LCS的定义
最长公共子序列,即Longest Common Subsequence,LCS。
一个序列S任意删除若干个字符得到新序列T,则T叫做S的子序列;
两个序列X和Y的公共子序列中,长度最长的那个,定义为X和Y的最长公共子序列。
字符串13455 与245576的最长公共子序列为455
字符串acdfg与adfc的最长公共子序列为adf
注意区别最长公共子串(Longest Common Substring)最长公共字串要求连续
LCS的意义
求两个序列中最长的公共子序列算法,广泛的应用在图形相似处理、媒体流的相似比较、计算生物学方面。生物学家常常利用该算法进行基因序列比对,由此推测序列的结构、功能和演化过程。
LCS可以描述两段文字之间的“相似度”,即它们的雷同程度,从而能够用来辨别抄袭。另一方面,对一段文字进行修改之后,计算改动前后文字的最长公共子序列,将除此子序列外的部分提取出来,这种方法判断修改的部分,往往十分准确。简而言之,百度知道、百度百科都用得上。
LCS的记号
字符串X,长度为m,从1开始数;
字符串Y,长度为n ,从1开始数;
Xi=﹤x1,⋯,xi﹥即X序列的前i个字符(1≤i≤m)(Xi不妨读作“字符串X的i前缀”)
Yj=﹤y1,⋯,yj﹥即Y序列的前j个字符 (1≤j≤n)(字符串Y的j前缀);
LCS(X , Y) 为字符串X和Y的最长公共子序列,即为Z=﹤z1,⋯,zk﹥。
注:不严格的表述。事实上,X和Y的可能存在多个子串,长度相同并且最大,因此,LCS(X,Y)严格的说,是个字符串集合。即:Z∈ LCS(X , Y) .
LCS解法的探索:
若xm=yn(最后一个字符相同),则:
Xm与Yn的最长公共子序列Zk的最后一个字符必定为xm
zk=xm=yn
LCS(Xm,Yn) = LCS(Xm-1,Yn-1)+xm
若xm≠yn,则:
LCS(Xm,Yn)= max{LCS(Xm-1,Yn),LCS(Xm,Yn-1)}
算法中的数据结构:长度数组
使用二维数组C[m,n]
c[i,j]记录序列Xi和Yj的最长公共子序列的长度。
当i=0或j=0时,空序列是Xi和Yj的最长公共子序列,故c[i,j]=0
算法中的数据结构:方向变量
使用二维数据B[m,n],其中,b[i,j]标记c[i,j]的值是由哪一个子问题的解达到的。即c[i,j]是由c[i-1,j-1]+1或者c[i-1,j]或者c[i,j-1]的哪一个得到的。取值范围为LeftTop ↖,Left ←,Top ↑ 三种情况
实例
X=< A,B,C,B,D,A,B >
Y=< B,D,C,A,B,A >
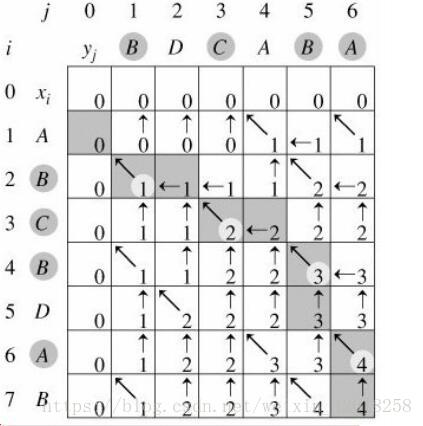
以上引用自七月在线
Pyhton代码如下:
def LCS(s1, s2):
size1 = len(s1) + 1
size2 = len(s2) + 1
# 程序多加一行,一列,方便后面代码编写
chess = [[["", 0] for j in list(range(size2))] for i in list(range(size1))]
for i in list(range(1, size1)):
chess[i][0][0] = s1[i - 1]
for j in list(range(1, size2)):
chess[0][j][0] = s2[j - 1]
print("初始化数据:")
print(chess)
for i in list(range(1, size1)):
for j in list(range(1, size2)):
if s1[i - 1] == s2[j - 1]:
chess[i][j] = ['↖', chess[i - 1][j - 1][1] + 1]
elif chess[i][j - 1][1] > chess[i - 1][j][1]:
chess[i][j] = ['←', chess[i][j - 1][1]]
else:
chess[i][j] = ['↑', chess[i - 1][j][1]]
print("计算结果:")
print(chess)
i = size1 - 1
j = size2 - 1
s3 = []
while i > 0 and j > 0:
if chess[i][j][0] == '↖':
s3.append(chess[i][0][0])
i -= 1
j -= 1
if chess[i][j][0] == '←':
j -= 1
if chess[i][j][0] == '↑':
i -= 1
s3.reverse()
print("最长公共子序列:%s" % ''.join(s3))
调用:
LCS("ABCBDAB", "BDCABA")输出结果:
初始化数据:
[[['', 0], ['B', 0], ['D', 0], ['C', 0], ['A', 0], ['B', 0], ['A', 0]],
[['A', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]],
[['B', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]],
[['C', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]],
[['B', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]],
[['D', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]],
[['A', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]],
[['B', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0], ['', 0]]]
计算结果:
[[['', 0], ['B', 0], ['D', 0], ['C', 0], ['A', 0], ['B', 0], ['A', 0]],
[['A', 0], ['↑', 0], ['↑', 0], ['↑', 0], ['↖', 1], ['←', 1], ['↖', 1]],
[['B', 0], ['↖', 1], ['←', 1], ['←', 1], ['↑', 1], ['↖', 2], ['←', 2]],
[['C', 0], ['↑', 1], ['↑', 1], ['↖', 2], ['←', 2], ['↑', 2], ['↑', 2]],
[['B', 0], ['↖', 1], ['↑', 1], ['↑', 2], ['↑', 2], ['↖', 3], ['←', 3]],
[['D', 0], ['↑', 1], ['↖', 2], ['↑', 2], ['↑', 2], ['↑', 3], ['↑', 3]],
[['A', 0], ['↑', 1], ['↑', 2], ['↑', 2], ['↖', 3], ['↑', 3], ['↖', 4]],
[['B', 0], ['↖', 1], ['↑', 2], ['↑', 2], ['↑', 3], ['↖', 4], ['↑', 4]]]
最长公共子序列:BCBA