目标:用Scrapy框架爬取帖子的编号、标题、内容、url,存储到Mongodb数据库
1.定义项目所需爬取的字段( items.py )
import scrapy
# 定义项目所需爬取的字段
class ComplaintspiderItem(scrapy.Item):
# 帖子编号
number = scrapy.Field()
# 帖子题目
title = scrapy.Field()
# 帖子内容
content = scrapy.Field()
# 帖子链接
url = scrapy.Field()
2.爬网页数据,取出item结构化数据(spiders/complaint.py)
import scrapy
from ComplaintSpider.items import ComplaintspiderItem
class ComplaintSpider(scrapy.Spider):
name = 'complaint'
# 设置爬取的域名范围,可省略,不写则表示爬取时候不限域名,结果有可能会导致爬虫失控
allowed_domains = ['wz.sun0769.com']
url = 'http://wz.sun0769.com/index.php/question/questionType?type=4&page='
offset = 0
start_urls = [url + str(offset)]
# 解析返回的网页数据,提取结构化数据,生成需要下一页的URL请求
def parse(self, response):
# 取出每个页面里帖子链接列表
links = response.xpath("//div[@class='greyframe']/table//td/a[@class='news14']/@href").extract()
# 迭代发送每个帖子的请求,调用 parse_item 方法处理
for link in links:
yield scrapy.Request(link, callback=self.parse_item)
# 设置页码终止条件,并且每次发送新的页面请求调用 parse 方法处理
if self.offset <= 71130:
self.offset += 30
yield scrapy.Request(self.url + str(self.offset), callback=self.parse)
# 封装数据
def parse_item(self, response):
# 将得到的数据封装到 SunspiderItem
item = ComplaintspiderItem()
# 标题
item['title'] = response.xpath('//div[contains(@class,"pagecenter p3")]//strong/text()').extract()[0]
# 编号
item['number'] = item['title'].split(' ')[-1].split(":")[-1]
# 文字内容,默认先取出有图片情况下的文字内容列表
content = response.xpath('//div[@class="contentext"]/text()').extract()
# 若没有内容,则取出没有图片情况下的文字内容列表
if len(content) == 0:
content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()
# content 为列表,通过 join 方法拼接为字符串,并去除首尾空格
item['content'] = "".join(content).strip()
else:
item['content'] = "".join(content).strip()
# 链接
item['url'] = response.url
yield item
3.设计item pipeline来提取存储item结构化数据(pipelines.py)
from scrapy.conf import settings
import pymongo
class ComplaintspiderPipeline(object):
def __init__(self):
# 获取setting主机名、端口号和数据库名
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME']
# pymongo.MongoClient(host, port) 创建MongoDB链接
client = pymongo.MongoClient(host=host,port=port)
# 指向指定的数据库
mdb = client[dbname]
# 获取数据库里存放数据的表名
self.post = mdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
data = dict(item)
# 向指定的表里添加数据
self.post.insert(data)
return item4.启用item pipeline 组件,补充相关配置(settings.py)
BOT_NAME = 'ComplaintSpider'
SPIDER_MODULES = ['ComplaintSpider.spiders']
NEWSPIDER_MODULE = 'ComplaintSpider.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'ComplaintSpider.pipelines.ComplaintspiderPipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36'
# MONGODB 主机环回地址127.0.0.1
MONGODB_HOST = '127.0.0.1'
# 端口号,默认是27017
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = 'Complaint'
# 存放本次数据的表名称
MONGODB_DOCNAME = 'invitation'
5.启动爬虫,测试(main.py)
from scrapy import cmdline
# 注意:complaint 为spiders下爬取网页的代码
cmdline.execute('scrapy crawl complaint'.split())
此步可以省略,可以在 Terminal 直接运行 scrapy crawl complaint
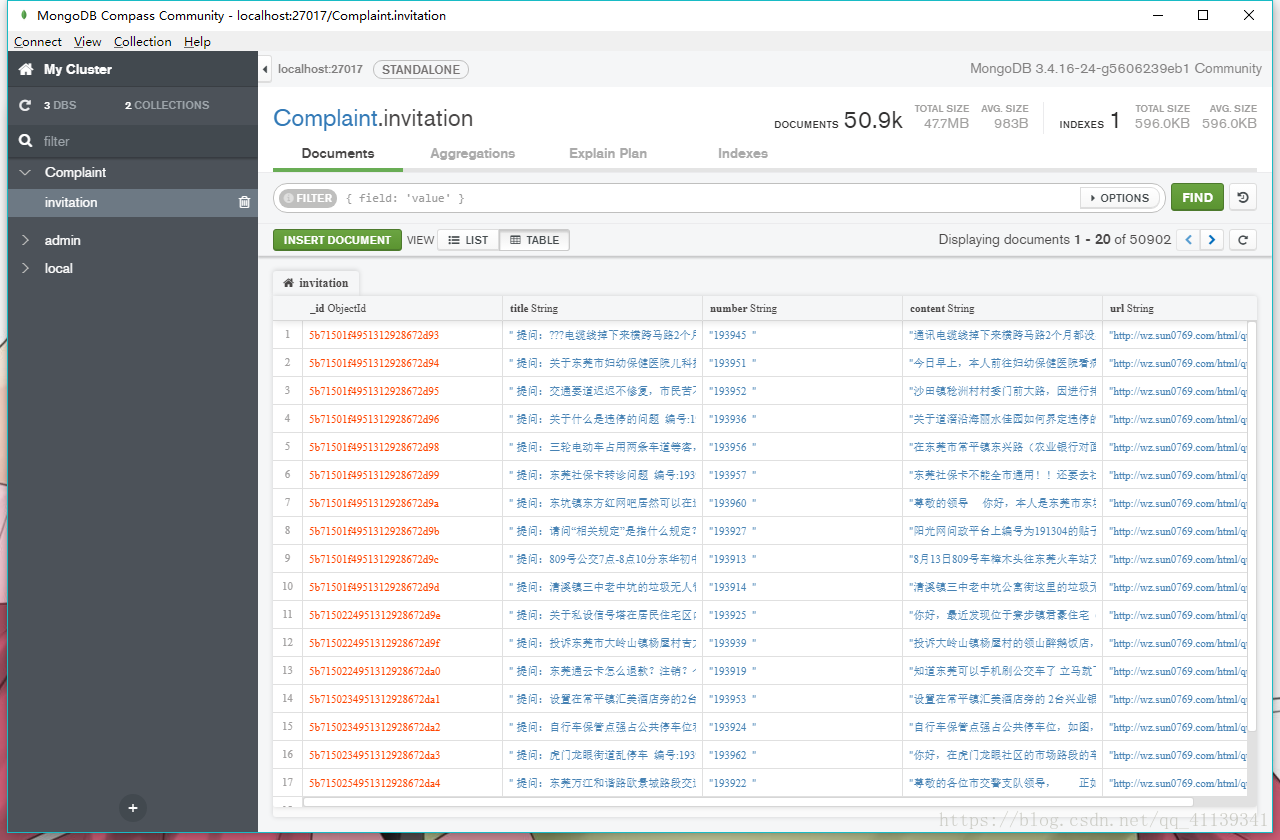
库名为 Complaint,表名为 invitation 的 Mongodb 数据库 就有了
