文章目录
一、前期工作
1. 设置GPU
2. 导入预处理词库类
二、导入预处理词库类
三、参数设定
四、创建模型
五、训练模型函数
六、测试模型函数
七、训练模型与预测
今天给大家带来一个简单的中文新闻分类模型,利用TextCNN模型进行训练,TextCNN的主要流程是:获取文本的局部特征:通过不同的卷积核尺寸来提取文本的N-Gram信息,然后通过最大池化操作来突出各个卷积操作提取的最关键信息,拼接后通过全连接层对特征进行组合,最后通过交叉熵损失函数来训练模型。
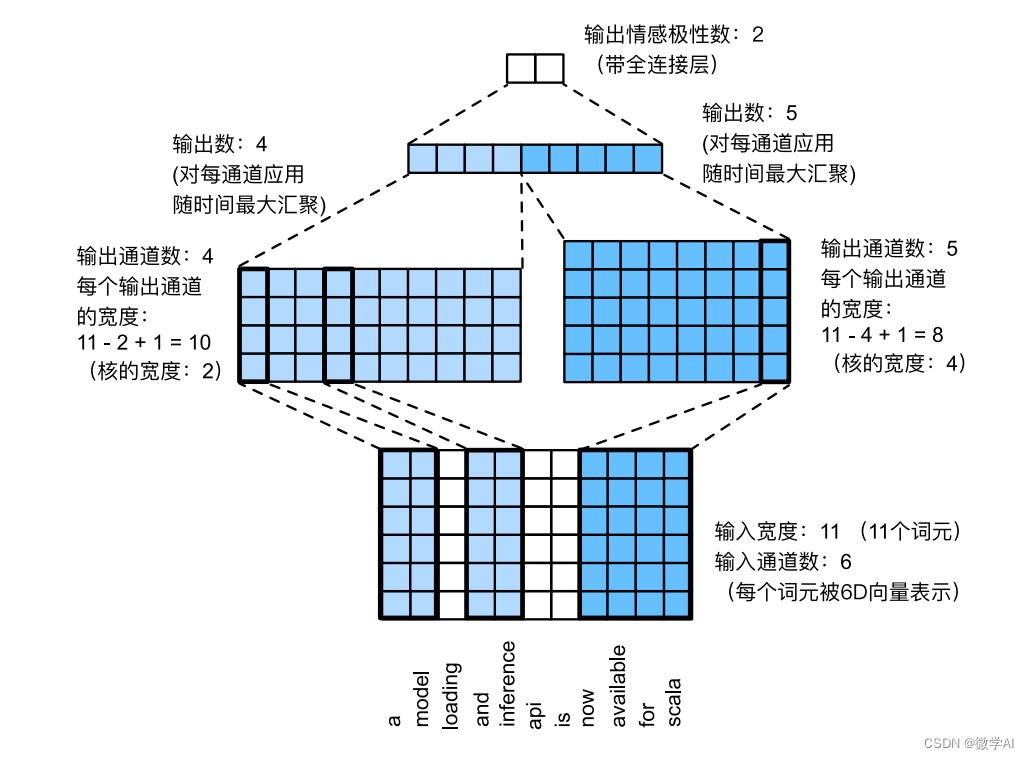
textCNN的模型架构
注:N-Gram是大词汇连续语音识别中常用的一种语言模型。⼜被称为⼀阶马尔科夫链。它的基本思想是将⽂本⾥⾯的内容按照字节进行大小为 N 的滑动窗⼝操作,形成了长度是 N 的字节⽚段序列。每⼀个字节⽚段称为 gram,对所有的 gram 的出现频度进⾏统计,并且按照事先设定好的阈值进⾏过滤,形成关键 gram 列表,是这个⽂本的向量特征空间。列表中的每⼀种 gram 就是⼀个特征向量维度。
一、前期工作
1. 设置GPU
如果使用的是CPU可以注释掉这部分的代码。
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
#导入库包
import tensorflow.keras as keras
from config import Config
import os
from sklearn import metrics
import numpy as np
from keras.models import Sequential
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding,Dropout,Conv1D,ReLU,GlobalMaxPool1D,InputLayer2. 导入预处理词库类
trainingSet_path = "cnews.train.txt"
valSet_path = "cnews.val.txt"
model_save_path = "CNN_model.h5"
testingSet_path = "cnews.test.txt"
#创建 文本处理类:preprocesser
class preprocesser(object):
def __init__(self):
self.config = Config()
# 读取文本txt 函数
def read_txt(self, txt_path):
with open(txt_path, "r", encoding='utf-8') as f:
data = f.readlines()
labels = []
contents = []
for line in data:
label, content = line.strip().split('\t')
labels.append(label)
contents.append(content)
return labels, contents
# 读取分词文档
def get_vocab_id(self):
vocab_path = "cnews.vocab.txt"
with open(vocab_path, "r", encoding="utf-8") as f:
infile = f.readlines()
vocabs = list([word.replace("\n", "") for word in infile])
vocabs_dict = dict(zip(vocabs, range(len(vocabs))))
return vocabs, vocabs_dict
# 获取新闻属性id 函数
def get_category_id(self):
categories = ["体育", "财经", "房产", "家居", "教育", "科技", "时尚", "时政", "游戏", "娱乐"]
cates_dict = dict(zip(categories, range(len(categories))))
return cates_dict
#将语料中各文本转换成固定max_length后返回各文本的标签与文本tokens
def word2idx(self, txt_path, max_length):
# vocabs:分词词汇表
# vocabs_dict:各分词的索引
vocabs, vocabs_dict = self.get_vocab_id()
# cates_dict:各分类的索引
cates_dict = self.get_category_id()
# 读取语料
labels, contents = self.read_txt(txt_path)
# labels_idx:用来存放语料中的分类
labels_idx = []
# contents_idx:用来存放语料中各样本的索引
contents_idx = []
# 遍历语料
for idx in range(len(contents)):
# tmp:存放当前语句index
tmp = []
# 将该idx(样本)的标签加入至labels_idx中
labels_idx.append(cates_dict[labels[idx]])
# contents[idx]:为该语料中的样本遍历项
# 遍历contents中各词并将其转换为索引后加入contents_idx中
for word in contents[idx]:
if word in vocabs:
tmp.append(vocabs_dict[word])
else:
# 第5000位设置为未知字符
tmp.append(5000)
# 将该样本index后结果存入contents_idx作为结果等待传回
contents_idx.append(tmp)
# 将各样本长度pad至max_length
x_pad = keras.preprocessing.sequence.pad_sequences(contents_idx, max_length)
y_pad = keras.utils.to_categorical(labels_idx, num_classes=len(cates_dict))
return x_pad, y_pad
def word2idx_for_sample(self, sentence, max_length):
# vocabs:分词词汇表
# vocabs_dict:各分词的索引
vocabs, vocabs_dict = self.get_vocab_id()
result = []
# 遍历语料
for word in sentence:
# tmp:存放当前语句index
if word in vocabs:
result.append(vocabs_dict[word])
else:
# 第5000位设置为未知字符,实际中为vocabs_dict[5000],使得vocabs_dict长度变成len(vocabs_dict+1)
result.append(5000)
x_pad = keras.preprocessing.sequence.pad_sequences([result], max_length)
return x_pad
pre = preprocesser() # 实例化preprocesser()类数据集样式:

二、参数设定
num_classes = 10 # 类别数
vocab_size = 5000 #语料词大小
seq_length = 600 #词长度
conv1_num_filters = 128 # 第一层输入卷积维数
conv1_kernel_size = 1 # 卷积核数
conv2_num_filters = 64 # 第二层输入卷维数
conv2_kernel_size = 1 # 卷积核数
hidden_dim = 128 # 隐藏层维度
dropout_keep_prob = 0.5 # dropout层丢弃0.5
batch_size = 64 # 每次训练批次数 四、创建模型
def TextCNN():
#创建模型序列
model = Sequential()
model.add(InputLayer((seq_length,)))
model.add(Embedding(vocab_size+1, 256, input_length=seq_length))
model.add(Conv1D(conv1_num_filters, conv1_kernel_size, padding="SAME"))
model.add(Conv1D(conv2_num_filters, conv2_kernel_size, padding="SAME"))
model.add(GlobalMaxPool1D())
model.add(Dense(hidden_dim))
model.add(Dropout(dropout_keep_prob))
model.add(ReLU())
model.add(Dense(num_classes, activation="softmax"))
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["acc"])
print(model.summary())
return model
五、训练模型函数
def train(epochs):
model = TextCNN()
model.summary()
x_train, y_train = pre.word2idx(trainingSet_path, max_length=seq_length)
x_val, y_val = pre.word2idx(valSet_path, max_length=seq_length)
model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,validation_data=(x_val, y_val))
model.save(model_save_path, overwrite=True)六、测试模型函数
def test():
if os.path.exists(model_save_path):
model = keras.models.load_model(model_save_path)
print("-----model loaded-----")
model.summary()
x_test, y_test = pre.word2idx(testingSet_path, max_length=seq_length)
print(x_test.shape)
print(type(x_test))
print(y_test.shape)
# print(type(y_test))
pre_test = model.predict(x_test)
# print(pre_test.shape)
# metrics.classification_report(np.argmax(pre_test, axis=1), np.argmax(y_test, axis=1), digits=4, output_dict=True)
print(metrics.classification_report(np.argmax(pre_test, axis=1), np.argmax(y_test, axis=1)))七、训练模型与预测
if __name__ == '__main__':
train(20) # 训练模型
Epoch 1/20
782/782 [==============================] - 119s 152ms/step - loss: 0.7380 - accuracy: 0.7696 - val_loss: 0.5568 - val_accuracy: 0.8334
Epoch 2/20
782/782 [==============================] - 122s 156ms/step - loss: 0.3898 - accuracy: 0.8823 - val_loss: 0.4342 - val_accuracy: 0.8588
Epoch 3/20
782/782 [==============================] - 121s 154ms/step - loss: 0.3382 - accuracy: 0.8979 - val_loss: 0.4154 - val_accuracy: 0.8648
Epoch 4/20
782/782 [==============================] - 116s 148ms/step - loss: 0.3091 - accuracy: 0.9055 - val_loss: 0.4408 - val_accuracy: 0.8688
Epoch 5/20
782/782 [==============================] - 117s 150ms/step - loss: 0.2904 - accuracy: 0.9116 - val_loss: 0.3880 - val_accuracy: 0.8844
Epoch 6/20
782/782 [==============================] - 119s 153ms/step - loss: 0.2724 - accuracy: 0.9153 - val_loss: 0.4412 - val_accuracy: 0.8664
Epoch 7/20
782/782 [==============================] - 117s 149ms/step - loss: 0.2601 - accuracy: 0.9206 - val_loss: 0.4217 - val_accuracy: 0.8726
Epoch 8/20
782/782 [==============================] - 116s 149ms/step - loss: 0.2423 - accuracy: 0.9243 - val_loss: 0.4205 - val_accuracy: 0.8760
Epoch 9/20
782/782 [==============================] - 117s 150ms/step - loss: 0.2346 - accuracy: 0.9275 - val_loss: 0.4022 - val_accuracy: 0.8808
Epoch 10/20
782/782 [==============================] - 116s 148ms/step - loss: 0.2249 - accuracy: 0.9301 - val_loss: 0.4297 - val_accuracy: 0.8726
....
model = keras.models.load_model(model_save_path)
print("-----model loaded-----")
model.summary()
test = preprocesser()
# 测试文本
x_test = '5月6日,上海莘庄基地田径特许赛在第二体育运动学校鸣枪开赛。男子110米栏决赛,19岁崇明小囡秦伟搏以13.35秒的成绩夺冠,创造本赛季亚洲最佳。谢文骏迎来赛季首秀,以13.38秒获得亚军'
x_test = test.word2idx_for_sample(x_test, 600)
categories = ["体育", "财经", "房产", "家居", "教育", "科技", "时尚", "时政", "游戏", "娱乐"]
pre_test = model.predict(x_test)
index = int(np.argmax(pre_test, axis=1)[0])
print('该新闻为:', categories[index])训练20次后,训练集损失函数loss: 0.1635 ,训练集准确率:accuracy: 0.9462
验证集函数:val_loss: 0.4554 验证集准确率 val_accuracy: 0.8820
运行结果:该新闻为: 体育
往期作品:
深度学习实战项目
3.深度学习实战3-文本卷积神经网络(TextCNN)新闻文本分类
4.深度学习实战4-卷积神经网络(DenseNet)数学图形识别+题目模式识别
5.深度学习实战5-卷积神经网络(CNN)中文OCR识别项目
6.深度学习实战6-卷积神经网络(Pytorch)+聚类分析实现空气质量与天气预测
9.深度学习实战9-文本生成图像-本地电脑实现text2img
10.深度学习实战10-数学公式识别-将图片转换为Latex(img2Latex)
11.深度学习实战11(进阶版)-BERT模型的微调应用-文本分类案例
12.深度学习实战12(进阶版)-利用Dewarp实现文本扭曲矫正
13.深度学习实战13(进阶版)-文本纠错功能,经常写错别字的小伙伴的福星
14.深度学习实战14(进阶版)-手写文字OCR识别,手写笔记也可以识别了
15.深度学习实战15(进阶版)-让机器进行阅读理解+你可以变成出题者提问
16.深度学习实战16(进阶版)-虚拟截图识别文字-可以做纸质合同和表格识别
17.深度学习实战17(进阶版)-智能辅助编辑平台系统的搭建与开发案例
18.深度学习实战18(进阶版)-NLP的15项任务大融合系统,可实现市面上你能想到的NLP任务
19.深度学习实战19(进阶版)-ChatGPT的本地实现部署测试,自己的平台就可以实现ChatGPT
...(待更新)