根据学习Stanford university的cs231n课堂视频,我做了一下总结~
sigmoid
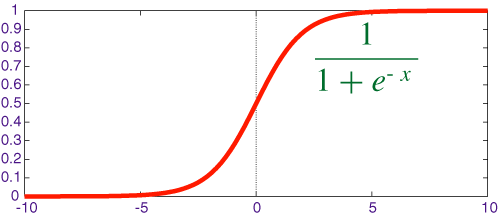
- 原来挺流行,与大脑神经元的运作很类似
- 饱和神经元将使得梯度消失。输入一个绝对值很大的数,其梯度接近于0,通过链式法则后会让梯度流消失,就无法得到反馈
- 是一个非零中心的函数。梯度更新的效率低
- 使用了指数函数,计算代价不低
tanh(x)
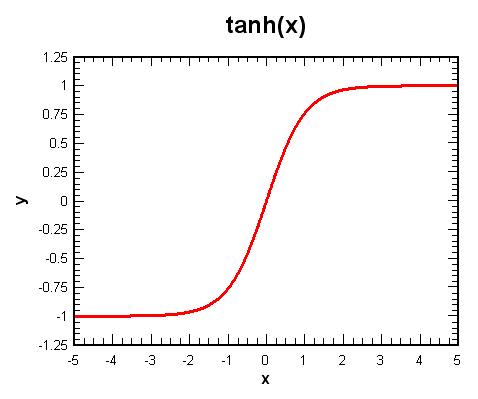
双曲正切函数
- 零均值
- 绝对值很大的输入会使梯度消失
ReLU
线性整流函数
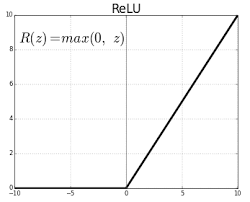
- 不会产生饱和现象
- 计算成本低
- 收敛速度快(约6倍)
- 更具备生物学的合理性
- 不是零均值
- 一般来说,将偏置项初始化为0。不过有时可以使用较小的正偏值来初始化ReLU, 以增加它在初始化时被激活的可能性,并获得一些更新
Leaky ReLU
与PRuLU
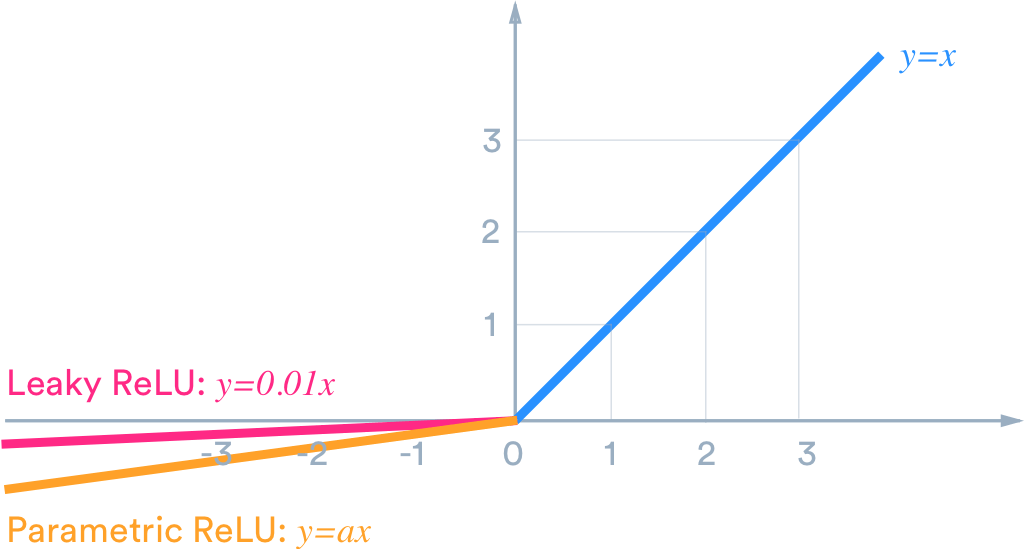
f(x) = max(0.01x, x)
f(x) = max(ax, x) (a不需要指定,是一个反向传播和学习的参数)
- 没有饱和空间
- 计算成本低
- 迭代速度快
ELU
(Exponential Linear Units)
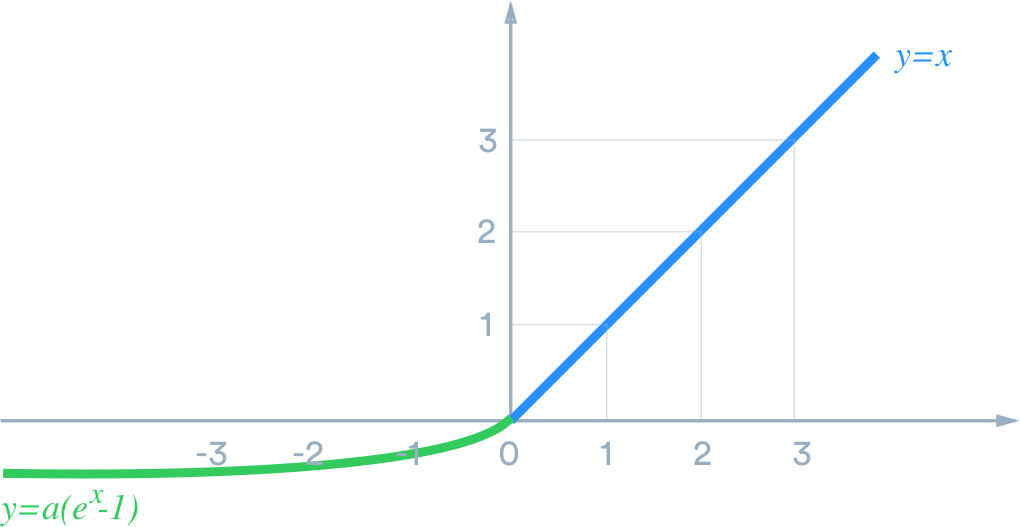
- 具有ReLU的所有优点
- 接近于零均值
- 存在负饱和机制,当输入值为绝对值较大的负数时梯度为0(对噪声有更强的鲁棒性)
- 计算成本稍高
通常来说
使用RuLU就比较好,注意仔细考虑学习速率。
有时可以尝试Leaky ReLU, ELU, tanh. 但不要对tanh抱有太大期望。它们的实用性不够强。
最好不再用sigmoid了