一直坚持做自己喜欢的事,特别是在没有任何利益驱动的情况下还在坚持是很难的一件事,幸好今天的我还没放弃!-致自己
广告位:源码地址 https://github.com/zzubqh/TextCategorization
=============矫情的分割线==============
写在最前面:
1. 程序中用到的所有包,numpy,yaml, jieba请先自行pip安装,比如:
pip install -i https://pypi.doubanio.com/simple/ pyyaml
2. 机器配置,其实代码是在原有的代码上改的,之前为了节省存储空间(主要是我的本本不给力)用的是字典方式存储,这次直接改成了矩阵,所以运行代码的时候需要至少16G的内存,CPU尽量的好点,这里的代码暂时不需要GPU支持
3. 关于数据集,我忘在哪下载的了,里面总共10个类,分别是军事,历史,人文,经济等(训练集里的标签是C0000XX,这些都是我这个AI给贴上的标签)训练集总共8036个文件,抽取70%用于训练,剩下的30%用于验证。数据集下载地址:http://pan.baidu.com/s/1c99UME
4. 程序中的文件夹组织
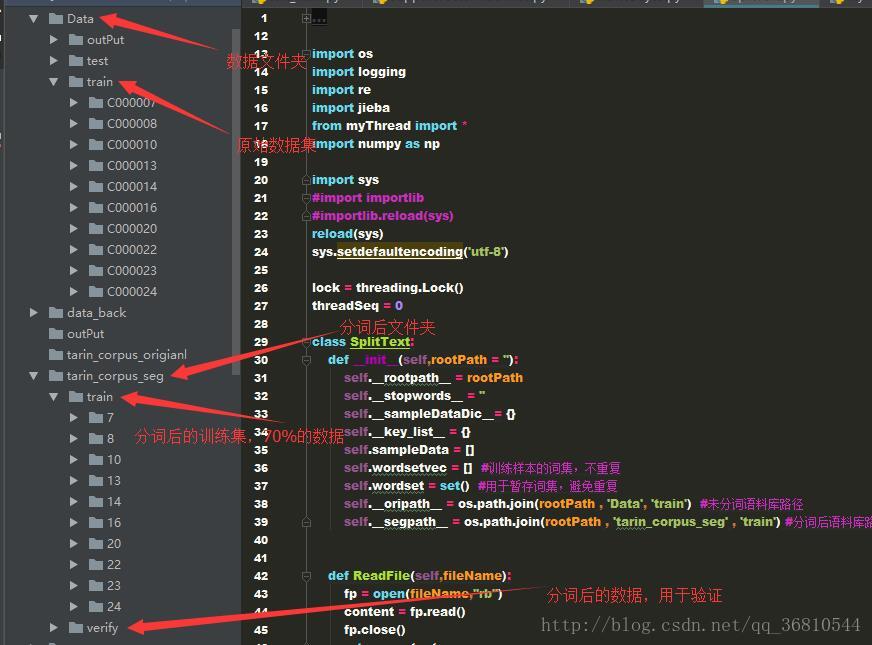
5. 文本特征提取采用TF-IDF(后续详细写),分类算法采用朴素贝叶斯。分类正确率总体达到82.5%,之所以这么低主要是因为有个类别‘23’下的文章连我都不知道应该归到什么下面,乱七八糟的,对这个类的正确率只有3%,各类的正确率如下:
2017-11-24 10:17:16,651 - main - INFO - the class 0 rate is 81.2765957447%
2017-11-24 10:17:16,651 - main - INFO - the class 1 rate is 72.4324324324%
2017-11-24 10:17:16,651 - main - INFO - the class 2 rate is 97.7941176471%
2017-11-24 10:17:16,651 - main - INFO - the class 3 rate is 3.42465753425%
2017-11-24 10:17:16,651 - main - INFO - the class 4 rate is 84.4106463878%
2017-11-24 10:17:16,651 - main - INFO - the class 5 rate is 92.6829268293%
2017-11-24 10:17:16,651 - main - INFO - the class 6 rate is 70.4081632653%
2017-11-24 10:17:16,651 - main - INFO - the class 7 rate is 87.8676470588%
2017-11-24 10:17:16,651 - main - INFO - the class 8 rate is 99.4029850746%
2017-11-24 10:17:16,651 - main - INFO - the class 9 rate is 89.3023255814%
2017-11-24 10:17:16,653 - main - INFO - the total correct rate is 82.5436408978%
注:这里的0,1,2……只是序号不是类别,具体对应类别请参考‘Data->output’下的输出文件‘pridictLable.tx’预测输出,‘trueLable.txt’对应的正确类别标签
6.最后尝试了下word2vec文本特征,分类结果很不理想,应该是我对词向量的了解不深,继续探索中
7.文章和程序里的错误或需要改进的地方请各位指出,感激不尽!
===============================我是可爱的分割线====================
一、从词频统计说起
计算机完成分类任务首先需要有我们的计算机能处理的数据,所以需要一个方法把文本文件转换成可以计算的数据。首先能想到的肯定就是统计每个有意义的词在文本中出现的次数作为特征,比如“汽车”肯定在关于车的文章中出现的次数多于娱乐类的文章,依此类推。但是,很不幸 比如‘我’,‘你’‘的’……这些词出现的频率会更高,而且 几乎在每种类型的文章里都会大量出现,所以我们还需要一份‘停用词’数据库,最开始统计的时候把这些词全部去除。网上有现成的停用词表,直接下就好了(这里是我用的 http://pan.baidu.com/s/1i5mvijN)
现在从词到数字的转换有了,但是如何用一个矩阵来表示一篇文章呢?想把文章中的词表示成向量形式有两种方式,一种是统计样本集中的所有词,然后将这些词当做一个行向量,作为每篇文章的特征,然后分别统计文章中的词出现的次数(也可以统计是否出现)这就是词袋模型,比如样本集中的所有词记为[‘a’,’i’,’am’,’you’,’boy’,’gril’],文章1中内容为 i am a boy,则文章1就可表示成[1,1,1,0,1,0]。这样表示有个缺点,一般样本集都会很大,维数几十万到几百万不等,这样表示出来的矩阵就是个稀疏矩阵,造成很大的存储空间浪费,或者用字典来存储。另外一种就是词向量模型,因为词袋模型的缺点很明显,一种是前面说的数据稀疏,然后还有一种就是这种表示只是表达了单个词的特征并未考虑词与词之间的上下文关系,如果能将上下文关系考虑进去对文本分类应该有很大的好处,最后一个,词袋模型表示出来的特征矩阵都太大了,很难利用如今发展很好的深度神经网络来处理。于是,出现了词向量模型(word2vec),简单来说就是一个利用神经网络对一个样本集中的词进行语言建模,只是这个神经网络的输出与一个巨大的霍夫曼树相关联,这样在语言建模完成的时候就得到了一个有用的副产品:词向量。每个词具有相同的维数,比如100或400等(这个是训练的时候人为指定的)具体可以参考 https://www.cnblogs.com/iloveai/p/word2vec.html 作者讲的很清楚,比我要强的多!使用的话,可以直接 pip install gensim, 这个是谷歌开源的一个word2vec项目,在python下直接调用。可以很方便的得到两个词的相似度。至于如何用到文本分类中,我还在研究中。本文的分类还是采用词袋模型!
二、分词
既然知道怎么去表示一篇文章了,那么首先需要把一篇文章变成一个个的词,这是整个程序的第一步。可以采用jieba来完成。因为每个分词任务彼此没有任何交互,所以就用多线程直接处理了。
#分词的线程处理函数
def __splitWordswithjieba__(self,class_dir_path,seg_class_path):
file_list = os.listdir(class_dir_path)
for file_path in file_list:
filename = class_dir_path + file_path
content = self.ReadFile(filename).strip()
content = content.replace("\r\n","").strip()
content_seg = jieba.cut(content)
self.SaveFile(seg_class_path + file_path," ".join(content_seg))
def SplitWords(self,inputpath='',outpath=''):
if inputpath == '':
inputpath = self.__oripath__
if outpath == '':
outpath = self.__segpath__
catelist = os.listdir(self.__oripath__)
cateNum = range(len(catelist))
threads = []
for dir in catelist:
ori_class_path = os.path.join(inputpath,dir)
seg_class_path = os.path.join(outpath , dir )
if not os.path.exists(seg_class_path):
os.makedirs(seg_class_path)
t = MyThread(self.__splitWordswithjieba__,(ori_class_path,seg_class_path),self.__splitWordswithjieba__.__name__)
threads.append(t)
for index in cateNum:
threads[index].start()
for index in cateNum:
threads[index].join()分词后的文件,还需要有一步就是处理停用词和去重
#filter的线程处理函数,去掉filename中的停用词
def __dofilder__(self,class_dir_path):
logger = logging.getLogger(__name__)
global threadSeq
threadSeq += 1
localseq = threadSeq
logger.info( 'thread ' + str(threadSeq) + 'start')
file_list = os.listdir(class_dir_path)
pattern = re.compile(r'^\w+$') #验证任意数字、字母、下划线组成的模式
for file_path in file_list:
filename = os.path.join(class_dir_path , file_path)
content = self.ReadFile(filename)
content = content.decode('utf-8')
wordslist = content.split()
newcontent = ''
for word in wordslist:
if self.__stopwords__.find(word.encode('utf-8')) != -1:
continue
elif pattern.match(word.decode('utf-8')) != None:
continue
if lock.acquire():
self.wordset.add(word)
lock.release()
newcontent = newcontent + ' ' + word
self.SaveFile(filename,newcontent)
logger.info( 'thread ' + str(localseq) + ' end')
#用中文停用词对分词后的文件做过滤
def Filter(self,inputpath = ''):
if inputpath == '':
inputpath = os.path.join(self.__segpath__, "train")
#读取停用词
stop_words_path = os.path.join(self.__rootpath__, "stopwords.txt")
stop_words = self.ReadFile(stop_words_path)
stop_words = stop_words.replace("\r\n","").strip()
self.__stopwords__ = stop_words.decode('utf-8')
#起线程开始处理已分词的文件
catelist = os.listdir(inputpath)
cateNum = range(len(catelist))
threads = []
for dir in catelist:
seg_class_path = os.path.join(inputpath , dir)
t = MyThread(self.__dofilder__,(seg_class_path,),self.__dofilder__.__name__)
threads.append(t)
for index in cateNum:
threads[index].start()
for index in cateNum:
threads[index].join()最后写一个高层函数,用于生成我们需要的词袋
def CreateDataSet(self,wordset_fileName):
self.SplitWords()
self.Filter()
#创建词集,去重
content = ''
for word in self.wordset:
content = content + ' ' + word
self.wordsetvec = content.split()
self.SaveFile(wordset_fileName,content)这样样本集的词袋就有了,下一步开始利用TF-IDF来计算每篇文章的特征向量