pacemaker简介
pacemaker作为linux系统高可用HA的资源管理器,位于HA集群架构中的资源管理,资源代理层,它不提供底层心跳信息传递功能。(心跳信息传递是通过corosync来处理的这个使用有兴趣的可以在稍微了解一下,其实corosync并不是心跳代理的唯一组件,可以用hearbeat等来代替)。pacemaker管理资源是通过脚本的方式来执行的。我们可以将某个服务的管理通过shell,python等脚本语言进行处理,在多个节点上启动相同的服务时,如果某个服务在某个节点上出现了单点故障那么pacemaker会通过资源管理脚本来发现服务在改节点不可用。
pacemaker只是作为HA的资源管理器,所以不要想当然理解它能够直接管控资源,如果你的资源没有做脚本配置那么对于pacemaker来说它就是不可管理的。
高可用pacemaker+corosync集群
安装
[root@server4 ~]# vim /etc/yum.repos.d/rhel-source.repo #配置高可用集群
[root@server4 ~]# yum repolist
[root@server4 ~]# yum install -y pacemaker corosync #在server1主机做相同下载的安装包
[root@server4 ~]# cd /etc/corosync/
[root@server4 corosync]# ls
[root@server4 corosync]# cp corosync.conf.example corosync.conf
[root@server4 corosync]# vim corosync.conf
[root@server4 corosync]# scp corosync.conf [email protected]:/etc/corosync/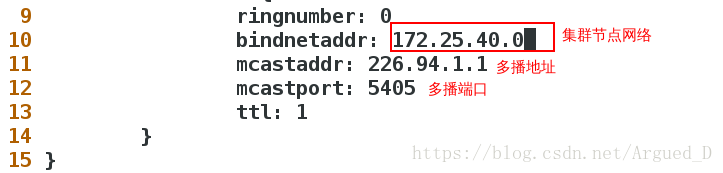

将server1和server4服务开启/etc/init.d/corosync start
[root@server4 ~]# crm_verify -VL #校验,根据校验结果解决软件依赖性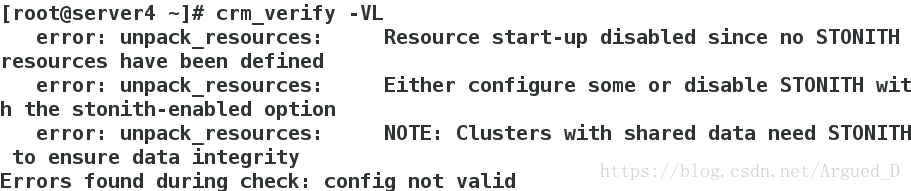
在server1和server4主机上同时下载
yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm 【server1】监控结点连接状态crm_mon
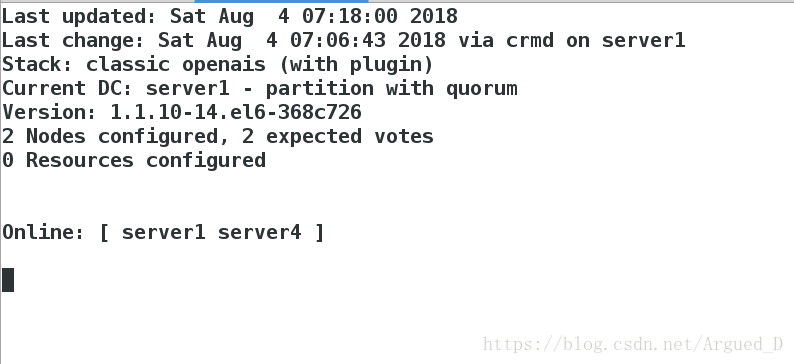
【server4】主机
[root@server4 ~]# crm #进入交互式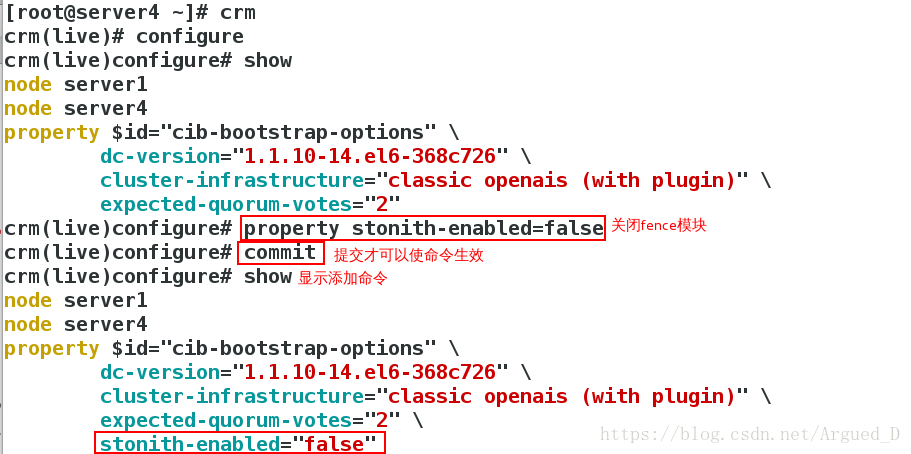

用【server1】监控:
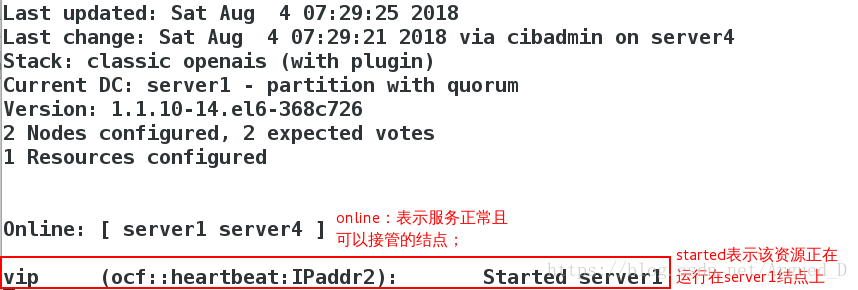
如果将【server1】主机的/etc/init.d/corosync stop
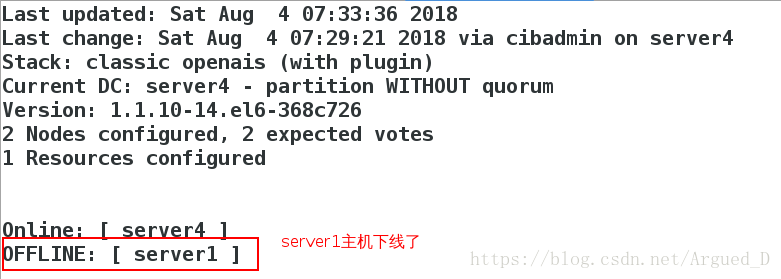
[root@server1 ~]# crm
[root@server1 ~]# /etc/init.d/corosync stop
【server4】监控:
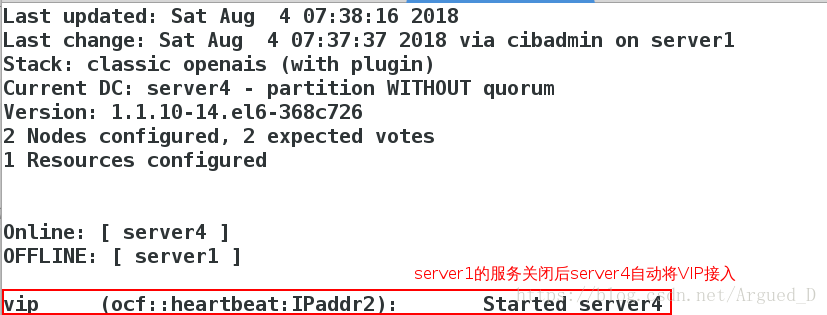
[root@server1 ~]# /etc/init.d/corosync start
[root@server1 ~]# cd rpmbuild/
[root@server1 rpmbuild]# ls
[root@server1 rpmbuild]# cd RPMS/
[root@server1 RPMS]# cd x86_64/
[root@server1 x86_64]# ls
[root@server1 x86_64]# scp haproxy-1.6.11-1.x86_64.rpm server4:【server4】主机
[root@server4 ~]# rpm -ivh haproxy-1.6.11-1.x86_64.rpm
[root@server4 ~]# /etc/init.d/haproxy start【server1】主机
[root@server1 x86_64]# cd /etc/haproxy/
[root@server1 haproxy]# ls
[root@server1 haproxy]# scp haproxy.cfg server4:/etc/haproxy/
[root@server1 haproxy]# crm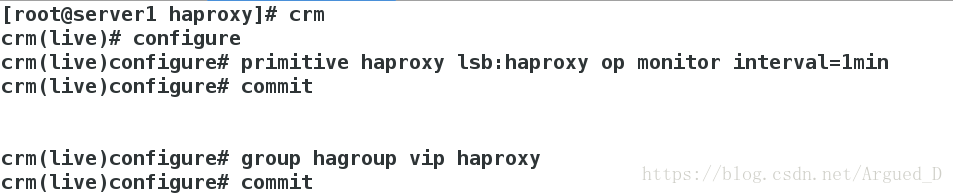
监控:
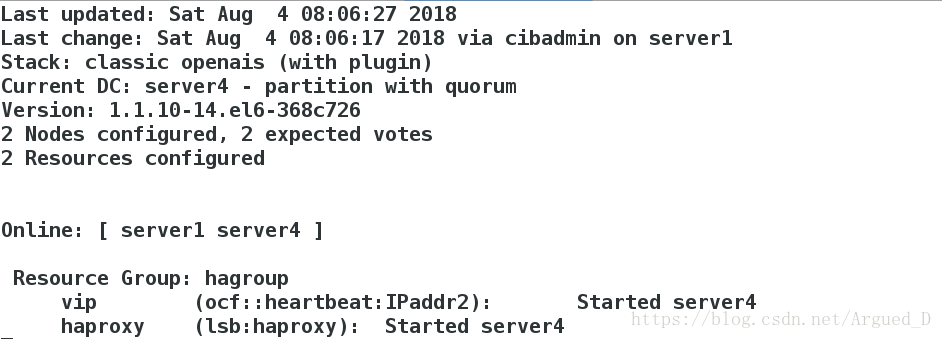
[root@server4 ~]# crm node standby #表示不接管资源,但心跳仍正常;当恢复为node时,资源不会回切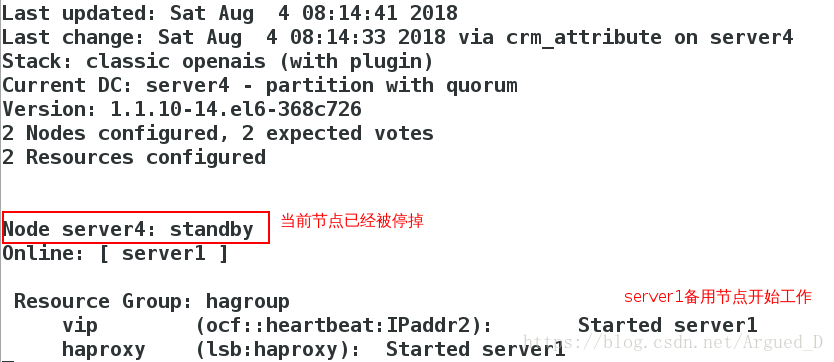
若是一个双结点集群,当有一端关掉服务时,另一结点则会自动丢弃资源,也不再接管,因为一个结点不能构成集群。
Fence机制
在server1和server4上建立/etc/cluster
[root@foundation40 ~]# systemctl start fence_virtd
[root@foundation40 cluster]# scp -r fence_xvm.key root@172.25.40.1:/etc/cluster/ #将fence的钥匙传给server1
[root@foundation40 cluster]# scp -r fence_xvm.key root@172.25.40.4:/etc/cluster/ #将fence的钥匙传给server4[root@server4 ~]# crm
crm(live)# configure
crm(live)configure# property stonith-enabled=true #开启fence机制,更改为ture表示资源会迁移
crm(live)configure# commit
[root@server4 cluster]# yum install -y fence-virt #在server1上相同下载fence-virt
[root@server4 cluster]# crm
crm(live)# configure
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="server1:test1;server4:test4" op monitor interval=1min #添加vmfence
crm(live)configure# commit
crm(live)configure# show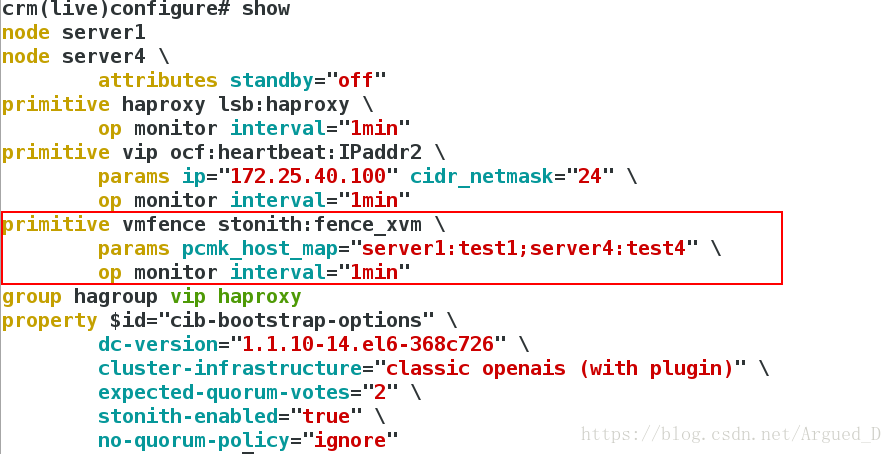
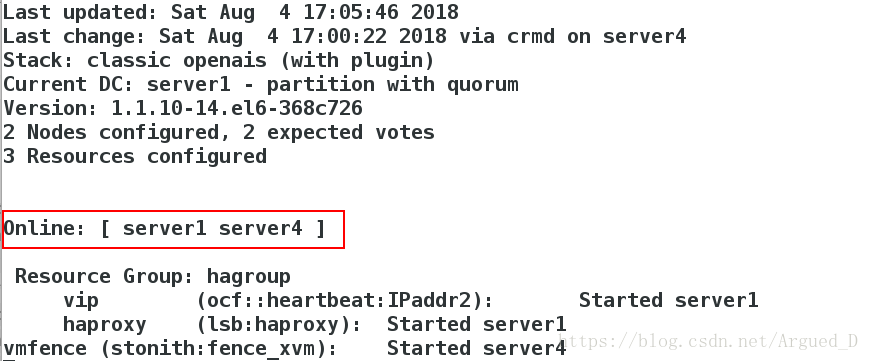
查询节点状态的变化
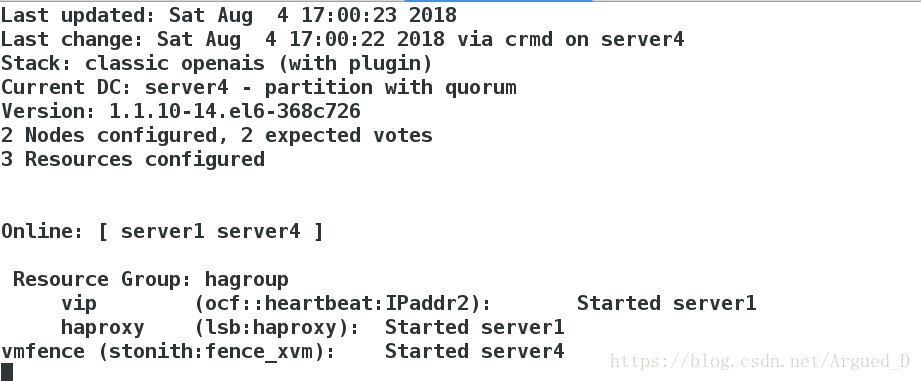
崩溃server4内核,server4自动重启
服务起在哪个节点崩溃哪个内核
[root@server4 cluster]# echo c > /proc/sysrq-trigger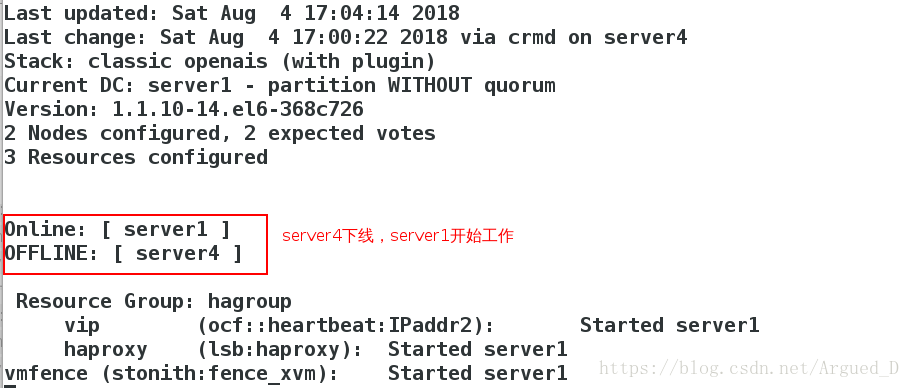
启动server4上corosync服务
[root@server4 ~]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]