基于循环神经网络 (LSTM) 的情感评论文本分类
一、简介
众所周知,区分用户发帖或者评论文本的情感分类问题,对商家来说是很重要的,不仅可以及时了解到用户的情绪,而且可以帮助商家进行产品迭代。例如,“汽车之家” 网站上的用户评论,进过情感词分类后,可以得到很多有用的信息,如 “发动机有问题”,“总是烧机油” 等,故下面,我们就来尝试解决。
首先,对于情感分类问题,一般有两种解决方案,一是,基于情感词典的规则的解决方法,二是,基于机器学习以及深度学习的方法。这里我们采用后者方法。这里我们只是将情感倾向分为 支持,反对,以及中立。读者当然可以根据自己的需求,分的更加详细。一般基于词典的规则方法,优点是非常稳定,缺陷是对于不在词典中的词就效果很差,而深度学习的方法,需要人工标注语料作为训练集,提取出文本的特征,用特征构建一个分类器,在做情感分类。它因为具有一部分语境,而避免了部分情感词典的缺点。但是它由于特征抽取方法不同,而导致有噪音,通用性不好。必须针对特定语义环境特定训练模型才行。
为了,克服这两种方法的缺点,一般有如下方法:
利用已有的知识结构自动学习各种语料。比如用维基百科训练一个 Word2vec 模型。此外,知识图谱的建立和语境感知在情感分类中也是很重要的。
结合词法分析和机器学习两种方法综合判断,以减小误差。
下面采用的是 机器学习方法:
二、实现代码
这里基于 keras 深度学习框架实现:
- 第一步,便是抽取特征: 如下
extract_feature.py
# coding: utf-8
"""
文本数据的特征提取
"""
import codecs
import jieba
import numpy as np
import pandas as pd
import jieba.posseg as psg
from keras.preprocessing import sequence
# params
MAX_LENGTH = 150
CLASS_NUM = 3 # 默认分为三类,满意,不满意,一般
# 载入停用词表
stopwords = codecs.open('./chen/stopwords.txt',encoding='utf-8').read().split('\n')
def extract_lstm_train(file_name,tag_num=CLASS_NUM,col_tag=0,col_content=1,length=MAX_LENGTH):
"""
抽取 lstm 的特征
:param file_name: 文件
:param tag_num: 分类数目
:param col_tag: 标签在 xlsx 中的位置
:param col_content: 内容在 xlsx 中的位置
:param length: 每段话表示的最大长度,超过会截取,不够长会用 0 补齐
:return
"""
contents = pd.read_csv(file_name,header=None)
cw = lambda x: [word.encode('utf-8') for word in jieba.cut(x) if word not in stopwords and word.strip() != '']
# 给 contents 的 dataframe 添加一行 words
contents['words'] = contents[col_content].apply(cw)
d2v_train = contents['words']
w = [] # 将所有词语整合在一起
for i in d2v_train:
w.extend(i)
# 将 list 转化成 pd.Series 在用 value_counts 返回不重复的词语
print w
# print pd.Series(w).value_counts
# 制作词典,其中 word 作为索引值,出现的频率做为 value
dictionary = pd.DataFrame(pd.Series(w).value_counts())
# 给词典每个词语按照频率加上 id ,从 1 .... 开始
dictionary['id'] = list(range(1,len(dictionary) + 1))
print 'dictionary length = ',len(dictionary)
# 将词与 id 对应, 并且保存到 contents 的 sent 列
get_sent = lambda x: list(dictionary['id'][x])
contents['sent'] = contents['words'].apply(get_sent)
# 将一段文本拉长成 length = 150,不够就填加 0
print 'Pad sequences (samples x time) '
print contents['sent']
contents['sent'] = list(sequence.pad_sequences(contents['sent'],maxlen=5))
print contents['sent']
print contents
# 训练集合
x = np.array(list(contents['sent']))
# len(contents[0]) 相当于有多少个句子
y = np.zeros((len(list(contents[col_tag])),tag_num))
for i in range(len(list(contents[col_tag]))):
for j in range(tag_num):
if contents[col_tag][i] == j:
y[i][j] = 1 # 输出的 one-hot 编码
print y
print dictionary
return dictionary, x, y, length
def extract_lstm_test(dictionary,file_name,tag_num=CLASS_NUM,col_tag=0,col_content=1,length=MAX_LENGTH):
contents = pd.read_csv(file_name,header=None)
cw = lambda x: [word.encode('utf-8') for word in jieba.cut(x) if word not in stopwords and word.strip() != '' and word.encode('utf-8') in dictionary.index]
contents['words'] = contents[col_content].apply(cw)
get_sent = lambda x: list(dictionary['id'][x])
contents['sent'] = contents['words'].applay(get_sent)
print 'Pad sequences (samples x time)'
contents['sent'] = list(sequence.pad_sequences(contents['sent'],maxlen=length))
x = np.array(list(contents['sent'])) # 训练集
y = np.zeros((len(list(contents[col_tag])),tag_num))
for i in range(len(list(contents[col_tag]))):
for j in range(tag_num):
if contents[col_tag][i] == j:
y[i][j] = 1
return x, y
def word_vector(pair, posdict, negdict, inverse, adv):
"""
将word转化为向量
:param pair: 词对,(word, flag)
:param posdict: positive 词库
:param negdict: negtive词库
:param inverse: inverse词库
:param adv: adv 词库
:return:
"""
word_vec = np.zeros(9)
if pair.word in posdict:
word_vec[0] = 1
if pair.word in negdict:
word_vec[1] = 1
if pair.word in inverse:
word_vec[2] = 1
if pair.word in adv:
word_vec[3] = 1
if pair.flag == 'n':
word_vec[4] = 1
if pair.flag == 'v':
word_vec[5] = 1
if pair.flag == 'a':
word_vec[6] = 1
if pair.flag == 'd':
word_vec[7] = 1
if pair.flag == 'x':
word_vec[8] = 1
return word_vec
def review2matrix(review, posdict, negdict, inverse, adv): # 将一句话表示为词的矩阵
"""
将一句话表示为词的矩阵
"""
matrix = []
for pair in review:
word_vec = word_vector(pair, posdict, negdict, inverse, adv)
matrix.append(word_vec)
return matrix
def reviews2matrix(reviews, posdict, negdict, inverse, adv): # 将所有review表示为词的矩阵
"""
将所有的句子全部表示为词的矩阵
"""
reviews_matrix = []
for review in reviews:
matrix = review2matrix(review, posdict, negdict, inverse, adv)
reviews_matrix.append(matrix)
return reviews_matrix
def matrix2vec(matrix):
"""
将句子表示为词向量的和
"""
sent_train_x = []
for review_matrix in matrix:
sum_vec = np.zeros(9)
for vec in review_matrix:
sum_vec += vec
sent_train_x.append(list(sum_vec))
return sent_train_x
def extract_dictionary_feature(file_name, col_tag=0, col_content=1):
# 载入词表
adv = codecs.open('./data/vocabulary/adv.txt', 'rb', encoding='utf-8').read().split('\n')
inverse = codecs.open('./data/vocabulary/inverse.txt', 'rb', encoding='utf-8').read().split('\n')
negdict = codecs.open('./data/vocabulary/negdict.txt', 'rb', encoding='utf-8').read().split('\n')
posdict = codecs.open('./data/vocabulary/posdict.txt', 'rb', encoding='utf-8').read().split('\n')
contents = pd.read_excel(file_name, header=None)
print 'cut words...'
cw = lambda x: [pair for pair in psg.lcut(x) if pair.word not in stopwords]
contents['pairs'] = contents[col_content].apply(cw)
matrix = reviews2matrix(list(contents['pairs']), posdict, negdict, inverse, adv)
x = matrix2vec(matrix)
y = list(contents[col_tag])
return x, y- 其次,为模型的建立
lstm_model.py
# coding: utf-8
"""
lstm 模型
"""
import numpy as np
from keras.utils import np_utils
from sklearn.metrics import accuracy_score
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
def lstm_train(dic,x,y,maxlen):
print 'Build model ... '
model = Sequential()
model.add(Embedding(input_dim=len(dic) + 1, output_dim=256,input_length=maxlen))
model.add(LSTM(128)) # 相当于提取文本特征了
model.add(Dropout(0.5)) # 使得输入一部分为 0,实现下一层的 dropout 训练
model.add(Dense(3)) # 3 个表示情感的分类为 3 个类别
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',class_mode='binary')
model.fit(x,y,batch_size=32,nb=10,show_accuracy = True)
return model
def lstm_test(model, xt, yt):
classes = model.predict_classes(xt)
acc= accuracy_score(classes,yt)
print 'Test accuracy: ', acc- 其三,便是 应用实现程序 app
test_lstm.py
# coding : utf-8
from lstm_model import lstm_train, lstm_test
from extract_feature import extract_lstm_train, extract_lstm_test
dictionary, x, y, length = extract_lstm_train('./data/car/tran.csv')
xt, yt = extract_lstm_test(dictionary,'./data/test.csv')
model = lstm_train(dictionary, x, y, length)
lstm_test(model, xt, yt)三、结合 CNN 和 RNN 进行特征提取
- 因为 CNN 和 RNN 在提取文本特这时,各有优缺点,那么,将其结合一下合并成一个网络,既结合了两者的优点,也屏蔽了两者的缺点。但是,如果要将其结合时,需要考虑先用 RNN 还是 CNN。因为,RNN 在处理时序信息时有天然的优势,而语言(文本)本身就具有天然的时序特征,如果我们先用 CNN 卷积的 话,则时序特征可能就无法完全的保留。基于这一点,我们开始时先使用 RNN 进行特征的提取文本的初始信息。为了更多的提取信息,我们在输入层后使用一个双向的 LSTM 层 —- BiLSTM 。它的下一层,我们选用时序的包装器,目标是在处理时序时进行压缩。再往下,为了提取强特征(即决定句子意义的最大特征)的目标(该目标和池化层目标意义非诚相像),我们选用 Max_Pooling 层做最大池化工作,目的是在句子级别上提取最大化特征。这里我们取 pool_size 为 5,即每5个向量提取一个最大向量,最后我们将二维输出拉平成一维输出,最后输出一个只有一个单元的层,这里做二分类,当然,读者也可以做多分类应用。
网络结构图,如下:
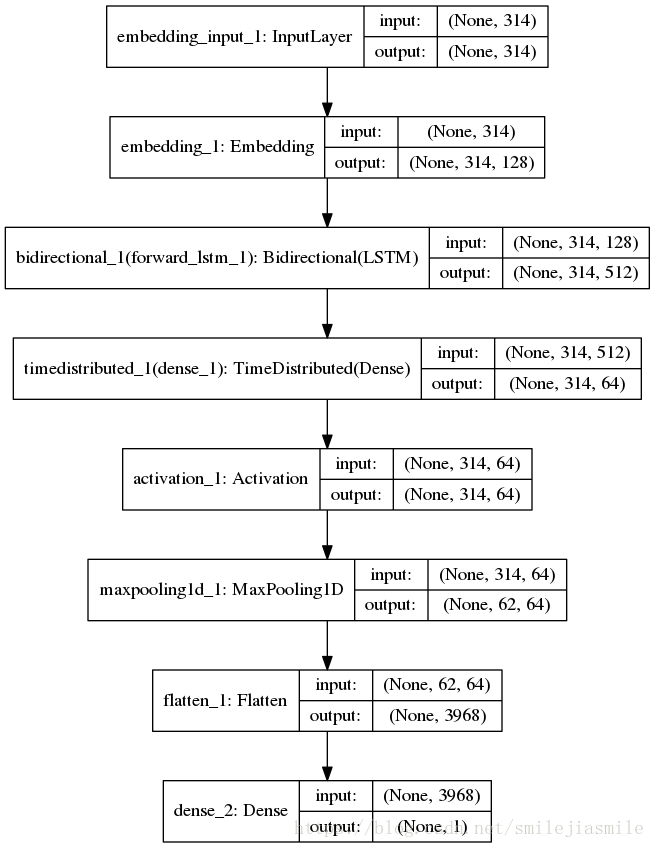
代码如下:
# coding: utf-8
import os
import numpy as np
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
from keras.layers.wrappers import TimeDistributed, Bidirectional
from keras.layers import Flatten, Lambda, K
from keras.layers.embeddings import Embedding
from keras.layers.pooling import MaxPooling2D,GlobalMaxPool2D,MaxPooling1D
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def text_feature_extract_model1(embedding_size=128,hidden_size=256):
'''
this is a model use normal Bi-LSTM and maxpooling extract feature
examples:
这个货很好,很流畅 [ 1.62172219e-05]
这个东西真好吃, [ 1.65377696e-05]
服务太糟糕,味道差 [ 1.]
你他妈的是个傻逼 [ 1.]
这个贴花的款式好看 [ 1.76498161e-05]
看着不错,生产日期也是新的是16年12月份的,就是有点小贵 [ 1.59666997e-05]
一股淡淡的腥味。每次喝完都会吃一口白糖 [ 1.]
还没喝,不过,看着应该不错哟 [ 1.52662833e-05]
用来看电视还是不错的,就是有些大打字不习惯,要是可以换输入法就好了! [ 1.]
嗯,中间出了点小问题已经联系苹果客服解决了,打游戏也没有卡顿,总体来讲还不错吧! [ 1.52281245e-05]
下软件下的多的时候死了一回机,强制重启之后就恢复了。 [ 1.]
东西用着还可以很流畅! [ 1.59881820e-05]
:return:
'''
model = Sequential()
model.add(Embedding(input_dim=max_features,
output_dim=embedding_size,
input_length=max_seq))
model.add(Bidirectional(LSTM(hidden_size,return_sequences=True)))
model.add(TimeDistributed(Dense(embedding_size/2)))
model.add(Activation('softplus'))
model.add(MaxPooling1D(5))
model.add(Flatten())
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
return model
if __name__ == '__main__':
# prepare y 1 negtive 0 postive
y = []
txt_path = '/Users/duzhe/Downloads/chen/深度学习算法实践/Book_DeepLearning_Practice-master/2_Chapter/DeepTextClf/data/corpus/reviews/'
# 构造 label
with open(txt_path + '1_point.txt','rb') as fp:
lines = fp.readlines()
len_temp_lines = len(lines)
for i in range(len(lines)):
y.append(1)
with open(txt_path + '5_point.txt','rb') as fp:
lines += fp.readlines() # 继续添加到 lines 的后面
for i in range(len(lines[len_temp_lines:])):
y.append(0)
# 创建词典
def create_dict():
# fp.read() 会将文本返回成一个长的 string, 即 dict
dict = open(txt_path + '1_point.txt','rb').read()
dict += open(txt_path + '5_point.txt','rb').read()
# print type(dict.decode('utf8'))
# 将 string 送给 list 后,便拆分成了每个字了
dict_list = set(list(dict.decode('utf8')))
dicts = {}
for i, d in enumerate(dict_list):
# print 'i= ',i, 'd= ', d
dicts[d] = i
return dicts
def create_X(lines):
len_seq = []
dicts = create_dict()
sequences = []
for line in lines:
if line == '\n':
continue
line = line.strip()
l = list(line.decode('utf8'))
# 找到每个字出现的序列号给 sequence
sequence = [dicts[char] for char in l]
len_seq.append(len(sequence))
sequences.append(sequence)
return sequences, len_seq, dicts
X_sequences, len_seq, dicts = create_X(lines)
# 取最大序列的一半
max_seq = max(len_seq) / 2
print 'max_seq:',max_seq
max_features = len(dicts) + 1
print 'max_features:', max_features
data_X = pad_sequences(X_sequences,maxlen=max_seq)
label2ind = {'postive':0, 'negitive':1}
embedding_size = 128
hidden_size = 256
model = text_feature_extract_model1(embedding_size=embedding_size,hidden_size=hidden_size)
model.fit(data_X, y, validation_split=0.1,batch_size=256,nb_epoch=6, verbose=1)
# save model
model_json = model.to_json()
with open('rcnn_model_20w_1.json','w') as json_file:
json_file.write(model_json)
# serialize weights to HDF5 checkpoint 已经存储了weight,这里不做操作
model.save_weights('rcnn_model_20w_1.h5')
print 'Saved model to disk'
'''
load model
'''
from keras.models import model_from_json
model = model_from_json(open('rcnn_model_20w_1.json','rb').read())
model.load_weights('rcnn_model_20w_1.h5')
print 'Loaded model to disk'
test = ["这个货很好,很流畅","这个东西真好吃,",
"服务太糟糕,味道差","你他妈的是个傻逼",
"这个贴花的款式好看",
"看着不错,生产日期也是新的是16年12月份的,就是有点小贵",
"一股淡淡的腥味.每次喝完都会吃一口白糖",
"还没喝,不过,看着应该不错哟",
"用来看电视还是不错的,就是有些大打字不习惯,要是可以换输入法就好了!",
"嗯,中间出了点小问题已经联系苹果客服解决了,打游戏也没有卡顿,总体来讲还不错吧!",
"下软件下的多的时候死了一回机,强制重启之后就恢复了",
"东西用着还可以很流畅!"]
test_sequences = []
for line in test:
l = list(line.decode('utf-8'))
sequence = [ dicts[char] for char in l]
test_sequences.append(sequence)
test_data = pad_sequences(test_sequences,maxlen=max_seq)
result = model.predict(test_data)
for i, _ in enumerate(test):
print _, result[i]