【赛题描述】
本次赛题需要选手利用历史某3年的汽车日上牌数据,预测某2年每天的汽车上牌数。初赛将挑选出5个汽车品牌,给出这些品牌每天的上牌数,当天是星期几,来预测5个汽车品牌未来每天的上牌总数。
【数据说明】


【题目分析】
首先,本次比赛的题目是一个预测问题,从过去数据中找到某种规则并对之后的事件进行预测。
其次,从训练集可以看到,每条样本有四个属性,date是一个从1到n的连续值;day_of_week是一个离散属性,属性值包含1到7;brand也是一个离散属性,属性值包含1到5;cnt即为我们的目标属性也就是当天的汽车上牌量(整数)。
请注意:提交结果只需预测当天物种测量的总上牌量即可,而并不需要预测出5种车辆相应的上牌量。
【本文方法】
通过探索性分析找出样本潜在属性来替代date,将预测问题转化为一个回归问题,将最后的预测值取整得到结果
-------------------------------------------------------------------分 割 线-----------------------------------------------------------------
【一般数据挖掘流程】
1、定义问题:即分析问题,确定问题的属性
2、收集数据:本册竞赛已经给出了数据集,在网站上下载即可
3、数据清洗:将数据集中的缺失项,异常值进行优化处理,保证后续工作正常开展
4、进行探索性分析(EDA):通过图形化数据分析找出潜在问题
5、模型选择:既选择处与问题相匹配的机器学习算法
6、模型拟合与优化处理
-------------------------------------------------------------------分 割 线-----------------------------------------------------------------
【探索性分析】
1、先将同一天的汽车上牌量总数求出来:
import pandas as pd
import numpy as np
data = pd.read_table('C:/Users/zhj/Desktop/tianchi/LableOfCars/train_20171215.txt')
#将不同型号汽车在同一天的上牌量相加,得到date不重复的数据矩阵
sumcnt = np.zeros(data.date.max(),dtype = 'int16')
udate = np.zeros(data.date.max(),dtype = 'int16')
for element in range(0,data.date.max()):
udate[element] = element+1
for element in range(0,data.shape[0]):
date = data.date[element]
cnts = data.cnt[element]
sumcnt[date-1] = sumcnt[date-1] + cnts
#print(sumcnt)
week_day = np.zeros(data.date.max(),dtype = 'int16')
for element in range(0,data.shape[0]):
date = data.date[element]
week = data.day_of_week[element]
week_day[date-1] = week
#print(week_day)
unique_data = pd.DataFrame({'cnt':sumcnt,'date':udate,'day_of_week':week_day})
#print(unique_data)
#unique_data.to_csv('unique_train.csv',index=False)这一步得到一个表格,每个样本只有三个属性,即date、day_of_week、cnt(当天上牌数总量)
2、接下来将该表格那每天的上牌量进行散点图展示,利用matplotlib库中的scatter函数,代码如下:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('C:/Users/zhj/Desktop/tianchi/LableOfCars/unique_train.csv')
X = data.date
Y = data.cnt
fig = plt.figure()
plt.scatter(X,Y)
plt.show()散点结果如下:
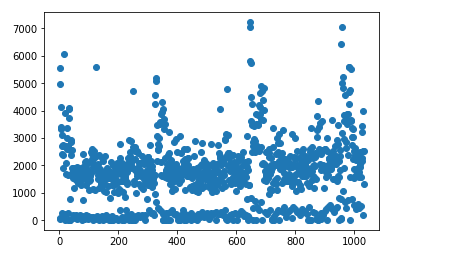
可以看出由于训练集是收集了三年的上牌信息,所以数据呈现一定的周期性。
3、与此同时,数据也呈现了一定的断层,也就是500以下有一部分样本,1000以上有一部分样本,考虑到周末与工作日节假日的区别,这些区别可能是导致了上牌量的极端分布,因此做了将工作日和周六周日进行分开散点,代码如下:
weekend = []
for element in range(0,data.shape[0]):
if data.day_of_week[element] == 6 or data.day_of_week[element] == 7:
weekend.append(element)
data_workday = data.drop(weekend)
data_weekend = data.loc[weekend]散点结果如下:
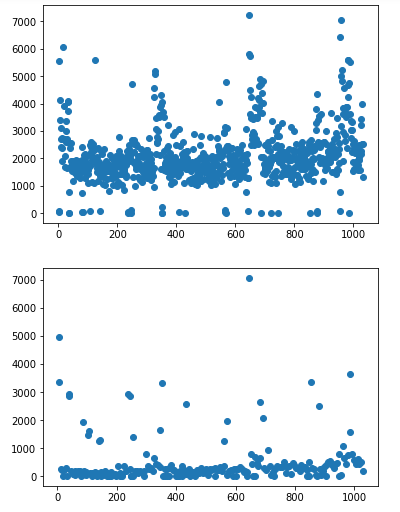
可以看到,工作日与周六周日的影响因素确实很大,但在三点钟也出现了反常的点,也就是三年内有几个工作日上牌量极少,而有几个周六或周日上牌量特别高,考虑到我国国情,有三八妇女节、五一劳动节、六一儿童节、十一国庆七天假、清明中秋等传统节日以及圣诞节等国外节日所在的星期不固定所导致以上情况。
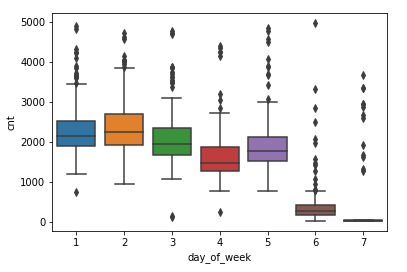
4、由于箱型图有信息量大,对异常值敏感等优点,接下来对星期1-7绘制箱型图,从而观察异常值,代码如下:
p = sns.boxplot(y = 'cnt',x = 'day_of_week',data = data)
plt.show()结果如下:
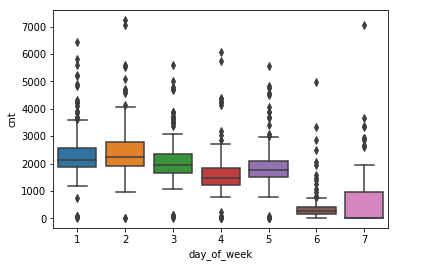
从图中可以看到,工作日五天之间存在细微的差别,周日的数据跨度大需要适度的处理。
【数据预处理】
1、通过阈值的方法剔除异常值,代码如下:
#剔除训练集离群点(cnt>5000的点,以及在工作日期间cnt<100的点)
import pandas as pd
import numpy as np
data = pd.read_csv('C:/Users/zhj/Desktop/tianchi/LableOfCars/train_season1.csv')
count = 0
dropa = []
for element in range(0,data.shape[0]):
if data.cnt[element] > 5000:
dropa.append(element)
count = count + 1
X = data.drop(dropa)
dropb = []
for element in range(0,X.shape[0]):
if data.day_of_week[element] < 6 and data.cnt[element] < 100:
dropb.append(element)
count = count + 1
X = X.drop(dropb)此时的DataFrame.shape=(990,4),即样本数量由原来的1032变成了990了
2、由于给定数据集中样本的date属性域是一个1到n的离散属性,也就是没一个样本的date值是唯一的,所以无法用作训练回归模型的自变量,然而除了date就只剩下day_of_week这一个自变量了,为了增加准确率,根据自然法则将样本划分成四个集合,分别表示春夏秋冬,同时考虑到训练集中包含三年的上牌数据,整体手动划分起来具有一定的困难,准确率也无法保障,于是采用了将三年数据通过date折叠成一年,样本数量保持不变,折叠代码如下:
a = data.cnt[0:330]
b = data.cnt[330:660]
c = data.cnt[660:990]
a_wd = data.day_of_week[0:330]
b_wd = data.day_of_week[330:660]
c_wd = data.day_of_week[660:990]
a_d = data.date[0:330]
b_d = data.date[330:660]
c_d = data.date[660:990]
a = a.as_matrix()
b = b.as_matrix()
c = c.as_matrix()
a_wd = a_wd.as_matrix()
b_wd = b_wd.as_matrix()
c_wd = c_wd.as_matrix()
a_d = a_d.as_matrix()
b_d = b_d.as_matrix()
c_d = c_d.as_matrix()
b_d = [i - data.date[329] for i in b_d]
c_d = [i - data.date[659] for i in c_d]
cnt1 = pd.DataFrame({'date':a_d,'cnt':a,'day_of_week':a_wd})
cnt2 = pd.DataFrame({'date':b_d,'cnt':b,'day_of_week':b_wd})
cnt3 = pd.DataFrame({'date':c_d,'cnt':c,'day_of_week':c_wd})
cnt = cnt1.append(cnt2)
cnt = cnt.append(cnt3)
#print(cnt)
cnt.to_csv('train_asoneyear.csv',index = False)其中data是之前一步的X,就是剔除掉离群点的训练集,对这个训练集进行散点结果如下:
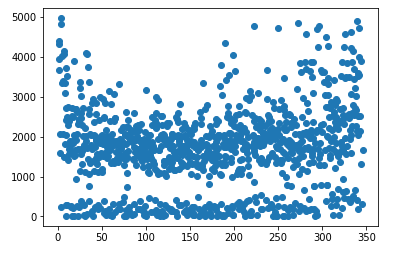
箱型图如下:
接下来给这些样本加上季节属性,代码如下:
#给训练集添加season属性(按中国的四季分)
import pandas as pd
import numpy as np
data = pd.read_csv('C:/Users/zhj/Desktop/tianchi/LableOfCars/train_asoneyear.csv')
date = data.date
date = date.as_matrix()
max_date = max(date)
#print(max_date) max_date = 346
day_season = np.zeros(data.shape[0],dtype = 'int64')
for element in range(0,data.shape[0]):
if data.date[element] <= 48:
day_season[element] = 4
elif data.date[element] <= 136:
day_season[element] = 1
elif data.date[element] <= 230:
day_season[element] = 2
elif data.date[element] <= 315:
day_season[element] = 3
else:
day_season[element] = 4
data = pd.DataFrame(data,columns = ['cnt','date','day_of_week','season'])
data.season = day_season
#print(data.shape)
data.to_csv('train_season_clear.csv',index = False)3、接下来进行测试集的预处理(由于训练集只有date和day_of_week两个属性,需要加上季节属性),代码如下:
day_season = np.zeros(data.shape[0],dtype = 'int64')
for element in range(0,data.shape[0]):
if data.real_date[element] >= 1 and data.real_date[element] <= 52:
day_season[element] = 4
elif data.real_date[element] >= 53 and data.real_date[element] <= 135:
day_season[element] = 1
elif data.real_date[element] >= 136 and data.real_date[element] <= 214:
day_season[element] = 2
elif data.real_date[element] >= 215 and data.real_date[element] <= 294:
day_season[element] = 3
else:
day_season[element] = 4
data = pd.DataFrame(data,columns = ['date','day_of_week','season'])
data.season = day_season
#print(data)
data.to_csv('testA_season.csv',index = False)【模型选择与拟合】
本文使用的是随机森林中的回归模型,并且通过改变随机种子改变训练计划分策略从而多次建模去预测值的平均值,代码如下:
import math
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.externals import joblib
data = pd.read_csv('C:/Users/zhj/Desktop/tianchi/LableOfCars/train_season_clear.csv')
test = pd.read_csv('C:/Users/zhj/Desktop/tianchi/LableOfCars/testA_season.csv')
X = data.drop('cnt',axis = 1)
X = X.drop('date',axis = 1)
y = data.cnt
test = test.drop('date',axis = 1)
#交叉检验,取训练集中的80%作为模型输入
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=100)
pipeline = make_pipeline(preprocessing.StandardScaler(),
RandomForestRegressor())
#网格搜索取最优参数组合
hyperparameters = { 'randomforestregressor__max_features' : ['auto', 'sqrt','log2'],
'randomforestregressor__max_depth': [None, 5, 3, 1],
'randomforestregressor__n_estimators':[100,200,300,400,500]}
clf = GridSearchCV(pipeline, hyperparameters, cv=10)
clf.fit(X_train, y_train)
pred = clf.predict(test)
pred = pred[:,np.newaxis]
#改变随机种子从而改变模型输入
for circle in range(101,120):
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=circle)
pipeline = make_pipeline(preprocessing.StandardScaler(),
RandomForestRegressor())
hyperparameters = { 'randomforestregressor__max_features' : ['auto', 'sqrt', 'log2'],
'randomforestregressor__max_depth': [None, 5, 3, 1],
'randomforestregressor__n_estimators':[100,200,300,400,500]}
clf = GridSearchCV(pipeline, hyperparameters, cv=10)
clf.fit(X_train, y_train)
a = clf.predict(test)
a = a[:,np.newaxis]
pred = np.concatenate((pred,a),axis=1)
print(pred.shape)
#预测结果取平均
pred = pred.sum(axis = 1)
pred = pred/20
result = []
for element in pred.flat:
element = int(element)
result.append(element)
index_test = range(1032,1308)
save = pd.DataFrame({'date':index_test,'cnt':result})
save = pd.DataFrame(save,columns = ['date','cnt'])
save.date = index_test
save.cnt = result
save.to_csv('SecondPred_20rollMeans.csv',index=False)-------------------------------------------------------分 割 线---------------------------------------------------
【总结】
这种方法得到的结果提交之后的mse是949103.8043,初赛排名在2635个队伍中排名268,第一次参赛没有多少经验,能有这样的结果也很欣慰。回到赛题,以上所述这种方法还存在很多不足的地方,比如,对三年样本的折叠策略存在误差;季节划分上存在误差;非周六周日的节假日并没有被考虑在内;迭代次数较少等。
这次的参赛经历拓宽了视野,对Python以及其机器学习库有了较多的认识,对机器学习算法有了更深入的理解,在以后的学习工作中还会积累些时间序列数据挖掘方面的知识,积极参加相关竞赛增加阅历~