# cnn实现垃圾邮件分类
from keras.models import Sequential
from keras.layers import Dense, Conv1D, GlobalMaxPooling1D, Embedding, Dropout, Activation, MaxPooling1D
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras import metrics
import keras.preprocessing.text
from sklearn.preprocessing import LabelEncoder
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data_file = 'spam.csv'
# 读取数据
df = pd.read_csv(data_file, encoding='latin-1')
# 标签
labels = df.v1
# 文本
texts = df.v2
# 预处理,将一个句子拆分成单词构成列表
def text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=" "):
if lower:
text = text.lower()
if type(text) == unicode:
translate_table = {ord(c): ord(t) for c, t in zip(filters, split*len(filters))}
else:
translate_table = maketrans(filters, split*len(filters))
text = text.translate(translate_table)
seq = text.split(split)
return [i for i in seq if i]
keras.preprocessing.text.text_to_word_sequence = text_to_word_sequence
num_max = 1000
le = LabelEncoder()
labels = le.fit_transform(labels)
# 分词器
tok = Tokenizer(num_words=num_max) # num_words:处理单词最大数量
tok.fit_on_texts(texts)
mat_texts = tok.texts_to_matrix(texts, mode='count') # 文本向量化
n_sample = mat_texts.shape[0]
max_len = 1000 # 序列最大长度
cnn_texts_seq = tok.texts_to_sequences(texts) # 文本转化为序列
# 填充序列,短于序列的最大长度用0填充,长于序列最大长度进行截断
cnn_texts_mat = sequence.pad_sequences(cnn_texts_seq, maxlen=max_len)
# cnn
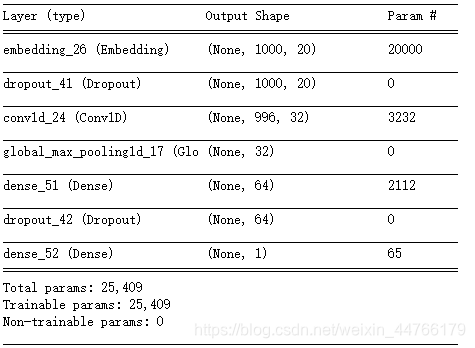
def get_cnn_model():
model = Sequential()
model.add(Embedding(1000, 20, input_length=max_len)) # 输入维度(词汇表大小);词向量维度;输入序列长度
model.add(Dropout(0.2))
model.add(Conv1D(32, 5, strides=1, padding='valid', activation='relu')) # 256
# model.add(MaxPooling1D())
# model.add(Conv1D(512, 5, strides=1, padding='valid', activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(64, activation='relu')) # 64
model.add(Dropout(0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
return model
# 训练
def train_model(model, x, y):
return model.fit(x, y, batch_size=32, epochs=10, verbose=1, validation_split=0.2)
n_validation = int(n_sample*0.8)
# 训练集
x_train = cnn_texts_mat[:n_validation]
# 标签
y_train = labels[:n_validation]
# 验证集
x_val = cnn_texts_mat[n_validation:]
y_val = labels[n_validation:]
m = get_cnn_model()
history = train_model(m, x_train, y_train)
# 评估
def test_model(model, x, y):
return model.evaluate(x, y)
loss, accuracy = test_model(m, x_val, y_val)
print('loss: ', loss)
print('accuracy: ', accuracy)
# 预测
def predicted(model, x):
return model.predict_classes(x)
y_pred = predicted(m, x_val)
# print(y_pred[:10])
# 绘图
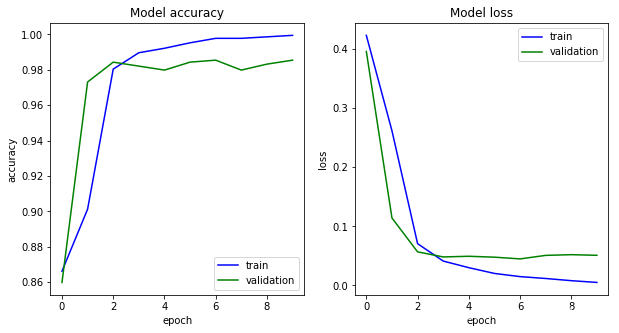
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(history.history['acc'], c='b', label='train')
plt.plot(history.history['val_acc'], c='g', label='validation')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Model accuracy')
plt.subplot(122)
plt.plot(history.history['loss'], c='b', label='train')
plt.plot(history.history['val_loss'], c='g', label='validation')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Model loss')
plt.show()