小编是一个爬虫初学者,学习python爬虫已有一段时间了,对Scrapy框架开发有自己的一点小见解,如果有说不对的地方,希望大家多多指点。小编用的是Python2.7,如果觉得版本太旧,也可以用3.x版本,可能语法上有点不同。为了方便,小编在windows系统下开发案例。小编这次做了关于对拉勾网招聘信息采集的简单爬虫,并将采集的信息存放到MongoDB数据库中。
在开始代码之前,还没有安装过MongoDB的朋友,可以先去官网下载并安装。MongoDB下载官网:https://www.mongodb.com/download-center;安装和使用教程:
http://www.runoob.com/mongodb/mongodb-window-install.html.安装和配置完成后,因为权限不足的问题,需要在管理员模式下启动MongoDB,MongoDB的开启方法已在使用教程中展示,如下图所示.
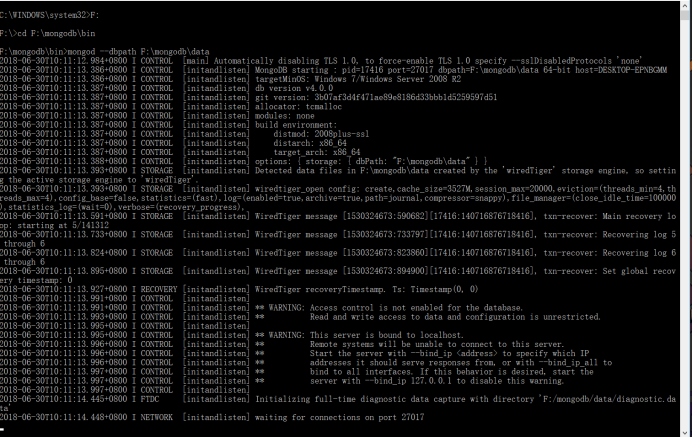
然后打开任意浏览器,输入地址:http://localhost:27017,如果一切正常,如下图所示,表示MongoDB数据正常使用.

启动MongoDB后,创建爬虫工程,以lagou为例,具体代码如下:
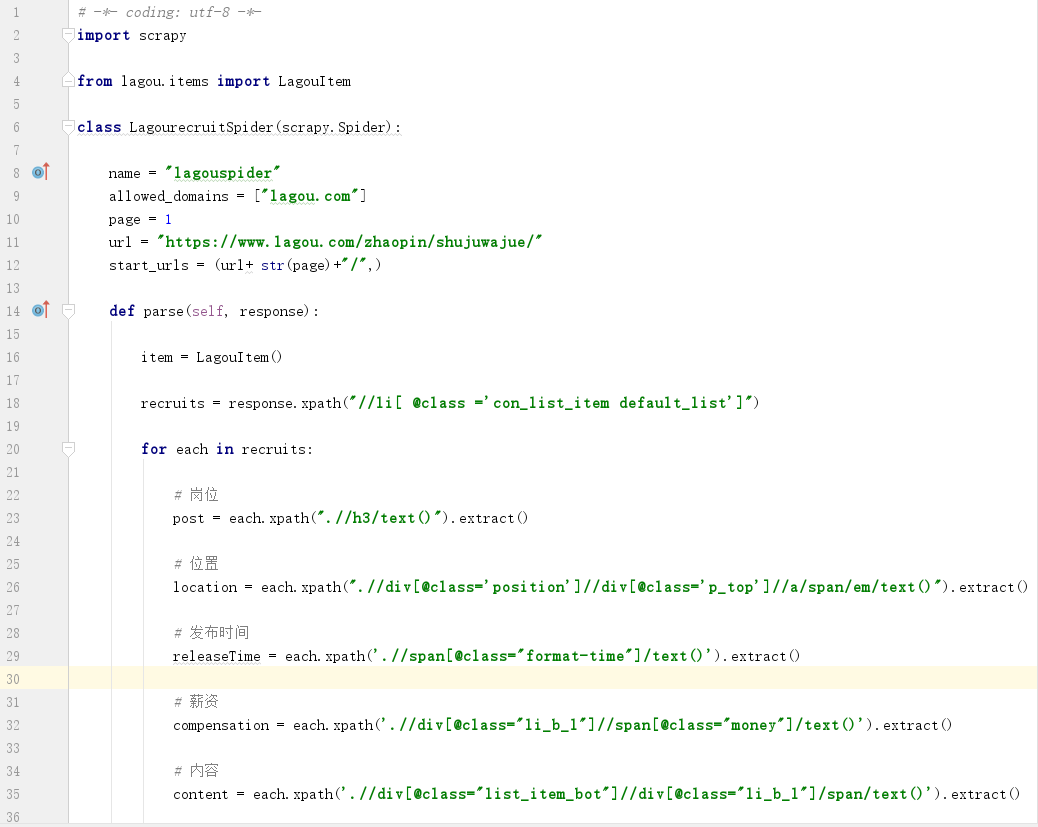
编写lagourecruit.py文件

编写items.py文件

编写setting.py文件,同时设置好自己的User-Agent

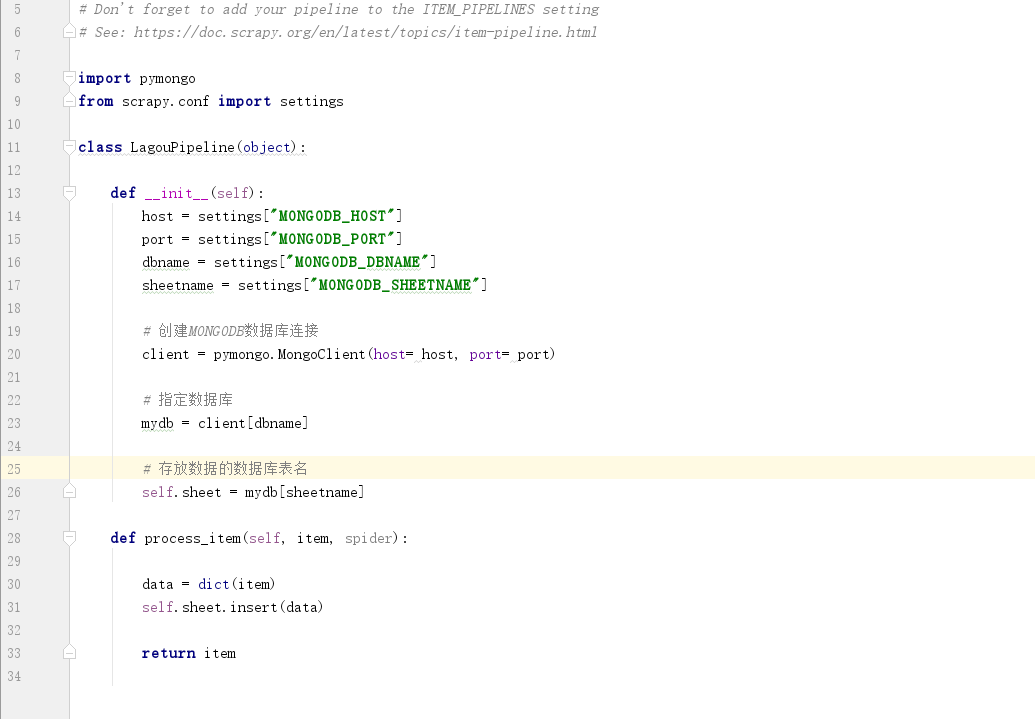
编写pipelines.py文件
编写start.py文件

执行start.py脚本(ps:在这里小编只展示一部分)

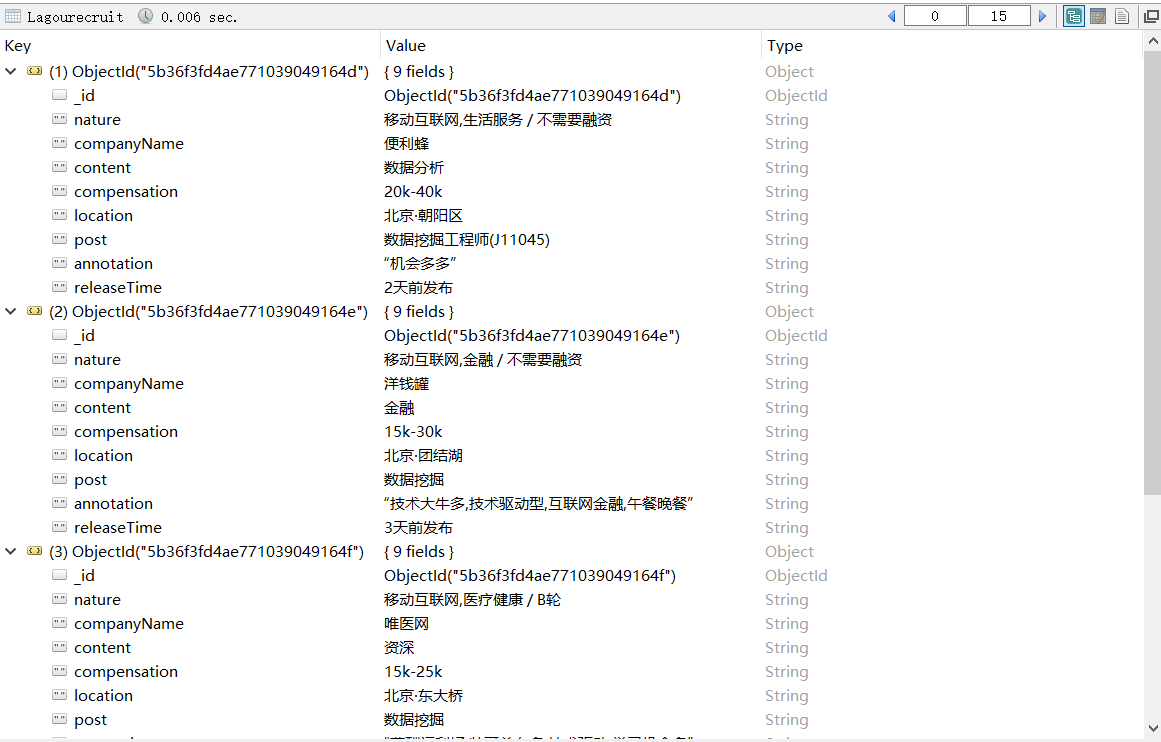
在MongoDB启动的状态下,数据已成功写入到数据库中,小编向大家展示两种数据库的查阅方式。
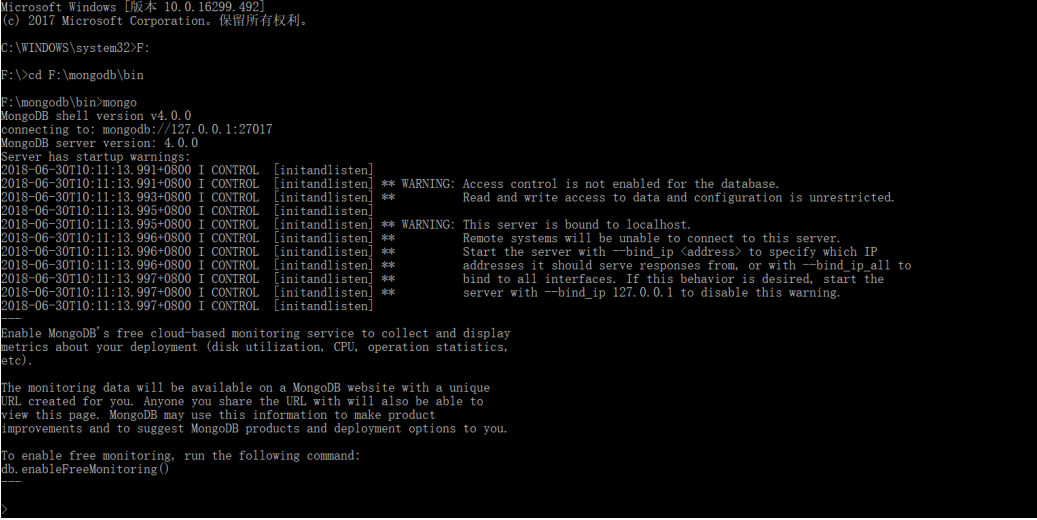
方式一:另外打开一个以管理员身份运行的cmd窗口,进入到MongoDB安装盘的mongodb\bin文件目录下,输入mongo命令,小编这里以F盘为例,如下图所示.
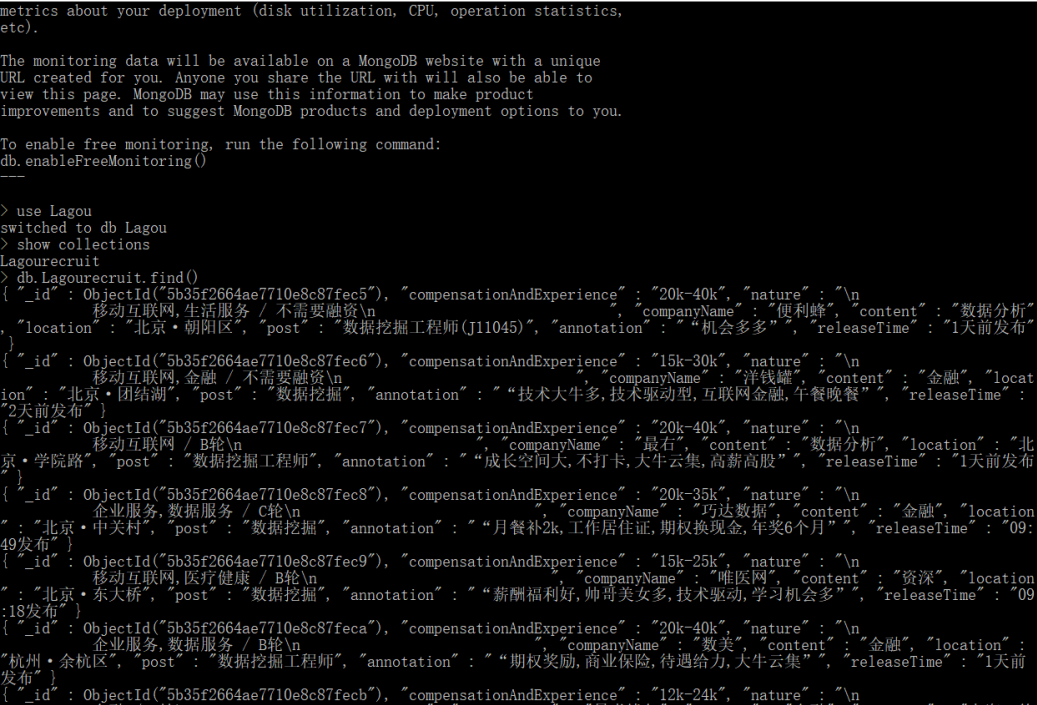
完成之后,输入use+工程名(如use lagou),接着输入查看数据库命令:show collections,再输入db.数据库名称.find()(如db.lagourecruit.find())查看数据库内容,如下图所示.
方式二:利用MongoDB可视化工具RoboMongo,RoboMongo下载地址:
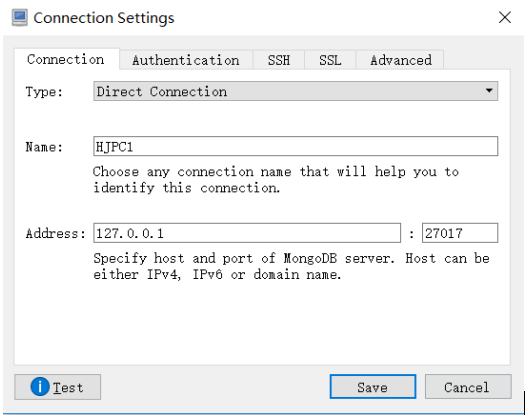
http://www.softpedia.com/get/Internet/Servers/Database-Utils/Robomongo.shtml#download,安装完成并打开,建立主机连接,如下图所示.
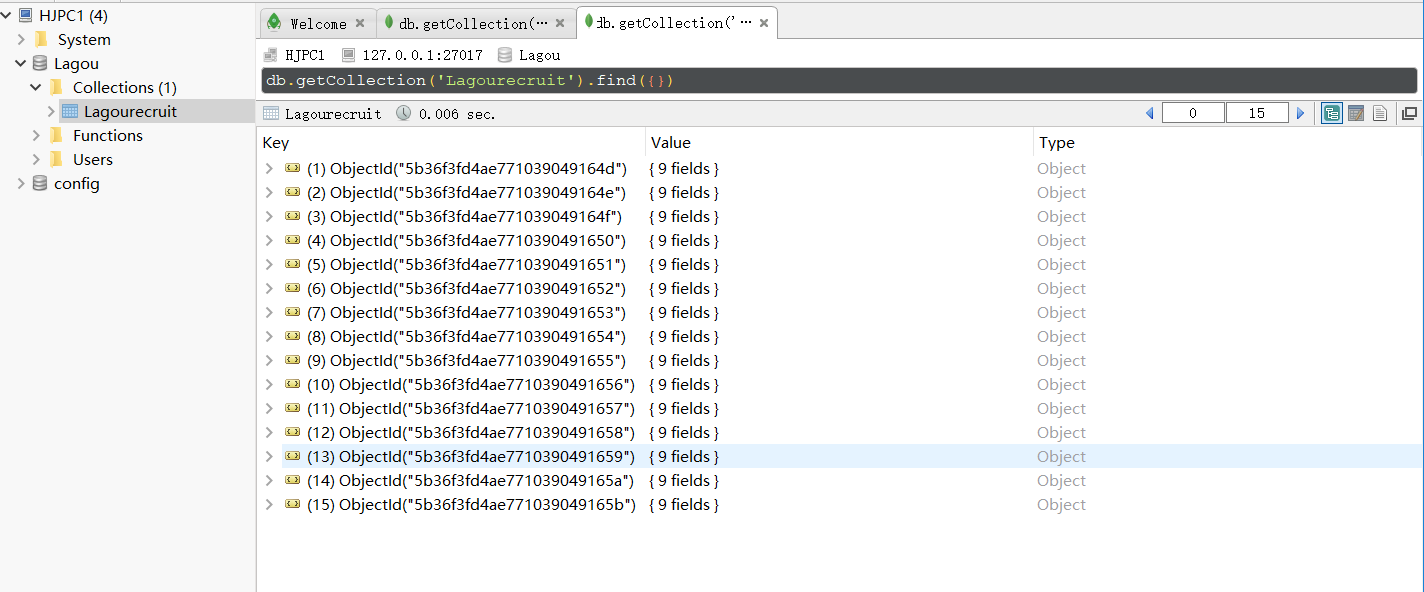
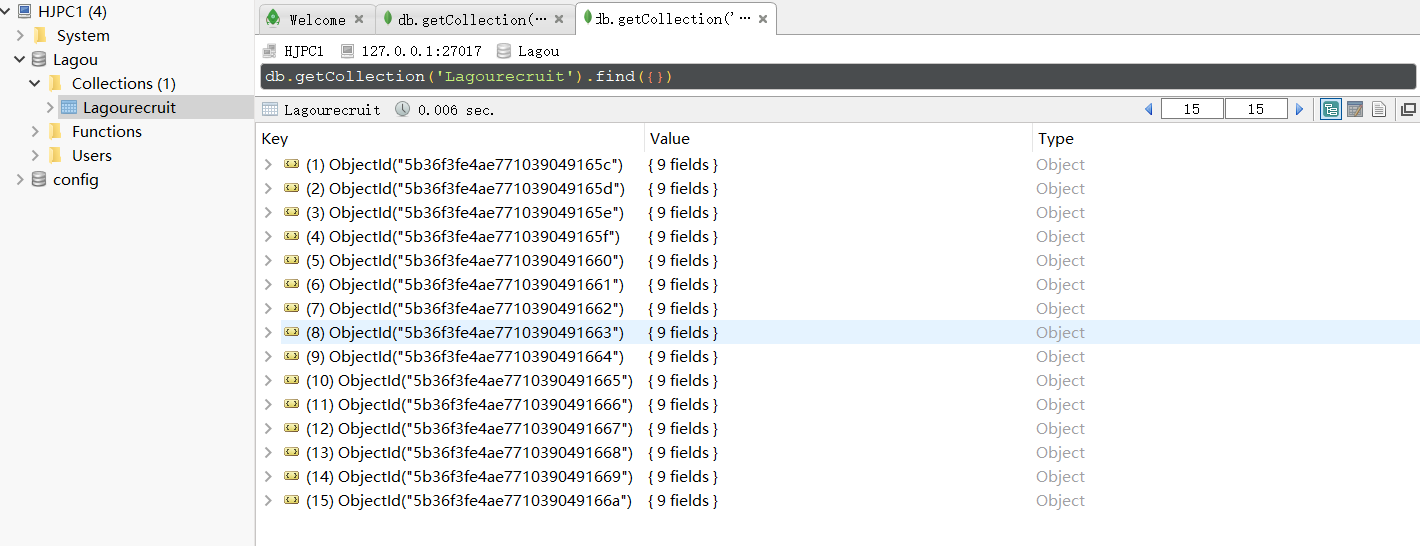
连接成功后,即可查阅数据库内容,如下图所示.
END