scrapy 持久化存储
一.主要过程:
以爬取校花网为例 :
http://www.xiaohuar.com/hua/
1. spider
回调函数 返回item 时 要用yield item 不能用return item
爬虫 xiahua.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from ..items import XiaohuaItem 4 5 class XiahuaSpider(scrapy.Spider): 6 name = 'xiahua' # 该名字 启动爬虫: scrapy crawl xiaohua --nolog 7 allowed_domains = ['xiaohuar.com'] 8 start_urls = ['http://www.xiaohuar.com/hua/'] # 起始url列表 9 10 # 默认的回调函数 11 def parse(self, response): 12 # 进行解析 13 # print(response.text) 14 items=response.xpath('//*[@id="list_img"]/div/div[1]/div/div/div[1]') 15 # 持久化存储 16 17 for tag in items: 18 dic={} 19 name=tag.xpath("./span[1]/text()").extract_first() 20 url=tag.xpath("./a[1]/@href").extract_first() 21 if name: # 姓名存在是存入数据库 22 item = XiaohuaItem() 23 dic["name"] = name 24 dic["url"]=url 25 item['name']=name 26 item['url']=url 27 print(dic) 28 29 yield item # 需要注意的: 不能是 return item
2. items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class XiaohuaItem(scrapy.Item): # define the fields for your item here like: name=scrapy.Field() url=scrapy.Field()
3.pipeline.py
1. 到settings 中 :
(1)ROBOTSTXT_OBEY = False # 改为Flase
(2)放开 ITEM_PIPELINES和修改机器人协议
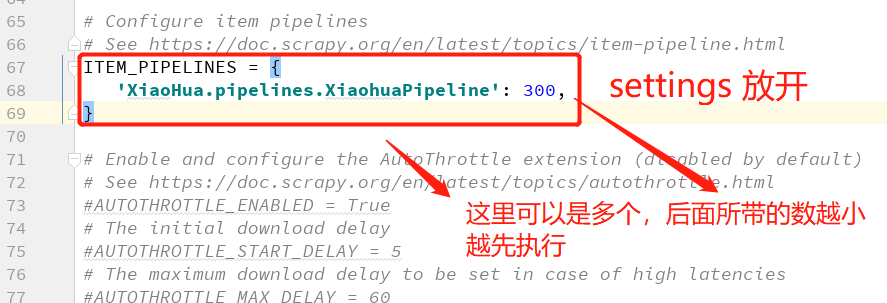
2. 数据持久化储存:
方式一: 不去配置文件取值的方式:
存数据库之前,先启动数据库服务端
必须先将item对象转化为字典 dict(item) 存入数据库
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymongo class XiaohuaPipeline(object): def __init__(self): self.client=None self.db=None def process_item(self, item, spider): # 持久化储存 #将数据存入数据库 self.db.xiahua.insert(dict(item)) # 必须先将item对象转化为字典 return item def open_spider(self,spider): # 爬虫开始 打开数据库 # 连接MongoDB服务端 self.client = pymongo.MongoClient(host="localhost",port=27017) # 连接数据库 self.db = self.client.spider print("爬虫开始-------") def close_spider(self,spider): # 关闭数据库 print('爬虫结束-----') self.client.close()
方式二 : 数据库配置到配置文件中的写法:
用到 类中的一个函数,如果该类是先找 ,自己是否定义了 from_crawler 类方法,
如果有自定义,则先执行该类方法,实例化一个对象。然后再执行 __init__ 方法。
1. settings.py 文件中配置以下信息:
### Mongdb配置参数 HOST="127.0.0.1" PORT=27017 USER="root" PWD="" DB="spider"
2. pipeline.py 中增加 类方法 from_crawler
# -*- coding: utf-8 -*- import pymongo class XiaohuaPipeline(object): @classmethod def from_crawler(cls, crawler): """ Scrapy会先通过getattr判断我们是否自定义了from_crawler,有则调它来完 成实例化 """ HOST = crawler.settings.get('HOST') PORT = crawler.settings.get('PORT') USER = crawler.settings.get('USER') PWD = crawler.settings.get('PWD') return cls(HOST, PORT, USER, PWD) # 返回实例化对象 def __init__(self, host, port, user, pwd): self.host = host self.port = port self.user = user self.pwd = pwd self.db = None def process_item(self, item, spider): #将数据存入数据库 print(type(dict(item))) self.db.xiahua.insert_one(dict(item)) # xiahua 为文档名(表名) return item def open_spider(self,spider): # 爬虫开始 打开数据库 # 连接MongoDB服务端 self.client = pymongo.MongoClient(host=self.host,port=self.port) # 连接数据库 self.db = self.client.spider print("爬虫开始-------") def close_spider(self,spider): # 关闭数据库 print('爬虫结束-----') self.client.close()
总结:
1. 先找 from_crawl 类方法, 有就先执行该该方法,返回一个实例化对象,再执行 __init__ 方法。
2. pipeline 类下,主要有5中方法:
from_crawl : 实例化一个对象 返回 # 该方法 去配置文件中取值时需要写
__init__ : 初始化
open_spider 爬虫开始 时执行 ( 数据库开启)
process_item 持久化存储 处理 (存数据)
close_spider 爬虫结束执行 (数据库关闭)