多标签文本分类
多标签文本分类简介
NLP(自然语言处理),即让计算机去理解人类的自然语言(文本、语音等),进而完成各种各样的任务(NER、文本分类、机器翻译、阅读理解、问答系统、智能对话、搜索推荐系统等等),被誉为人工智能皇冠上的明珠。自然语言处理任务总结可以分为:自然语言生成和自然语言理解。
文本分类是NLP的一项基础任务,属于自然语言理解,旨在对于给定文本文档,自动地分配正确的标签。文本分类在许多方面的应用很多,例如:信息检索、自然语言推理、情感分析、问答等。文本分类任务从分类目的上可以划分为三类:二元分类、多类别分类以及多标签分类。
二元分类,应用最多的是情感分析,即对于特定文本,分析出文本的情感导向(喜欢/厌恶)。对于该情况,通常来说,分类器只需输出正类/负类的标签即可。另外,垃圾邮件分类,也是二元分类的一种。
多类别分类,相比较于二元分类,该情况通常需要在多种类别(>2)的标签集中选出正确的标签分配给特定文本。另外,该情况下,每个文本也是只有一个标签。
多标签分类,不同于多类别分类,多标签分类的总标签集合大,而且每个文本都包含多种标签,即将多个标签分配给特定文本。由于不同文本分配的标签集不同,给分类任务带来一定程度的困难。另外,当总的标签集合数目特别大的时候,这种情况可以算作为一种新的多标签分类任务,即极端多标签文本分类(Extreme multi-label text classification (XMTC))。
文本分类任务可以用传统机器学习的方法来做,也可以用深度学习的方法来做。
基于机器学习:文本分类算法综述(多种传统机器学习算法)
基于深度学习:基于深度学习的文本分类综述(多种深度学习算法模型)
三种神经网络结构
本人的主要研究方向为基于深度学习的多标签文本分类,在此给出用于文本分类的三种神经网络结构:CNN、RNN、Transformer,也可以说是四种(算上NN)。
NN,传统的神经网络模型,例如fasttext。
CNN,卷积神经网络模型。将图像界流行的网络结构用于文本处理,鼻祖为TextCNN。之后基于CNN,又出现了CharCNN、VDCNN等等。
RNN,循环神经网络模型。RNN用于文本处理,有天然的优势,但普通RNN会有梯度爆炸/梯度消失的问题,所以有了改进的RNN模型:LSTM、GRU。LSTM/GRU是基于门的概念来解决RNN网络的梯度问题。基于上下文的概念,又有Bi-LSTM/Bi-GRU等。RNN\LSTM\GRU
Transformer,17年谷歌提出的新型的网络结构,是比CNN/RNN更为强大的特征提取器。Transformer的关键点是自注意力机制。Transformer原理详解
网络模型
在此给出目前看过的网络模型。
文本分类网络模型
1.RNN网络
RNN网络用于文本分类,通常情况下是最后时刻输出类别信息。应用LSTM/GRU等,另外Bi-RNN可以根据上下文的信息进行分类。
多任务TextRNN:多任务学习。由于传统的RNN网络文本分类任务都是单任务学习,但多个相关的任务共同学习可以对主任务产生很好的效果,所以作者提出了三种多任务学习的网络。模型一:统一层体系结构。即每个任务共享一层LSTM结构、共享词向量嵌入层,但有各自的词向量。模型二:耦合层架构。即每个任务有各自的词向量嵌入层和LSTM结构层,但每个任务的LSTM通过链接可以共享信息。模型三:共享层架构。即每个任务采用双向LSTM结构,但中间的一层LSTM结构为两者共用,有各自的词向量。该方法有很好的效果。出自论文《Recurrent Neural Network for Text Classification with Multi-Task Lerning》。多任务TextRNN网络结构图:

2.CNN网络
TextCNN,出自论文《Convolutional Neural Networks for Sentence Classification》,是首次将CNN网络用于文本分类,并且取得了很好的效果。作者提出TextCNN来进行文本分类。针对一句话可以利用CNN进行一层卷积(卷积核宽度与词向量维度相同,高度可以自行设置),得到不同维度的特征向量;利用1-Max-pooling操作(抽取特征向量的最大值)重新拼接成特征向量,从而得到新的最终的特征向量;在全连接层之前采用dropout算法来防止过拟合;全连接层的最终层采用softmax函数,输出每个类的概率,进而进行分类。其网络结构图:
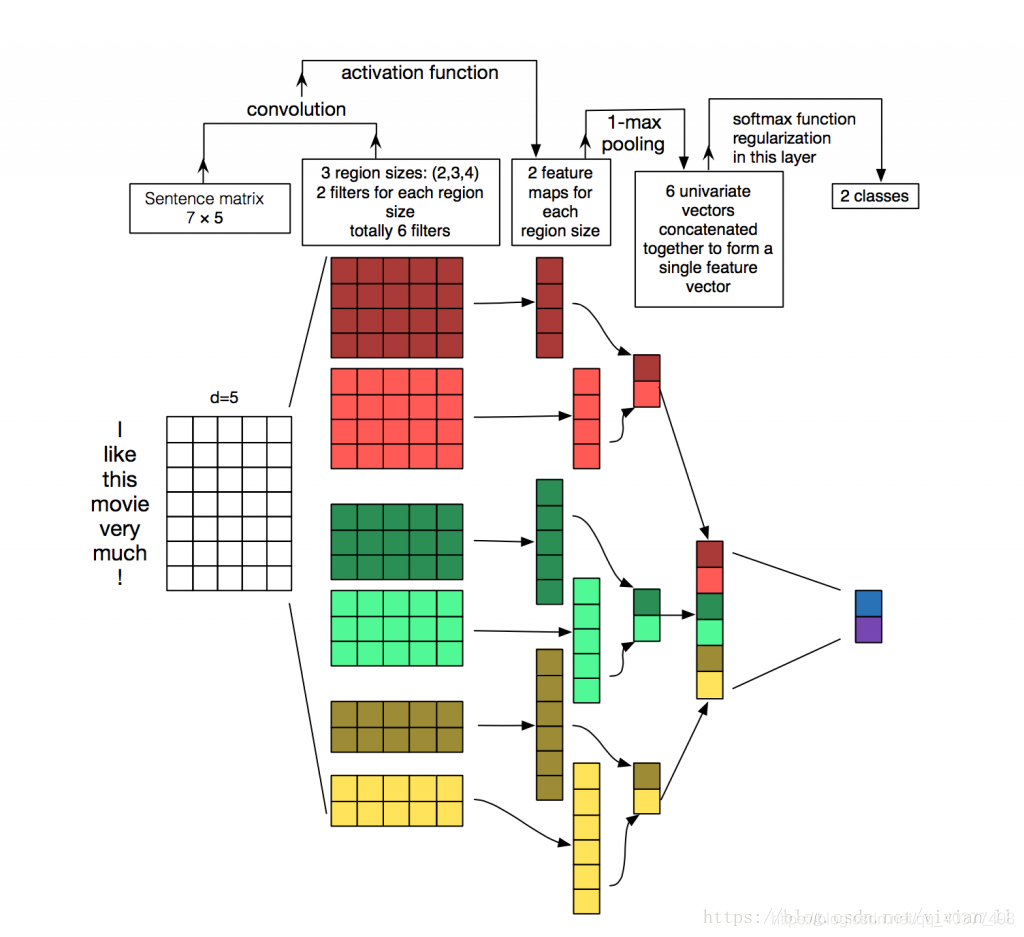
CharCnn,出自论文《character-level-convolutional-networks-for-text-classification》,通常我们在处理文本时都是以词为最小粒度进行处理的,但在该论文中,作者将字符定义为最小粒度(英文:字母、中文:字,还有字符、数字等),这样做的好处就是不需要考虑句子的结构以及词义,在微博/twitter等社交媒体上的评论使用该方法进行文本分析比较好(因为社交话语常常体现不出句式等,还有网络用语表达的意思并不是字面上的意思)。其网络结构:
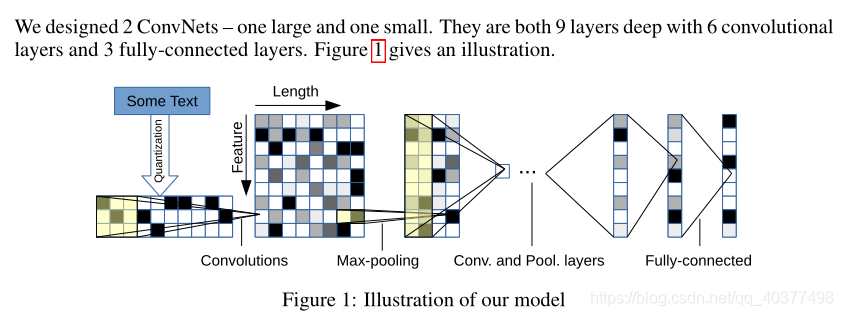
VDCNN,出自论文《Very Deep Convolutional Networks for Text Classification》,作者首次将CNN网络加深,用于文本分类。作者分别采用网络深度为9层、17层、29层、49层的CNN网络,以字符为最小粒度。
待续》》:自然语言处理中还有一个很重要的机制,即注意力机制,将注意力机制与RNN/CNN网络相结合可以有很好的效果。所谓注意力,就是专注于局部的特殊信息。
基于可利用上下文信息的RNN(Bi-RNN)。
另外基于transformer/BERT的文本分类模型。
多标签文本分类网络模型
在此只给出基于神经网络的模型,关于传统机器学习方法的模型,可以在论文《A Review on Multi-Label Learning Algorithms》中查看。
BP-MLL,出自论文《Multilabel Neural Networks with Applications to Functional Genomics and Text Categorization》,该篇论文是首次将神经网络用于多标签文本分类,相比较于传统的机器学习方法,取得了很好的效果。论文提出BP-MLL神经网络结构,改进了传统单标签学习的全局误差函数,以便适应多标签学习的特殊性,讨论了该网络的计算复杂度,并且提出了阈值函数的求解方式来对标签排序,另外提出了用于多标签学习的五种评估方法(hamming loss、one-error、coverage、ranking loss、averge precision)。其网络结构:

作者改进了损失函数,使其适合多标签文本分类的情况:

该损失函数的意思是:使正确分类的标签集合比错误分类的标签集合的差异更大。
优化BP-MLL:出自论文《Large-scale Multi-label Text Classification Revisiting Neural Networks》,针对大规模多标签文本分类,作者提出了一种利用各种优化的单隐层神经网络。作者采用的神经网络结构与BP-MLL相同,但隐层采用的激活函数为ReLU,同时利用了随机梯度下降算法(SGD)、自适应学习率方案等,在输出层采用了dropout思想,该网络采用交叉熵来训练网络(减少了模型计算复杂度),训练相应的阈值预测器。评估方法与BP-MLL相同。该论文的创新在使用了各种先进的优化技术,并且作者采用的损失函数为:交叉熵损失函数。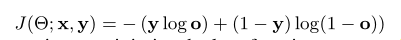
词向量嵌入+CNN/GRU,出自论文《Large Scale Multi-label Text Classification with Semantic Word Vectors》。由于13年word2vec的出现,词向量嵌入成为主流的文本向量输入方式。该论文引入词向量,使用CNN和GRU来进行多标签文本分类。
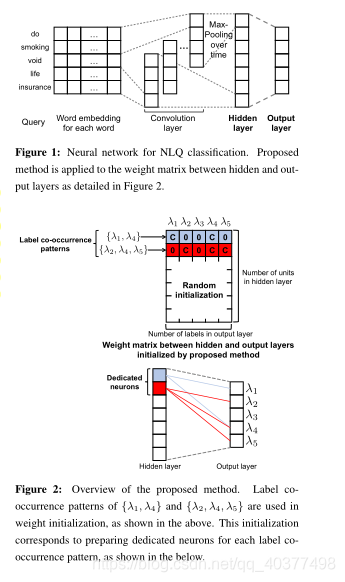
标签共现初始化+CNN,出自论文《Improved Neural Network-based Multi-label Classification with Better Initialization Leveraging Label Co-occurrence》,标签之间是有相关性的,一种标签的分配,通常与于其相关的标签同时分配到给定文本,作者在隐层的权重初始化中加入了标签共现的权重。作者首先观察特定的标签共现模式出现的次数,再决定隐层单元用于标签共现初始化的行数。作者采用CNN网络。其网络结构图:
CRNN-MLTC,出自论文《Ensemble Application of Convolutional and Recurrent Neural Networks for Multi-Label Text Categorization》,C-RNN的集成应用。作者首先训练词向量,将该词向量送入CNN网络中,经过卷积核卷积、ReLu转换、1-max-pooling操作,最终输入提取后的特征序列;将该特征序列送入RNN中(输入的特征序列增添了一附加项),在每一个时间点都会对标签进行预测,输出当前时间点最大概率的标签,直至输出所有标签。作者采用了Adam的更新方法而不是SGD,对所有权重采用L2正则化,在CNN中使用dropout操作。采用交叉熵损失函数。另外,标签的生产采用的是序列生成方式,前一时刻生成的标签会作为参数输入至下一时刻,这样体现了标签之间的相关性。
现有的多标签文本分类方法在提取局部语义信息和建立标签相关性模型方面存在不足。本文提出了一种基于卷积神经网络(CNN)和递归神经网络(RNN)的方法,该方法能够有效地表示文本特征,并以合理的计算复杂度对高阶标签相关性进行建模。我们的评估结果显示,所提出的方法的效能受训练集大小的影响。如果数据太小,系统可能会出现过度拟合。然而,当在大规模数据集上进行训练时,所提出的模型可以达到最先进的性能。其网络结构图:
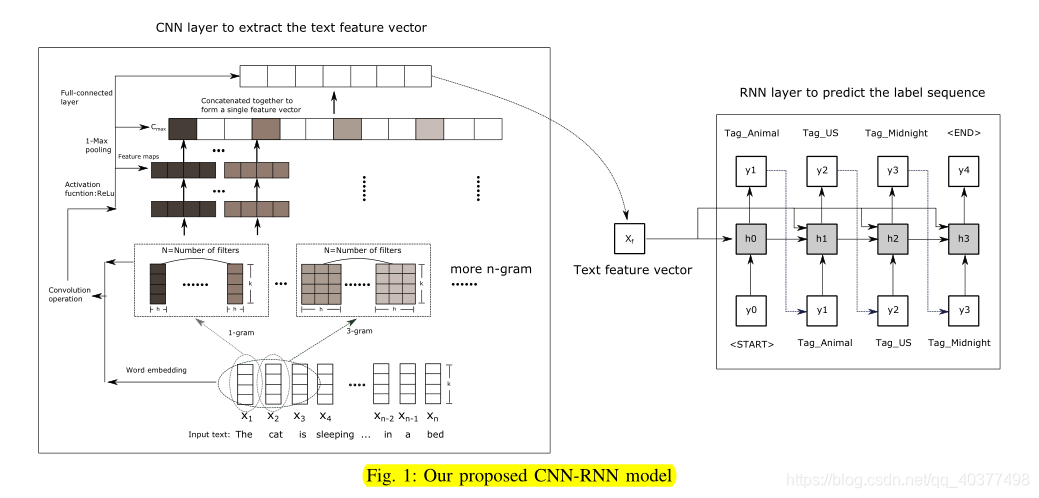
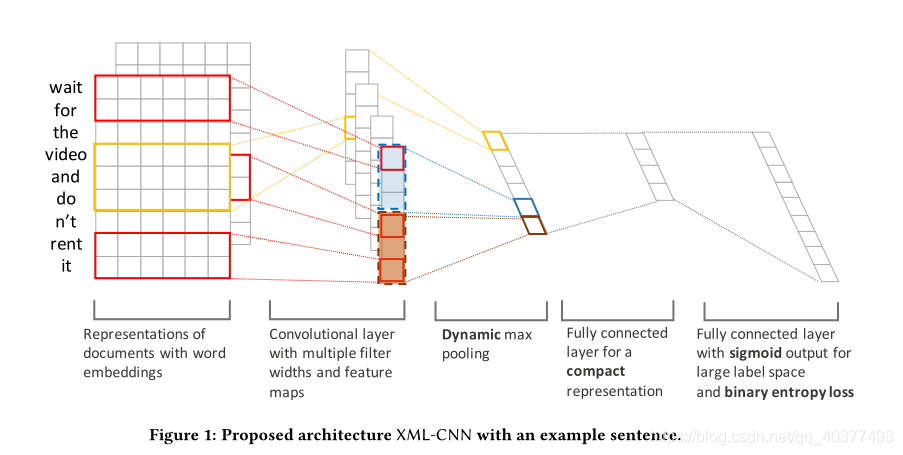
XML-CNN,出自论文《Deep Learning for Extreme Multi-label Text Classification》,对标签数特大情况下的多标签文本分类的改进。当数据集的标签数特大时(上万)时,计算量较大,作者改进了TEXTCNN提出XML-CNN.作者是基于TEXTCNN网络结构进行改进。首先作者在池化操作时采用了动态池化的方式,动态池化使每个C包含p维的特征,这样即包含了特征向量也包含了位置信息;其次作者采用了二元交叉熵损失函数;最后作者在全连接层增加了一隐层,将高维标签映射到低维,来减少计算量并增加执行效率。其网络结构图:
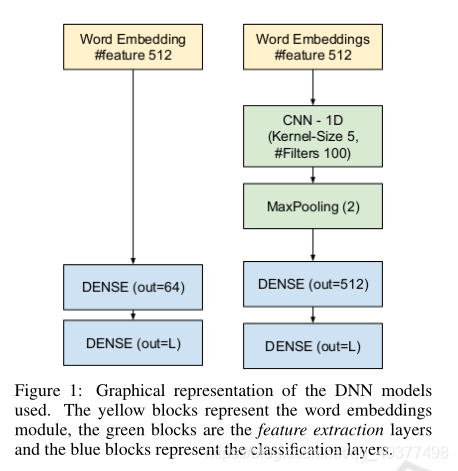
Dense/CNN-Dense,出自论文《Deep Convolution Neural Network for Extreme Multi-label Text Classification》,针对极端情况下多标签文本分类的性能分析。作者选用两种网络结构(全连接网络/CNN网络)。作者将标签集合的数量进行分配(从十到万不等)有5类。利用从PubMed库中提取的大数据训练源,分析了不同SGD函数训练超参数的影响,在每个样本的类别数和平均标签数不断增加的情况下,分析了网络的性能和行为。作者对SGD超参数与数据集复杂度之间的联系进行了初步的实证评估,对所考虑问题的学习率、动量和批量大小的性能和最佳设置进行了概述。其网络结构图:
HLSE(层次化标签+CNN),出自论文《Deep neural network for hierarchical extreme multi-label text classification》,多标签文本分类最大的难点在于标签之间的层次性,该论文分析了一种用于文本分类的深度学习结构,在定义层次化标签集时,考虑了极端的多类多标签文本分类问题。本文提出了一种用于规范化数据标签的分层标签集扩展(HLSE)方法,并分析了显式地结合语法和句法特征的不同单词嵌入(WE)模型的影响。网络结构方面,作者采用了2层卷积神经网络,使用了不同的词向量嵌入方式。
HLSE:是基于树的方式,对于已经分类的标签,运用HLSE算法可以搜寻到该标签的上级。
其网络结构:

**待续》》**多标签文本分类的难点在于标签之间的层次性和标签集合特大的情况。
采用注意力机制的多标签文本分类。
基于生成标签序列的方式(SGM)
双向RNN。
基于transformer的。
多标签文本分类推荐论文:推荐阅读论文