这里提供两种项目的下载方式:
【1】点击链接:github下载
【2】点击链接,腾讯微云下载 (密码:54250p)
抓取数据前的分析:
初始分析,需要的数据在如下所示的url对应的请求中
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1580981613956&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
如下图所示,借助Chrome插件 JSON Viewer可以很方便的查看返回的Json数据,并可以大致发现,url中,countryId对应着国家的id号,从1-19分别对应从中国到阿联酋,cityId对应城市,而timestamp时间戳以及bgIds,categoryId,parentCategoryId,attrId,keyword,language,area可以省略不写,这里的pageIndex=1&pageSize=10不难猜到就是第几页以及一页显示多少条数据。
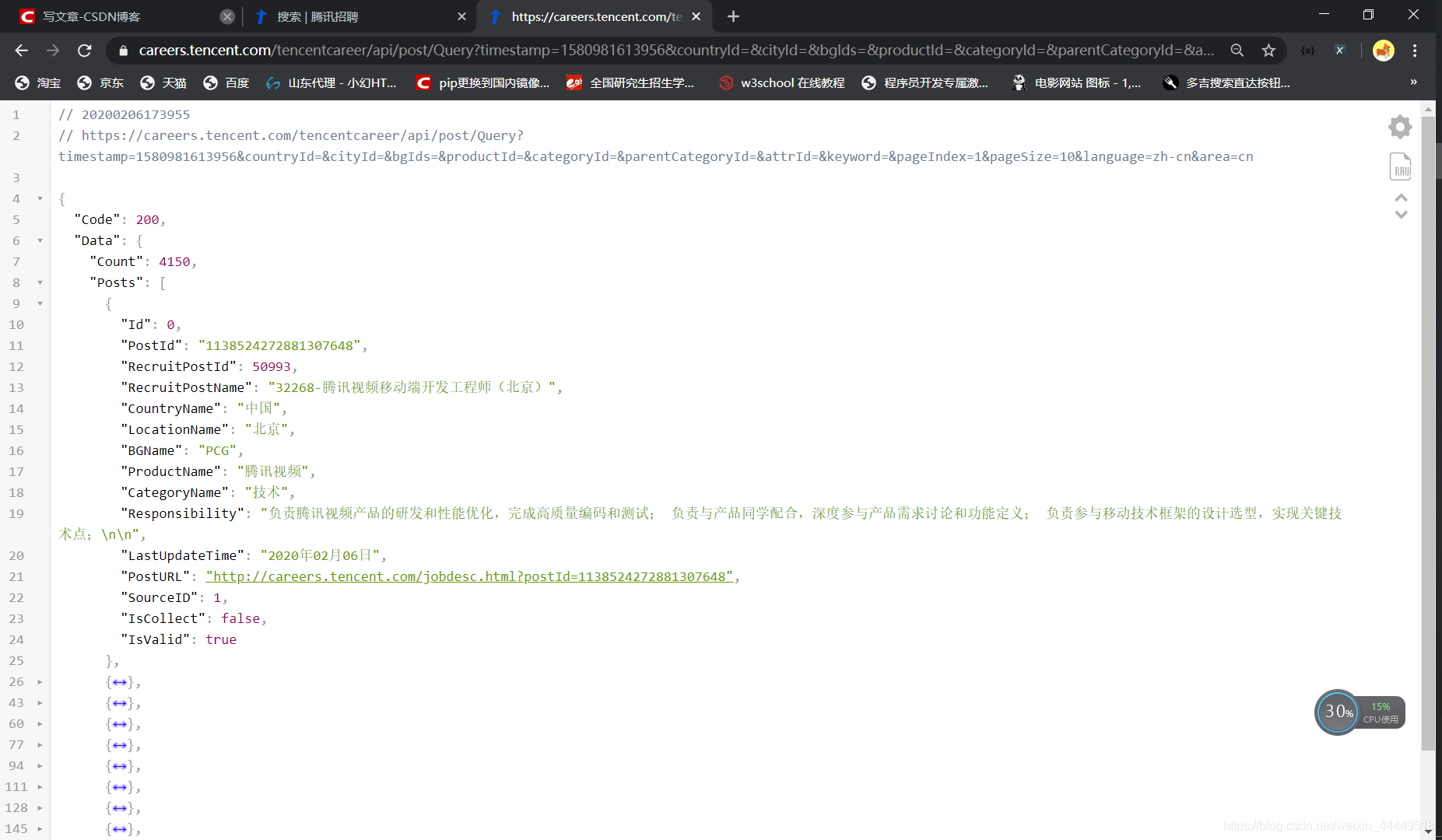
通过数据中的“Count”以及刚刚说的pageIndex可以让数据达到翻页的效果,以及判断是否为最后一页,停止下一页请求。这里我做了如下图所示的处理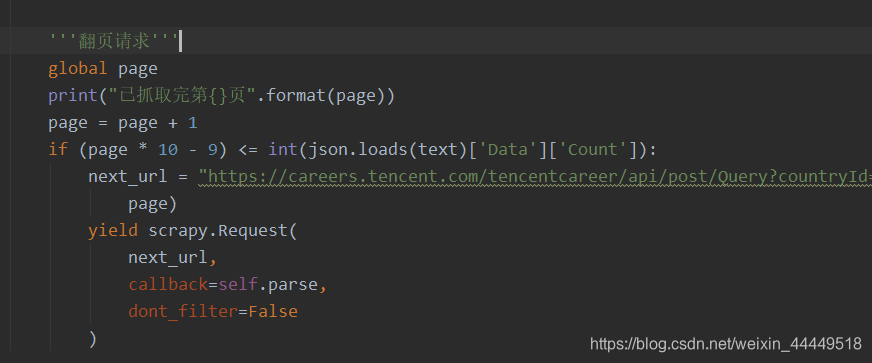
对于数据的提取以及放到Mongodb数据库立就很简单了。这里就不再多说了。还有就是数据提取的时候,会遇到\r\n以及空字符串等这样的垃圾字符,需要进行数据的简单清洗,这里就直接用正则表达式做的,如下图所示: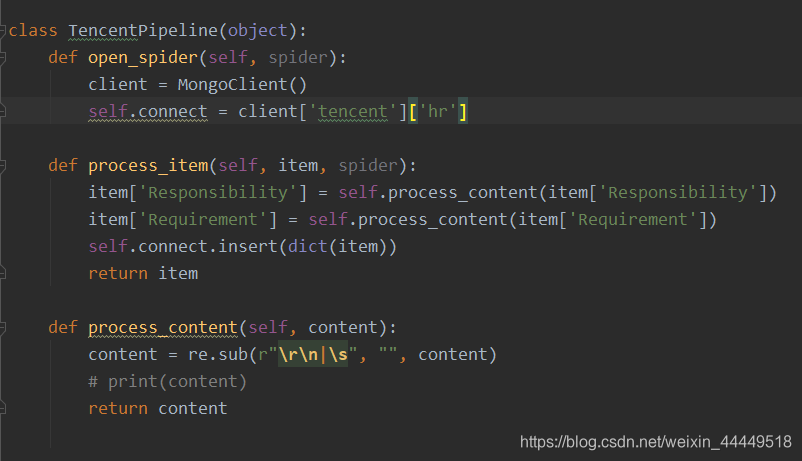
上面我补充了一条就是请求二级url进行“职位详情信息”的提取,这里做的是如下图所示的工作,列表取数据,数据进行二次发起请求。
下面的是上图中的 parse_detail 处理详情页提取招聘详情信息的函数
另外还有,请求中过滤请求过的url实现简单的增量爬虫
以上就是实现腾讯招聘爬虫,进行数据提取的大体流程以及各简单分析,相对来说还是很容易实现的。
下面就是保存在MongoDB中的数据:我只让他爬了一小部分,速度非常快,基本上每秒钟爬两三页,增加20多条数据的样子,十几秒钟147页,1470条数据已经提取完成了,速度是无法想象的以至于有点变态,要是家里网速再再快点就更快了。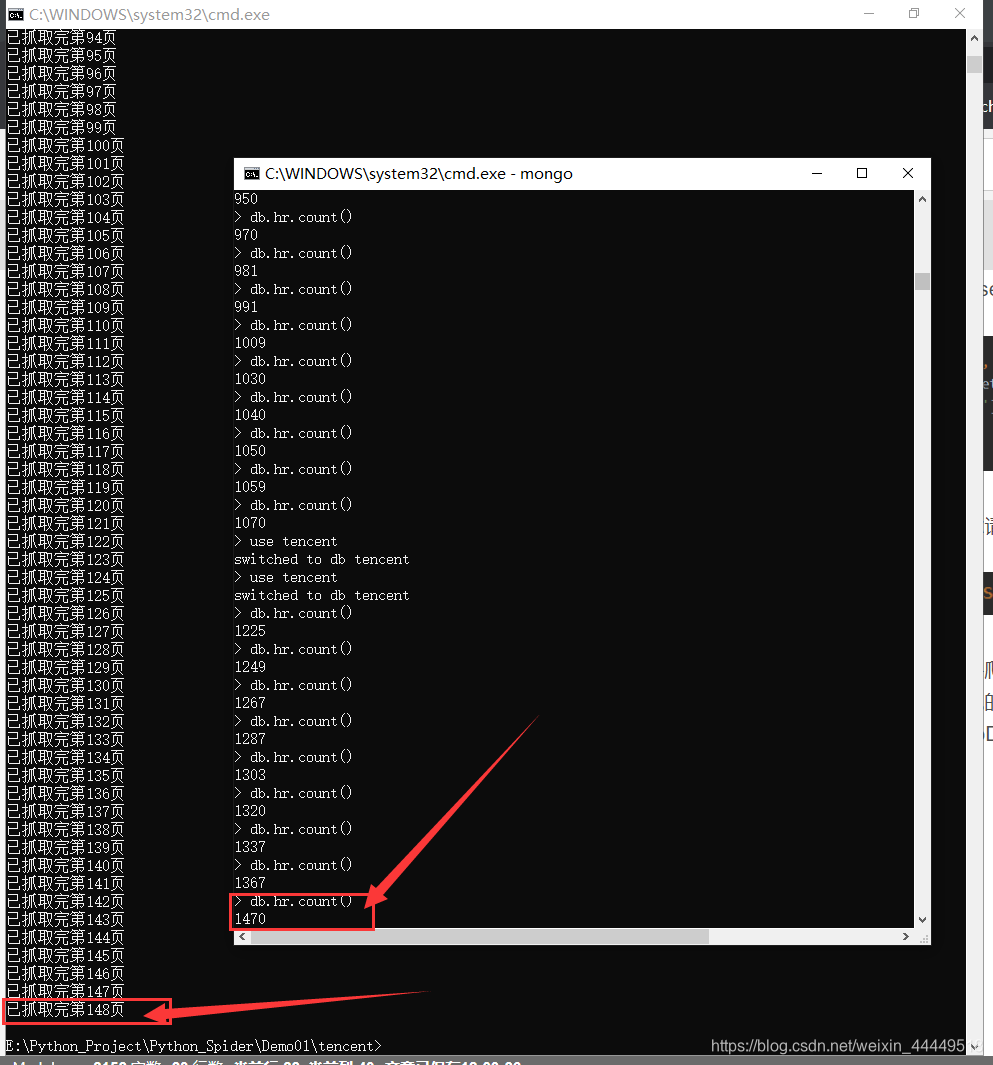
嗯。。。多少展示几条提取到的数据: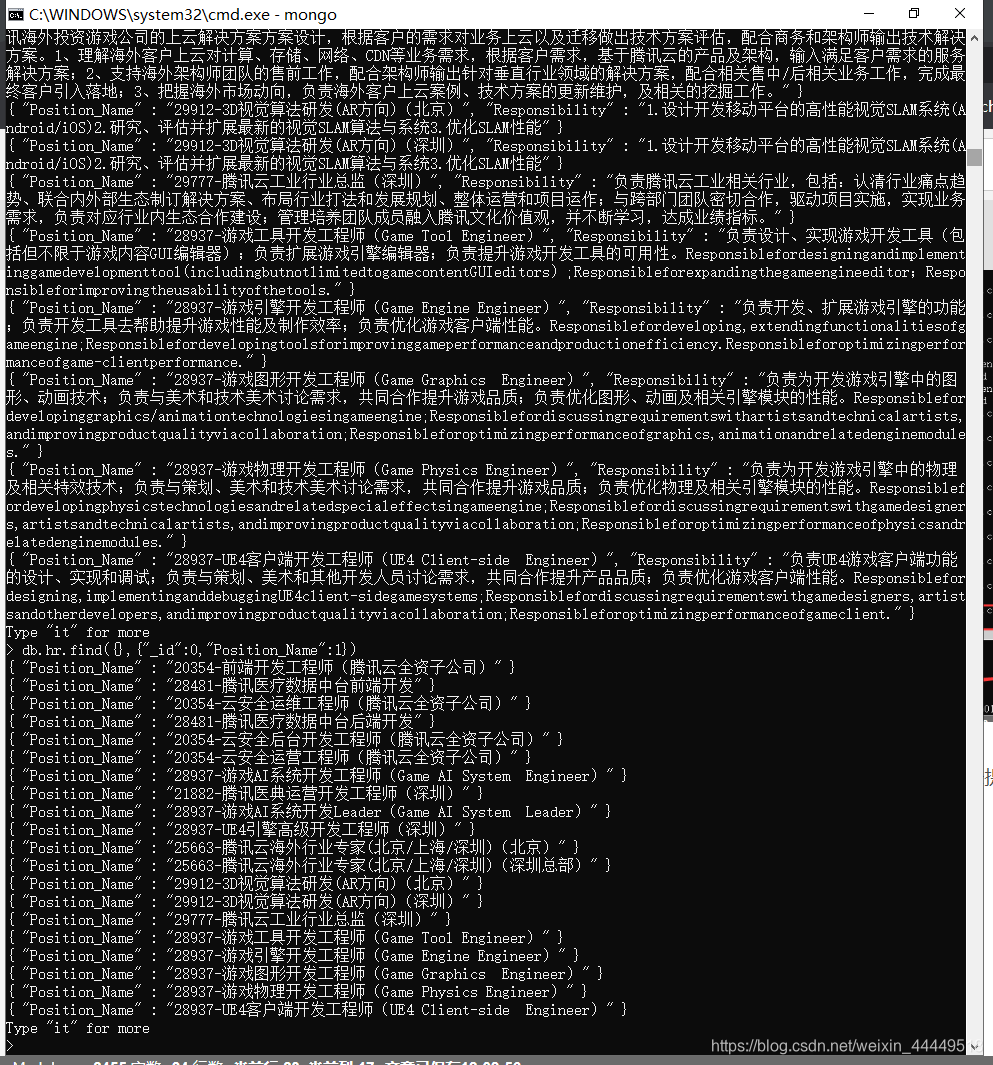
数据挺纯净的,还不错。
