前言
3.1.3 issueDate及earliesCreditLine处理
前言
通过本次比赛的学习,让自己在数据分析及挖掘的技能上又有了进一步提高,虽然最终成绩只有0.7346,但这个过程的经验积累价值是不可估量的,本人是第一次处理这么大量的数据,自己摸索的同时,又不断学习许多前辈的经验,让自己在大数据处理方面又有了新的认知。
一、赛题介绍
赛题以金融风控中的个人信贷为背景,要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款,这是一个典型的分类问题。通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助竞赛新人进行自我练习、自我提高。
该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
数据变量特征解释如下

二、数据描述性统计
2.1.读取数据
import pandas as pd # 数据分布统计
df=pd.read_csv("/train.csv")
test=pd.read_csv("/testA.csv")
df.shape
(800000, 47) 训练集有80万个样本,47个变量
2.2.查看重复值
df[df.duplicated()==True]#打印重复值0 rows × 47 columns 无重复值
2.3.统计目标变量比例
(df['isDefault'].value_counts()/len(df)).round(2)0 0.8 1 0.2
目标变量比例1:4,样本类别不平衡
2.4.查看数据的统计量
df.describe().T
n系列特征都有缺失,贷款金额及年收入等涉及金额的数据标准差都比较大,波动性大 。
2.5.统计每个变量的种类
df.nunique()
df=df.drop(['id','policyCode'],axis=1) # 删除ID列及只有一个值的policyCode列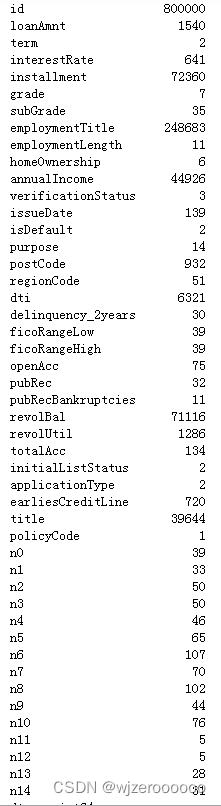
2.6.查看训练集与测试集的特征分布是否一致
# 分离数值变量与分类变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns) # 数值变量
Ca_feature = list(df.select_dtypes(include=['object']).columns)
# 查看数值型训练集与测试集分布
Nu_feature.remove('isDefault') # 移除目标变量
# 画图
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(30,30))
i=1
for col in Nu_feature:
ax=plt.subplot(8,5,i)
ax=sns.distplot(df[col],color='violet')
ax=sns.distplot(test[col],color='lime')
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax=ax.legend(['train','test'])
i+=1
plt.show()
由于变量较多,只展示了部分变量,分布是一致的, 如果训练集与测试集分布不一致,会影响模型泛化性能,就好比训练的是老人的特征,结果是预测小孩的特征。
2.7 查看数据相关性
plt.figure(figsize=(10,8))
train_corr=df.corr()
sns.heatmap(train_corr,vmax=0.8,linewidths=0.05,cmap="Blues")
部分特征相关性比较高,目标变量与特征变量之间没有特别高的相关性
三、数据清洗
3.1.分类变量处理
Ca_feature:['grade', 'subGrade', 'employmentLength', 'issueDate', 'earliesCreditLine']
3.1.1 grade及subGrade处理
from sklearn.preprocessing import LabelEncoder
lb = LabelEncoder()
cols = ['grade','subGrade']
for j in cols:
df[j] = lb.fit_transform(df[j])
df[cols].head()
#grade及subGrade是有严格的字母顺序的,与测试集相对应,可以直接用编码转换,转换结果如下
grade subGrade
0 4 21
1 3 16
2 3 17
3 0 3
4 2 113.1.2 employmentLength处理
# 年限转化为数字,在进行缺失值填充
df['employmentLength']=df['employmentLength'].str.replace(' years','').str.replace(' year','').str.replace('+','').replace('< 1',0)
# 随机森林填补年限缺失值 由于分类变量只有年限有缺失,所以这样填充
from sklearn.tree import DecisionTreeClassifier
DTC = DecisionTreeClassifier()
empLenNotNull = df.employmentLength.notnull()
columns = ['loanAmnt','grade','interestRate','annualIncome','homeOwnership','term','regionCode']
# regionCode变量加入后,准确度从0.85提升至0.97
DTC.fit(df.loc[empLenNotNull,columns], df.employmentLength[empLenNotNull])
print(DTC.score(df.loc[empLenNotNull,columns], df.employmentLength[empLenNotNull]))
# DTC.score:0.9828872204324179
# 填充
for data in [df]:
empLen_pred = DTC.predict(data.loc[:,columns]) # 对年限数据进行预测
empLenIsNull = data.employmentLength.isnull() # 判断是否为空值,isnull返回的是布尔值
data.employmentLength[empLenIsNull] = empLen_pred[empLenIsNull] # 如果是空值进行填充
# 转化为整数
df['employmentLength']=df['employmentLength'].astype('int64')3.1.3 issueDate及earliesCreditLine处理
import datetime
df['issueDate']=pd.to_datetime(df['issueDate'])
df['issueDate_year']=df['issueDate'].dt.year.astype('int64')
df['issueDate_month']=df['issueDate'].dt.month.astype('int64')
df['earliesCreditLine']=pd.to_datetime(df['earliesCreditLine']) # 先在EXCEL上转化为日期
df['earliesCreditLine_year']=df['earliesCreditLine'].dt.year.astype('int64')
df['earliesCreditLine_month']=df['earliesCreditLine'].dt.month.astype('int64')
df=df.drop(['issueDate','earliesCreditLine'],axis=1)
# issueDate及earliesCreditLine两个变量将日期分解,分别提取‘年’和‘月’并转化为整数便于计算,由于测试集这两个变量的‘日’都是1,对目标变量没有影向,所以训练集不提取,提取完后将这两个原始变量删除3.2 数值变量填充
df[Nu_feature] = df[Nu_feature].fillna(df[Nu_feature].median())
# 考虑平均值易受极值影响,数值变量用中位数填充3.3 保存数据
df.to_csv("/df2.csv")说明:测试集也需要做相同的处理
四、特征探索
4.1 PCA主成分分析
from sklearn.decomposition import PCA
pca = PCA()
X1=df2.drop(columns='isDefault')
df_pca_train = pca.fit_transform(X1)
pca_var_ration = pca.explained_variance_ratio_
pca_cumsum_var_ration = np.cumsum(pca.explained_variance_ratio_)
print("PCA 累计解释方差")
print(pca_cumsum_var_ration)
x=range(len(pca_cumsum_var_ration))
plt.scatter(x,pca_cumsum_var_ration)
###################
PCA 累计解释方差
[0.6785479 0.96528967 0.99287836 0.99667955 0.9999971 0.99999948
0.99999985 0.99999993 0.99999995 0.99999996 0.99999998 0.99999998
0.99999999 0.99999999 0.99999999 1. 1. 1.
1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1.
1. 1. 1. ]

可以看到前两个变量累计就达到接近1的方差贡献率,降维效果明显,但不适用于建模。
4.2 Toad: 基于 Python 的标准化评分卡模型
4.2.1 toad_quality
import toad
toad_quality = toad.quality(df2, target='isDefault', iv_only=True)
# 计算各种评估指标,如iv值、gini指数,entropy熵,以及unique values,结果以iv值排序
# iv
subGrade 0.485106565
interestRate 0.463530061
grade 0.463476859
term 0.172635079
ficoRangeLow 0.125252862
ficoRangeHigh 0.125252862
dti 0.072902752
verificationStatus 0.054518912
n14 0.045646121
loanAmnt 0.040412211
installment 0.039444828
title 0.034895535
issueDate_year 0.034170341
homeOwnership 0.031995853
n2 0.031194387
n3 0.031194387
annualIncome 0.030305725
n9 0.029678353
employmentTitle 0.028019829
revolUtil 0.025677543
上面展示了IV值大于0.02的特征,IV值小于0.02的特征对目标变量几乎没有作用,本人已测试仅用上述特征建模,模型效果没有全部特征好
4.2.2 toad.selection.select
selected_data, drop_lst= toad.selection.select(df2,target = 'isDefault', empty = 0.5, iv = 0.02, corr=0.7,return_drop=True)
# 筛选空值率>0.5,IV<0.02,相关性大于0.7的特征
# (800000, 15) 保留了15个特征
# 以下是删除的特征,通过return_drop=True显示
{'empty': array([], dtype=float64),
'iv': array(['employmentLength', 'purpose', 'postCode', 'regionCode',
'delinquency_2years', 'openAcc', 'pubRec', 'pubRecBankruptcies',
'revolBal', 'totalAcc', 'initialListStatus', 'applicationType',
'n0', 'n1', 'n4', 'n5', 'n6', 'n7', 'n8', 'n10', 'n11', 'n12',
'n13', 'issueDate_month', 'earliesCreditLine_year',
'earliesCreditLine_month'], dtype=object),
'corr': array(['n9', 'grade', 'n3', 'installment', 'ficoRangeHigh',
'interestRate'], dtype=object)}通过筛选的特征用于建模,效果也不好
4.2.3 psi:比较训练集和测试集的变量分布之间的差异
psi = toad.metrics.PSI(df2,testA) # psi没有大于0.25的,都比较稳定
psi.sort_values(0,ascending=False)
##############部分结果展示##############
revolBal 2.330739e-01
installment 1.916890e-01
employmentTitle 1.513944e-01
employmentLength 6.919465e-02
annualIncome 4.075954e-02
dti 2.810131e-02
title 1.875967e-02特征工程是机器学习中不可或缺的一部分,也是十分庞杂的工程,本人也只是做了简单的尝试。
五、数据建模
本人对比了xgboost及catboost,最终选择了catboost,尝试结果如下:
| RandomForestClassifier+xgboost | AUC 测试0.721/线上0.71 |
| xgboost+toad | AUC 测试0.722 |
| catboost+toad | AUC 测试0.727 |
| catboost+类别变量 | AUC 测试0.736/线上0.72 |
| catboost+5KFold+500iterations | AUC 测试0.734/线上0.728 |
| catboost+3KFold+300iterations+增加类别变量 | AUC 测试0.738/线上0.7346 |
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier
from sklearn.model_selection import KFold
train=pd.read_csv("/df2.csv")
testA2=pd.read_csv("/testA.csv")
# 选取相关变量做分类变量并转化为字符串格式
col=['grade','subGrade','employmentTitle','homeOwnership','verificationStatus','purpose','issueDate_year','postCode','regionCode','earliesCreditLine_year','issueDate_month','earliesCreditLine_month','initialListStatus','applicationType']
for i in train.columns:
if i in col:
train[i] = train[i].astype('str')
for i in testA2.columns:
if i in col:
testA2[i] = testA2[i].astype('str')
# 划分特征变量与目标变量
X=train.drop(columns='isDefault')
Y=train['isDefault']
# 划分训练及测试集
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=123)
# 模型训练
clf=CatBoostClassifier(
loss_function="Logloss",
eval_metric="AUC",
task_type="CPU",
learning_rate=0.1,
iterations=300,
random_seed=2022,
od_type="Iter",
depth=7)
result = []
mean_score = 0
n_folds=3
kf = KFold(n_splits=n_folds ,shuffle=True,random_state=2022)
for train_index, test_index in kf.split(X):
x_train = X.iloc[train_index]
y_train = Y.iloc[train_index]
x_test = X.iloc[test_index]
y_test = Y.iloc[test_index]
clf.fit(x_train,y_train,verbose=300,cat_features=col)
y_pred=clf.predict_proba(x_test)[:,1]
print('验证集auc:{}'.format(roc_auc_score(y_test, y_pred)))
mean_score += roc_auc_score(y_test, y_pred) / n_folds
y_pred_final = clf.predict_proba(testA2)[:,-1]
result.append(y_pred_final)
# 模型评估
print('mean 验证集Auc:{}'.format(mean_score))
cat_pre=sum(result)/n_folds
# 结果
0: total: 3.13s remaining: 15m 35s
299: total: 9m 15s remaining: 0us
验证集auc:0.7388007571702323
0: total: 2.08s remaining: 10m 20s
299: total: 9m 45s remaining: 0us
验证集auc:0.7374681864389327
0: total: 1.73s remaining: 8m 38s
299: total: 9m 22s remaining: 0us
验证集auc:0.7402961974320663
mean 验证集Auc:0.7388550470137438说明:catboost能高效合理地处理类别型特征,只需要使用cat_features 参数指定分类特征即可,加入的类别特征越多,计算也越耗时,但效果也有一定提升。可以看出3次交叉验证跑完就耗时接近半小时,还只是在iterations=300的情况下,由于本人PC能力有限,所以参数方面就没有过多的调整测试,对于大数据目标变量的预测,交叉验证是必不可少的,可以通过训练集与测试集的不同划分,让模型进行更多的学习,同时通过每一次的预测结果最后平均,使结果更加稳定。
总结
1.关于样本平衡的问题,imbalanced_ensemble是个不错的尝试,该库有很多平衡样本的方法,本人已经试过OverBoostClassifier、BorderlineSMOTE、SPE的方法来平衡类别,过采样容易增加噪声,导致训练集表现不错,测试集一般,同时会导致小样本量预测失准,降采样容易导致对大样本量学习不足,但并不代表平衡样本的方法就不适用,还需要不断摸索。
2.对于缺失值的问题,一般都是数值型变量用中位数填充,类别变量用众数填充,还可以通过回归模型选取相关变量进行预测,可能会有惊喜。
3.此类风控预测如果能够结合业务人员的经验对变量进行筛选和补充,相信会有不一样的结果。
4.关于特征降维还有很多方法可以尝试,PCA只是其中一种,特征工程也是一个庞杂的体系,需要不断学习。
5.关于模型调参,可以适当提高预测精度,如果时间允许,可以组合测试参数。
6.参赛的过程大于结果,从中学到的知识和经验会为我今后大数据处理打下基础。