Pacemaker是一个集群资源管理器。它利用集群基础构件(OpenAIS、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。
pacemaker和corosync,后者用于心跳检测,前者用于资源转移。两个结合起来使用,可以实现对高可用架构的自动管理。 心跳检测是用来检测服务器是否还在提供服务,只要出现异常不能提供服务了,就认为它挂掉了。 当检测出服务器挂掉之后,就要对服务资源进行转移。
CoroSync是运行于心跳曾的开源软件。 PaceMaker是运行于资源转移层的开源软件。
corosync是集群框架引擎程序,pacemaker是高可用集群资源管理器,crmsh是pacemaker的命令行工具。
一.无fence设备的高可用集群实现:
1.在server1和server4(两个节点,相互感应彼此的服务开启状态,实现双机热备)上安装pacemaker和corosync
yum install pacemaker yum install corosync2.修改配置文件
cd /etc/corosync/
cp corosync.conf.example corosync.conf # 将配置文件的模版拷到配置文件的正确目录
vim corosync.conf
# Please read the corosync.conf.5 manual page
compatibility: whitetank
logging { # 配置日志存储的部分
fileline: off
to_stderr: no
to_logfile: yes
to_syslog: yes
logfile: /var/log/cluster/corosync.log # 日志文件的地点
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
service { #启动corosync完成后,就启动pacemaker。
name: pacemaker # 服务名称是pacemaker
ver: 0
}
totem {
version: 2
secauth: off
threads: 0 #并发开启的线程数,一般单核cpu修改下即可。多核cpu不需要修改
interface {
ringnumber: 0
bindnetaddr: 172.25.1.0 # 集群工作的网段
mcastaddr: 226.94.1.2 # 多播ip,集群节点间通讯使用这个多播地址,两个节点的要保持一致
mcastport: 5405 # 多播端口号,保持默认即可
ttl: 1
}
}3.将修改好的节点发送给另一个节点server4(集群节点之间要保持一致)
scp corosync.conf root@172.25.1.1:/etc/corosync/4.在servr1和server4上打开corosync服务
/etc/init.d/corosync start5.在两个节点处查看日志,看是否有错误
6.在server1和server4上安装依赖性软件
yum install crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm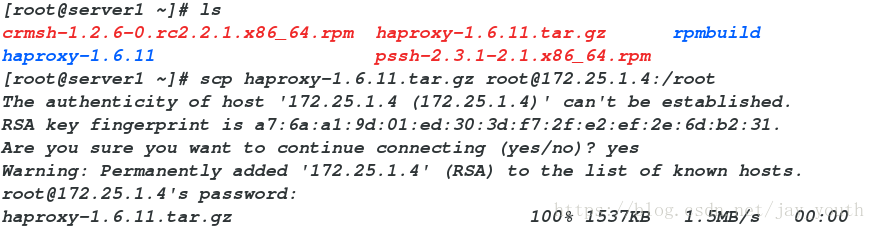
6.两个节点均crm_verify -VL 校验

7.在server4上添加集群中节点配置信息:(可以类比前几篇博客中的RHCS套件实现高可用中资源服务的添加)
crm # CRM:cluster resource manager(集群资源管理)
crm(live)# configure # 配置,设定
crm(live)configure# show # 显示集群中的全部信息
node server1 # 高可用集群中的两个节点
node server4
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2"
crm(live)configure# property stonith-enabled=false
# Stonith 即shoot the other node in the head使Heartbeat软件包的一部分,该组件允许系统自动地复位一个失败的服务器使用连接到一个健康的服务器的遥远电源设备。Stonith设备是一种能够自动关闭电源来响应软件命令的设备
crm(live)configure# commit # 提交上边设置
crm(live)configure# show # 查看配置所有信息
node server1
node server4
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false"
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.1.100 cidr_netmask=24 op monitor interval=1min
# 定义集群的虚拟ip和监控时间
crm(live)configure# commit # 提交
crm(live)# configure
crm(live)configure# primitive haporxy lsb:haproxy op monitor interval=1min
crm(live)configure# property no-quorum-policy=ignore
# 关闭集群对节点数量的检查,节点server1如果故障,节点server4收不到心跳请求,直接接管程序,保证正常运行,不至于一个节点崩掉而使整个集群崩掉
crm(live)configure# commit # 提交
crm(live)configure# group hagroup vip #添加资源组
crm(live)configure# group hagroup vip haporxy
crm(live)configure# commit
crm(live)configure# exit
bye7.在server1和server4:
rpm -ivh haproxy-1.6.11-1.x86_64.rpm
这个rpm包在/root/haproxy-1.6.11/rpmbuild/RPMS/x86_64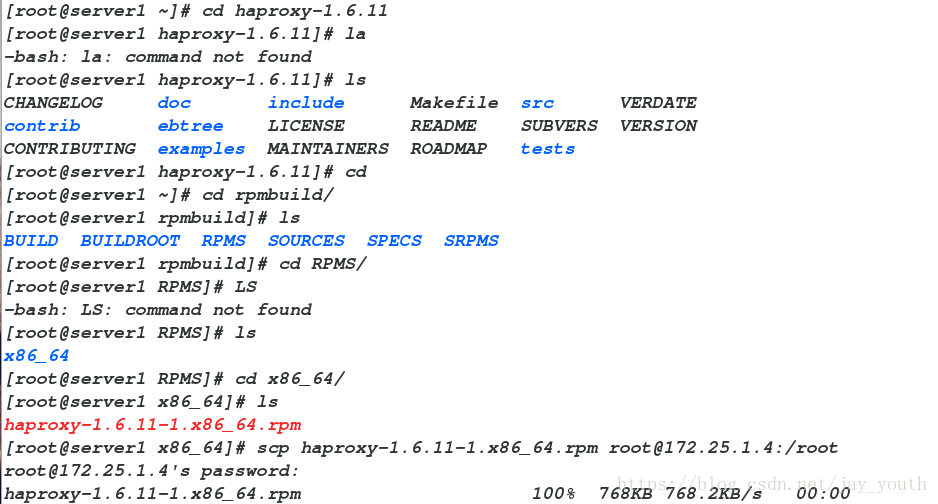
8.两端均打开haproxy
/etc/init.d/haproxy start9.利用crm_mon监控命令查看集群中的服务情况
Online: [ server1 server4 ] # 在线的后端服务器
Resource Group: nginxgroup
vip (ocf::heartbeat:IPaddr2): Started server1
nginx (lsb:nginx): Started server1 # 服务运行所在的服务器
- 在server1或server4停止服务。在另一端用监控命令查看,发现已经下线。
crm node standby (下线某个节点)
crm node online(让某个节点上线)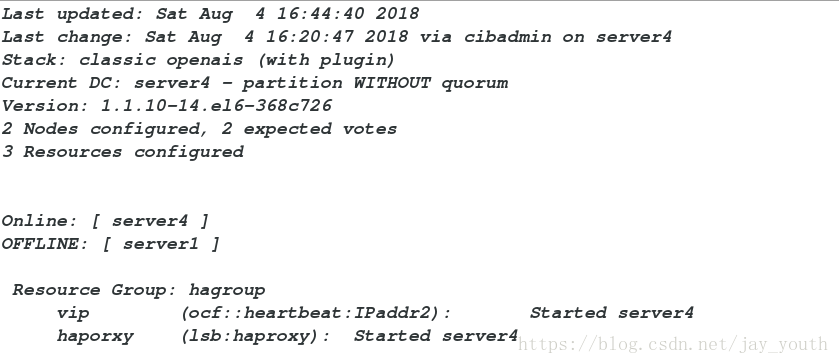
crm管理工具:
cib #cib管理模块
resource #所有的资源都在这个子命令后定义:cleanup #清理资源状态;refresh LRM本地资源管理更新CIB(集群信息库)
configure #编辑集群配置信息:show #显示集群信息库;edit #编辑集群信息库对象(vim模式下编辑);delete删除CIB对象;primitive #定义资源;monitor #对一个资源添加监控选项(如超时时间,启动失败后的操作);group #定义一个组类型(将多个资源整合在一起)
node 集群节点管理子命令:status #以xml格式显示节点状态信息;show #命令行格式显示节点状态信息;standby模拟指定节点离线(standby在后面必须的FQDN);online #节点重新上线;fence #隔离节点;delete #删除 一个节点
options #用户优先级
二.含有fence设备的高可用集群实现:
在server1和sever4上查看是否含有key文件
1.在server1和server4上执行命令stonith_admin -I,查看是否有fence代理:fence_xvm,如果没有自己安装fence-virt-0.2.3-15.el6.x86_64
yum install fence-virt-0.2.3-15.el6.x86_642.查看fence设备的详细信息
stonith_admin -M -a fence_xvm3.打开服务corosync
/etc/init.d/corosync start4.向集群中添加服务
crm
crm(live)# configure
crm(live)configure# show
node server1
node server4 \
attributes standby="off"
primitive haporxy lsb:haproxy \
op monitor interval="1min"
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.1.100" cidr_netmask="24" \
op monitor interval="1min"
primitive vmfence stonith:fence_xvm \
params pcmk_host_map="server1:test1;server2:test2" \
op monitor interval="1min"
group hagroup vip haporxy
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="true" \
no-quorum-policy="ignore"
在server4上添加集群服务信息(其实在一台后端服务器可以添加所有的服务配置,这样做只是为了说明这两个节点之间是同步的,在服务提交后可以同步两者之间的信息)
crm
primitive vmfence stonith:fence_xvm params pcmk_host_map="server1:test1;server4:test4" op monitor interval=1min
# 添加fence服务处理故障的节点server1:test1 server1是主机名,test1是真实的虚拟机名称
property stonith-enabled=true # 添加fence设备
commit # 提交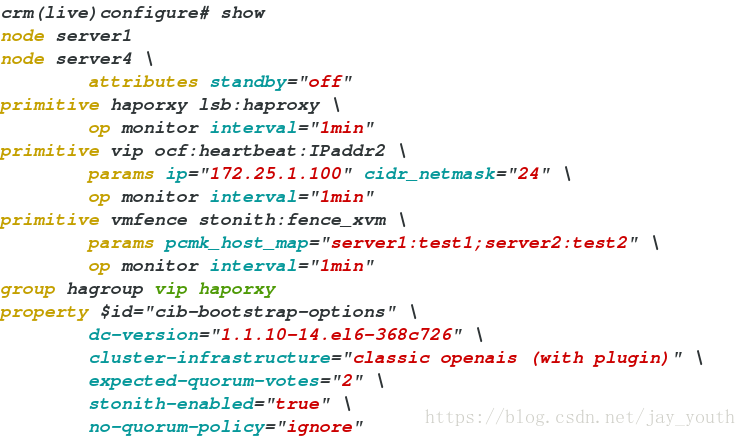
5.crm_mon查看监控,应该是服务和fence不在一个节点。

当一台电脑奔溃时,fence和服务立即迁移到良好的主机,坏的主机立即重启
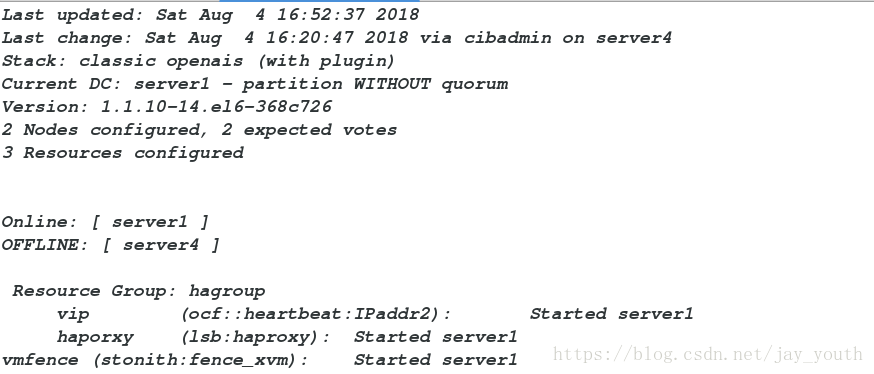
server4立即开始重启,恢复后,fence迁移到server4上….