务关闭并且不能开机子、自启动)
:::chkconfig cman off
:::chkconfig modclusterd off
:::chkconfig ricci off
:::/etc/init.d/ricci stop
:::/etc/init.d/modclusterd stop
:::/etc/init.d/cman
二、pacemaker介绍
Pacemaker是一个集群资源管理器。它利用集群基础构件(OpenAIS 、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。它可以做几乎任何规模的集群,并带有一个强大的依赖模式,让管理员能够准确地表达群集资源之间的关系(包括顺序和位置)。几乎任何可以编写的脚本,都可以作为管理起搏器集群的一部分。尤为重要的是Pacemaker不是一个heartbeat的分支,似乎很多人存在这样的误解。Pacemaker是CRM项目(亦名V2资源管理器)的延续,该项目最初是为heartbeat而开发,但目前已经成为独立项目。
1. pacemaker 特点
1)主机和应用程序级别的故障检测和恢复
2)几乎支持任何冗余配置
3)同时支持多种集群配置模式
4)可以测试任何故障或群集的群集状态
2. 关键组建
Pacemaker本身由四个关键组件组成:
•CIB (aka. 集群信息基础)
•CRMd (aka. 集群资源管理守护进程)
•PEngine (aka. PE or 策略引擎)
•STONITHd(心跳系统)
3. pacemaker的内部结构:
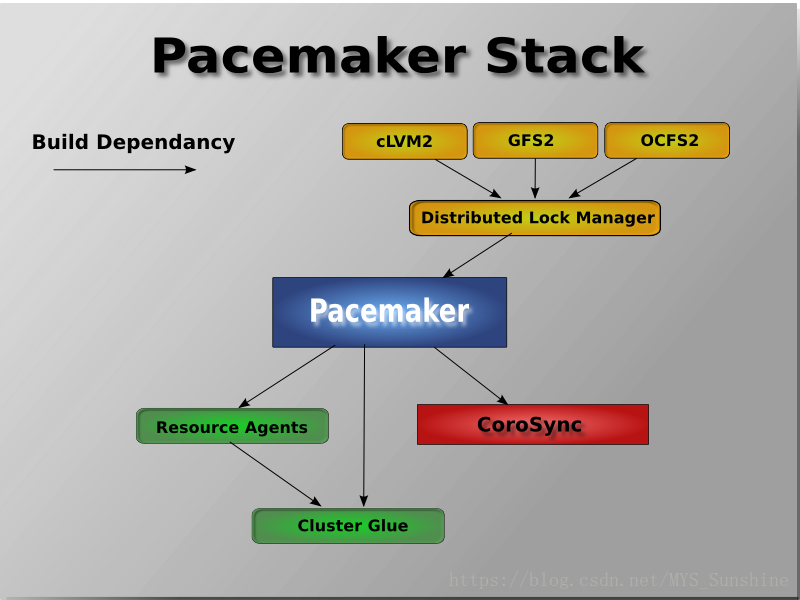
stonithd:心跳系统
lrmd:本地资源管理守护进程。它提供了一个通用的接口支持的资源类型。直接调用资源代理(脚本)
pengine:政策引擎。根据当前状态和配置集群计算的下一个状态。产生一个过渡图,包含行动和依赖关系的列表
cib:群集信息库。包含所有群集选项,节点,资源,他们彼此之间的关系和现状的定义。同步更新到所有群集节点
crmd:集群资源管理守护进程。主要是消息代理的PEngine和LRM,还选举一个领导者(DC)统筹活动(包括启动/停止资源)的集群
heartbeat:心跳消息层

CCM:共识群集成员,心跳成员
4. corosync
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议。corosync可以实现故障检测功能,发现存在问题的资源,同时也具有心跳检测机制 ,检测服务是否启用,运行在每个节点上,多个节点之间通过组播的方式监测心跳。
三、安装配置流程
1. server1和server4安装配置haproxy,配置相同。配置方式可参考如下文章,不再赘述。
https://blog.csdn.net/mys_sunshine/article/details/80363399
2. server1和server4安装配置pacemaker,配置相同。我们以server1为例
1)安装pacemaker
可以直接从镜像中下载
yum 源配置:
[root@server1 ~]# cat /etc/yum.repos.d/yum.repo
[rhel-source]
name=rhel-source
baseurl=http://172.25.14.250/rhel6.5
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.14.250/rhel6.5/LoadBalancer
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.14.250/rhel6.5/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.14.250/rhel6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.14.250/rhel6.5/ScalableFileSystem
gpgcheck=0
2)安装crmsh及其依赖包pssh
其可从如下网址中下载:https://pkgs.org/
crm:管理集群的工具
crm的特性:
任何操作都需要commit提交后才会生效;
想要删除一个资源之前需要先将资源停止;
可以用 help 获取该命令的帮助;
与Linux命令行一样,都支持TAB补全

3)corosync的配置
[root@server1 ~]# cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
[root@server1 ~]# vim /etc/corosync/corosync.conf
bindnetaddr: 172.25.14.0 #心跳监听网段
mcastaddr: 226.94.1.1 #约定的广播地址,所有节点相同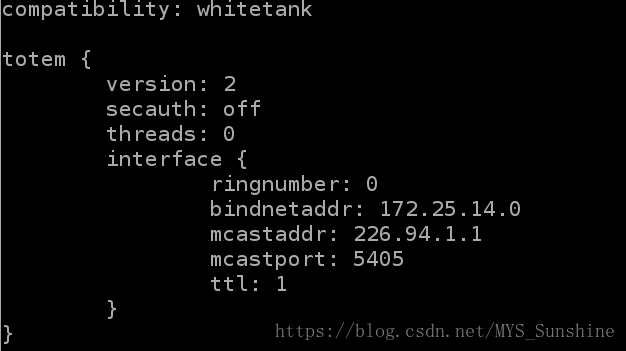
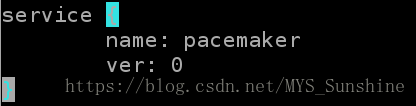
# corosync以插件形式运行pacemaker
service {
name: pacemaker
ver: 0 #自动随着corosync开启
}
每一个节点的/etc/corosync.conf都要相同,之后所有节点重启corosync服务
3. 配置采集集群
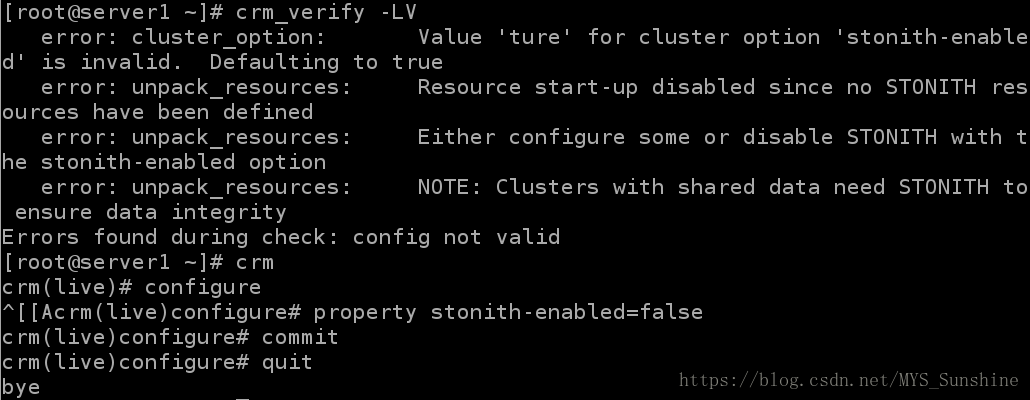
1)crm_verify -LV ##检查crm的语句是否有错
#关掉报错
crm(live)configure# property stonith-enabled=false
crm(live)configure# commit
[root@server1 ~]# crm_verify -LV
无报错Stonith 即shoot the other node in the head使Heartbeat软件包的一部分,该组件允许系统自动地复位一个失败的服务器使用连接到一个健康的服务器的遥远电源设备。Stonith设备是一种能够自动关闭电源来响应软件命令的设备

#关闭集群对节点数量的检查,节点server1如果故障,节点server4收不到心跳请求,直接接管程序,保证正常运行,不至于一个节点崩掉而使整个集群崩掉
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit2)参数介绍

cib #cib管理模块
resource #所有的资源都在这个子命令后定义:cleanup #清理资源状态;refresh #LRM本地资源管理更新CIB(集群信息库)
configure #编辑集群配置信息:show #显示集群信息库;edit #编辑集群信息库对象(vim模式下编辑);delete #删除CIB对象;primitive #定义资源;monitor #对一个资源添加监控选项(如超时时间,启动失败后的操作);group #定义一个组类型(将多个资源整合在一起)
node #集群节点管理子命令:status #以xml格式显示节点状态信息;show #命令行格式显示节点状态信息;standby #模拟指定节点离线(standby在后面必须的FQDN);online #节点重新上线;fence #隔离节点;delete #删除 一个节点
options #用户优先级
# 注:关于crm 其他详细参数参考如下文档:
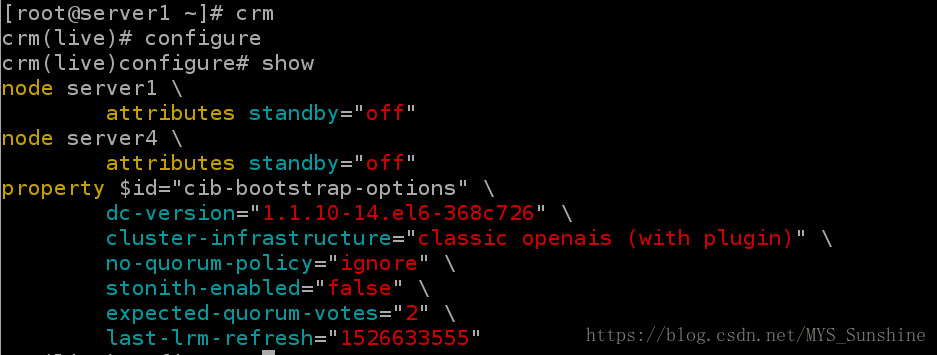
http://blog.chinaunix.net/uid-30212356-id-5345399.html3)crm configure show ##查看集群的信息
4)添加虚拟IP
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.14.100 cidr_netmask=24 op monitor interval=30
crm(live)configure# commit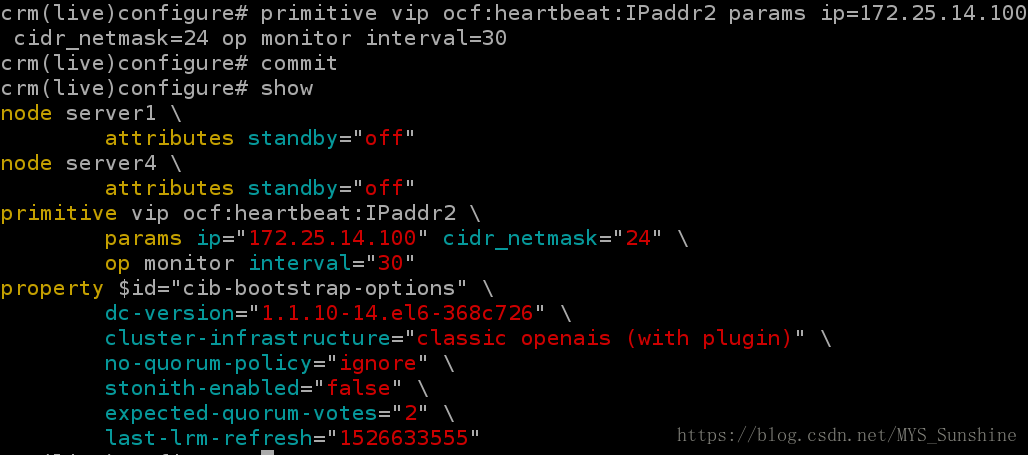
5)添加服务haproxy
crm(live)configure# primitive haproxy lsb:haproxy op monitor interval=1min
crm(live)configure# commit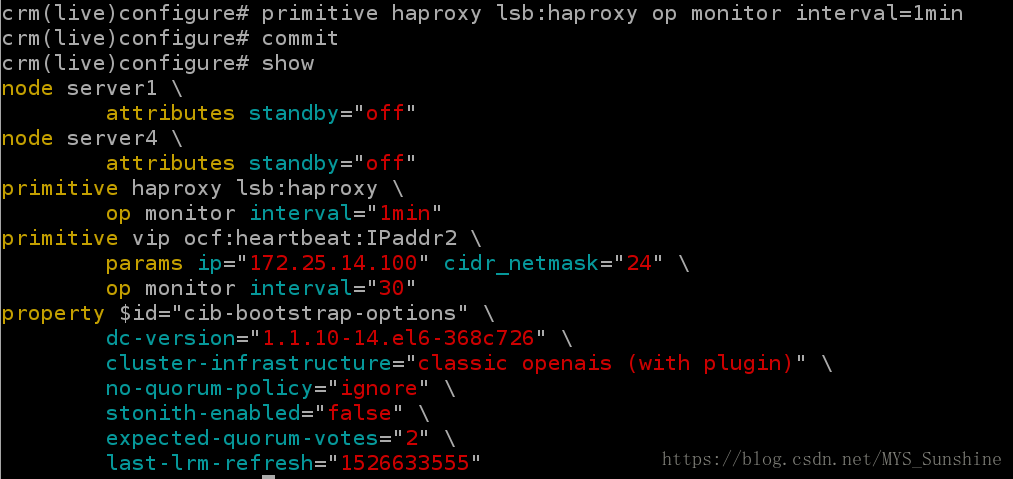
6)添加资源组
crm(live)configure# group sunshine vip haproxy
crm(live)configure# commit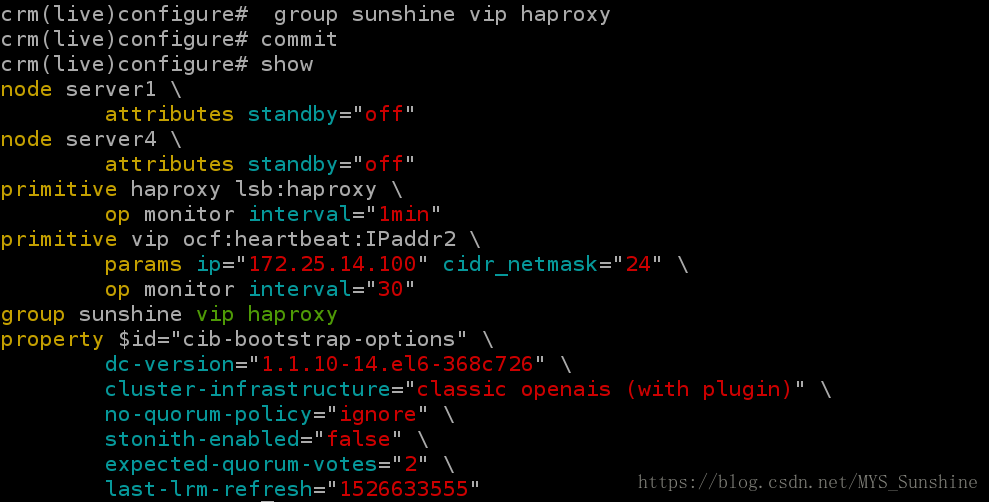
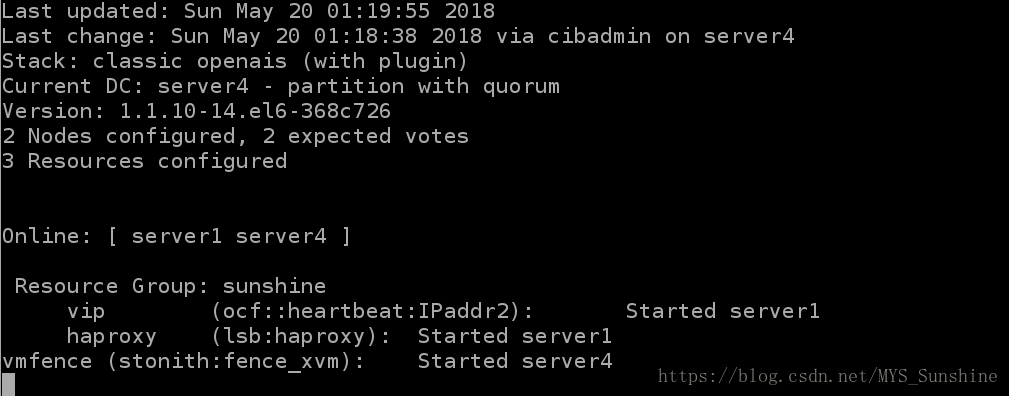
7)高可用性能测试
# 集群节点实时监控:
[root@server1 ~]# crm_mon 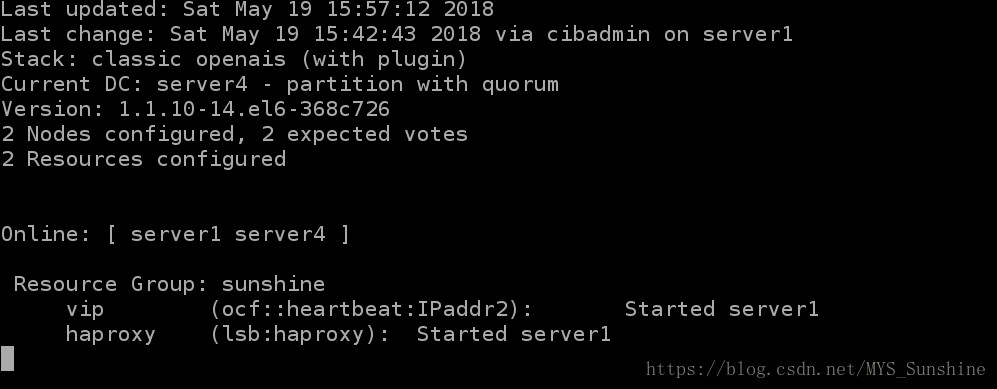
表示,vip此时在server1上,server1执行 /etc/init.d/corosync stop,其变化如下:
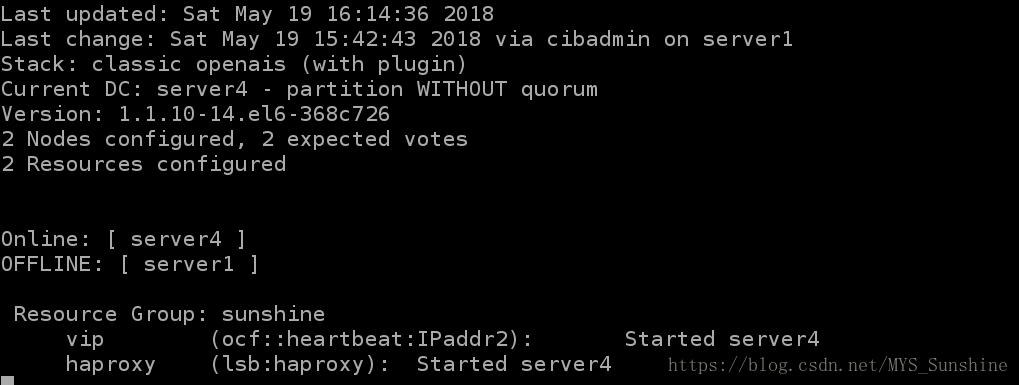
8)添加fence设备
真机:
- 安装软件fence-virtd-multicast、fence-virtd、fence-virtd-libvirt;
- fence_virtd -c编写新的fence信息
安装fence,选择工作模式”multicast”,地址”225.0.0.12”,端口”1229”,family”ipv4”,网络interface”br0”,Backend module “libvirt”;
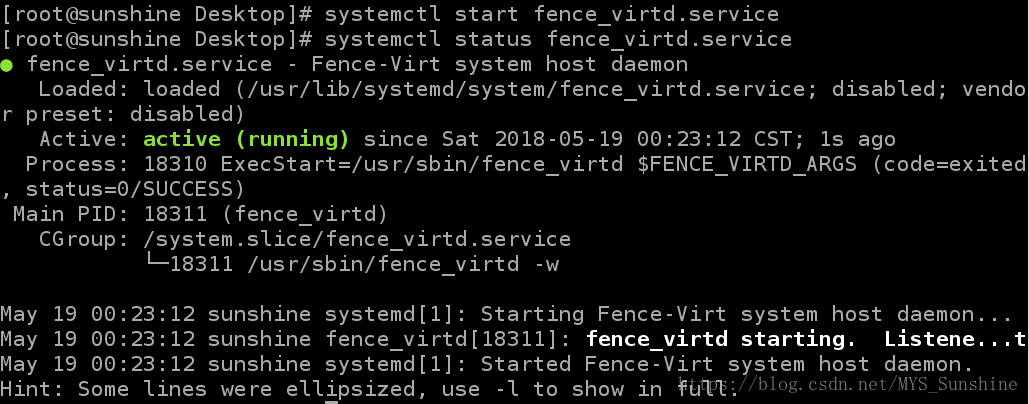
// 注:这里br0是因为虚拟服务器受主机控制的网卡是br0- 生成128位的key,并将key发送到套件集群服务器(server1,server4)的/etc/cluster目录下,可以用file命令查看这个key类型是数据
[root@sunshine ~]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1- 重新启动fence_virtd;
虚拟机:
server1和server4上:
stonith_admin -I ##检验fence,有fence_xvm就可以。这个命令用来查看主机支持的代理类型,本次使用的是fence_xvm
stonith_admin -M -a fence_xvm ##查看fence_xvm
添加fence资源,写入集群节点名和真实server的名字映射 :
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="server1:server1;server4:server4" op monitor interval=1min
crm(live)configure# property stonith-enabled=true // 开启fence功能
crm(live)configure# commit 在server1和server4上设置corosync开机自启: chkconfig corosync on
9)测试fence设备
监控显示:发现,fence设备所在节点和正在运行的节点对立