目录
六、线上分数、排名
前言
这次比赛主要体会是模型融合,因为数据集存在测试集与训练集分布不一致的情况,所以很容易出现线上测试分数高于线下的情况,最后经过模型权重筛选,融合catboost、lightgbm、linear、random forest四个模型,将分数定格在0.1146。
一、赛题介绍
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。变量全部是数值变量,无缺失值
排名结果依据预测结果的MSE(mean square error)。
二、数据探索
1.读取数据、查看数据分布
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
with open("/zhengqi_train.txt") as fr:
df=pd.read_table(fr,sep="\t")
with open("/zhengqi_test.txt") as fr:
test=pd.read_table(fr,sep="\t")
# 获取数值变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns)
# 绘制数据分布
plt.figure(figsize=(30,25))
i=1
for col in Nu_feature:
ax=plt.subplot(7,6,i)
ax=sns.kdeplot(df[col],color='red')
ax=sns.kdeplot(test[col],color='cyan')
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax=ax.legend(['train','test'])
i+=1
plt.show()
可以看到有部分变量的train与test分布不一致,这个更加贴近实际,后续再用线性回归建模时需要去掉部分分布不一致的数据,避免过拟合。
2.数据相关性
correlation_matrix=df.corr()
plt.figure(figsize=(12,10))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="RdGy")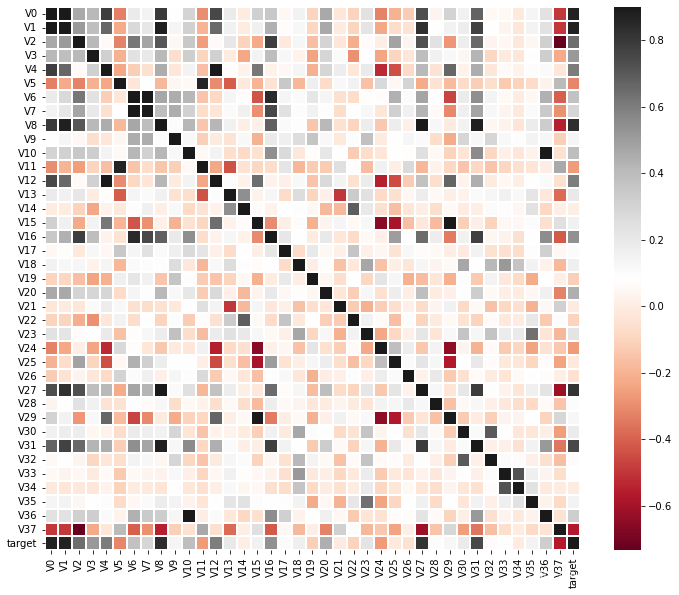
部分变量与目标变量相关性比较高,选取部分变量绘制与目标变量的散点图。
col=['V0', 'V1','V2', 'V3', 'V5', 'V11', 'V24','V37','target']
sns.pairplot(df[col],hue='target',kind='scatter')
由于目标变量是连续值,所以没有离散值来得直观,但是还是可以看出线性的变化。
3.QQ图及BOX-COX变换
这里说明一下,由于部分数据并不服从正态分布,利用box-cox可以对数据进行修正使其服从正态分布,用于数据建模,提升模型的能力,但本人最终并没有用变换后的数据建模,这里仅展示变换后数据分布的差异供参考。
from sklearn.preprocessing import MinMaxScaler
from scipy import stats
# 归一化
cols_numeric=list(test.columns)
def scale_minmax(col):
return (col-col.min())/(col.max()-col.min())
train_data_process=df[cols_numeric].apply(scale_minmax,axis=0)
test_data_process=test[cols_numeric].apply(scale_minmax,axis=0)
# box-cox变换
for col in test.columns:
train_data_process.loc[:,col], _ = stats.boxcox(train_data_process.loc[:,col]+1)
test_data_process.loc[:,col], _ = stats.boxcox(test_data_process.loc[:,col]+1)
#QQ图
plt.figure(figsize=(30,40))
j=1
for col in test.columns:
ax=plt.subplot(14,6,j)
sns.distplot(test_data_process[col],fit=stats.norm)
ax.set_xlabel(col)
j+=1
ax=plt.subplot(14,6,j)
stats.probplot(test_data_process[col],dist=stats.norm, plot=plt)
j+=1
plt.subplots_adjust(wspace=0.3,hspace=0.5) # 调整图间距
plt.show()先上变换前的train_QQ图

变换后的train_QQ图
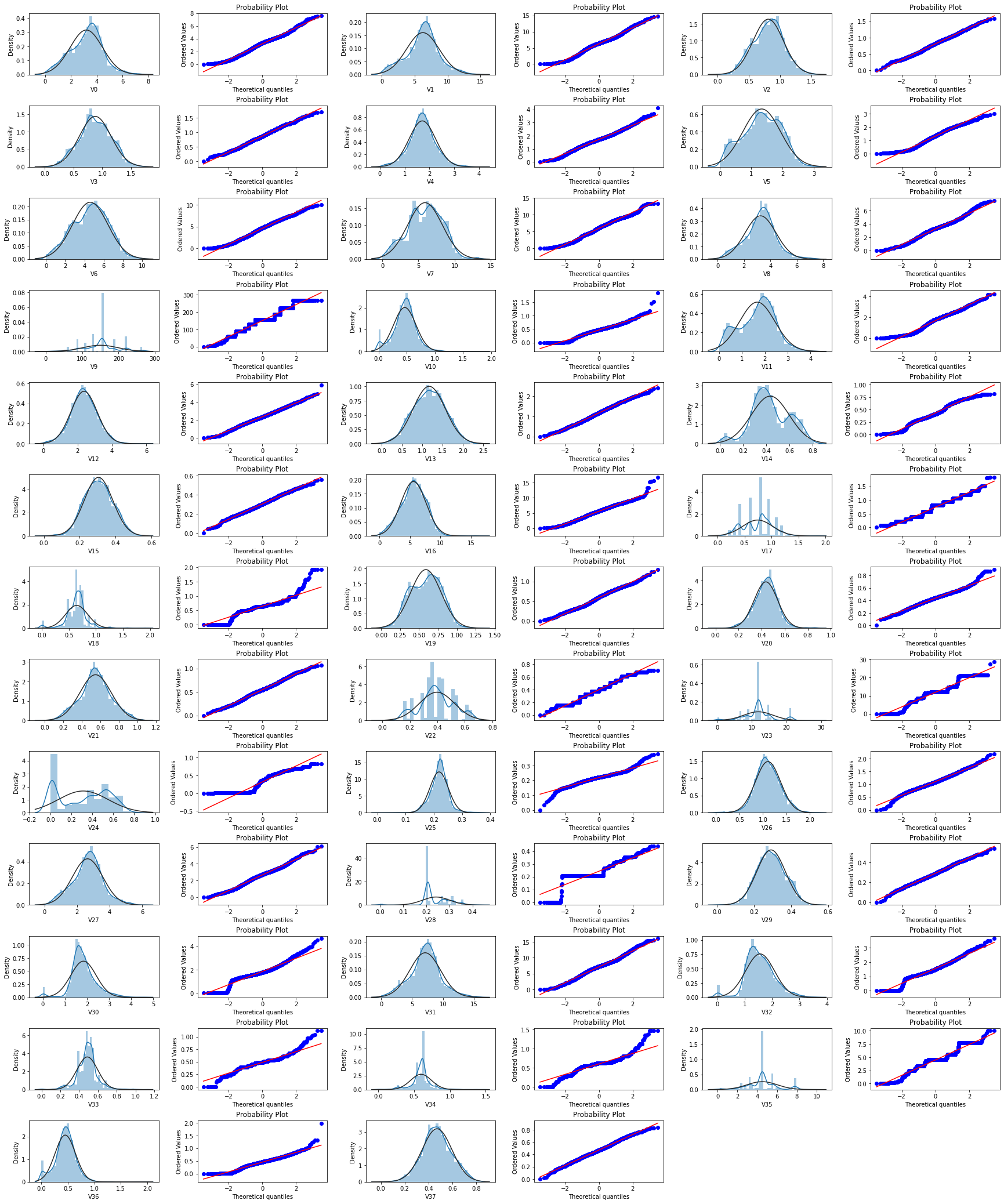
通过对比可以看出box-cox变换后的数据更符合正态分布。
三、特征处理
特征的处理主要针对catboost及lightgbm的,随机森林直接用的原始数据建模,线性回归在原始数据的基础上删除了部分变量进行建模。
对于集成模型来说,尽可能构建多的特征来提高模型精度。
对于线性回归模型,且部分变量分布不一致的情况,将这部分变量删除可以避免过拟合。
1.catboost及lightgbm特征处理
a.特征交叉
num_cols = [0,1,2,3,10,12,8]
for index, value in enumerate(num_cols):
for j in num_cols[index+1:]:
df['new'+str(value)+'+'+str(j)]=df['V'+str(value)]+df['V'+str(j)]
test['new'+str(value)+'+'+str(j)]=test['V'+str(value)]+test['V'+str(j)]
num_cols = [0,1,2,3,16,31]
for index, value in enumerate(num_cols):
for j in num_cols[index+1:]:
df['new'+str(value)+'+'+str(j)]=df['V'+str(value)]+df['V'+str(j)]
test['new'+str(value)+'+'+str(j)]=test['V'+str(value)]+test['V'+str(j)]b.平均数编码
# 分离变量
X=df.drop(columns='target')
Y=df['target']
# 平均数编码
import Meancoder
class_list = ['V0','V1','V2','V3']
MeanEnocodeFeature = class_list
ME = Meancoder.MeanEncoder(MeanEnocodeFeature,target_type='regression') # 声明平均数编码的类
X = ME.fit_transform(X,Y) # 对训练数据集的X和y进行拟合
test = ME.transform(test_data_process)#对测试集进行编码2.linear特征处理
# 删除部分分布不一致变量
df.drop(['V2','V5','V9','V11','V13','V14','V17','V19','V20','V21','V22','V27'],axis=1,inplace=True)
test.drop(['V2','V5','V9','V11','V13','V14','V17','V19','V20','V21','V22','V27'],axis=1,inplace=True)注意:不同的模型用不同的变量特征,分开运行,得到不同的结果。
四、建立模型
1.catboost+lightgbm+5KFold
from catboost import CatBoostRegressor
from lightgbm.sklearn import LGBMRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 划分训练及测试集
x_train,x_test,y_train,y_test = train_test_split( X, Y,test_size=0.3,random_state=1)
# 模型训练
clf=CatBoostRegressor(loss_function="MAE",
eval_metric= 'R2',
task_type="CPU",
od_type="Iter", #过拟合检查类型
depth=7,
learning_rate=0.02,
iterations=5000,
random_seed=2022)
gbm = LGBMRegressor(n_estimators=5000,learning_rate=0.02,boosting_type= 'gbdt',
objective = 'regression_l1',
max_depth = -1,
random_state=2022,
metric='mse')
# 5折训练
result = []
mean_score = 0
result1 = []
mean_score1 = 0
n_folds=5
kf = KFold(n_splits=n_folds ,shuffle=True,random_state=2022)
for train_index, test_index in kf.split(X):
x_train = X.iloc[train_index]
y_train = Y.iloc[train_index]
x_test = X.iloc[test_index]
y_test = Y.iloc[test_index]
# catboost训练
clf.fit(x_train,y_train,verbose=5000)
y_pred=clf.predict(x_test)
print('验证集MSE:{}'.format(mean_squared_error(y_test,y_pred)))
mean_score += mean_squared_error(y_test,y_pred)/ n_folds
y_pred_test = clf.predict(test)
result.append(y_pred_test)
# gbm训练
gbm.fit(x_train,y_train)
y_pred1=gbm.predict(x_test)
print('验证集MSE:{}'.format(mean_squared_error(y_test,y_pred1)))
mean_score1 += mean_squared_error(y_test,y_pred1)/ n_folds
y_pred_final1 = gbm.predict((test),num_iteration=gbm.best_iteration_)
y_pred_test1=y_pred_final1
result1.append(y_pred_test1)
# 模型评估
print('mean 验证集MSE:{}'.format(mean_score))
cat_pre=sum(result)/n_folds
np.savetxt('/test.txt',cat_pre)
print('mean 验证集mse:{}'.format(mean_score1))
cat_pre1=sum(result1)/n_folds
np.savetxt('/test_gbm.txt',cat_pre1)2.linear+RandomForest
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
lr=LinearRegression()
rf=RandomForestRegressor(n_estimators=800,max_features='sqrt',random_state=0)
lr.fit(x_train,y_train)
rf.fit(x_train,y_train)
linear_predict = lr.predict(x_test)
rf_predict = rf.predict(x_test)
# 模型评估
print('LR_MSE:',mean_squared_error(y_test,linear_predict))
print('rf_MSE:',mean_squared_error(y_test,rf_predict))
# 预测
pre_lr = lr.predict(test)
pre_rf = rf.predict(test)
# 保存
np.savetxt('/pre_lr.txt',pre_lr)
np.savetxt('/pre_rf.txt',pre_rf)这里注意Linear要删除变量,再训练,与cat及gbm区分开。
RandomForest用原始数据训练,不做特征,不删除变量。
五、模型融合
模型融合的关键是权重的设置,不同的模型,不同的权重,才会有好的结果。
| catboost+lightgbm+5KFold | 0.1253 |
| catboost+lightgbm+Linear+RandomForest | 0.1181 |
| catboost+lightgbm++5KFold+Linear+RandomForest | 0.1146 |
1.catboost+lightgbm简单加权融合
# 模型加权融合
sub_Weighted = (1-mean_score1/(mean_score1+mean_score))*cat_pre1+(1-mean_score/(mean_score1+mean_score))*cat_pre
这个线上只有0.1253
2.模型权重筛选
def model_mix(pred, pred1,pred2,pred3):
result = pd.DataFrame(columns=['CatBoostRegressor','LGBMRegressor','Linear','RandomForest','Combine'])
for a in range (10):
for b in range(10):
for c in range(10):
for d in range(1,10):
y_pred3 = (a*pred + b*pred1 + c*pred2+ d*pred3) / (a+b+c+d)
mse = mean_squared_error(y_test,y_pred3)
result = result.append([{'CatBoostRegressor':a,
'LGBMRegressor':b,
'Linear':c,
'RandomForest':d,
'Combine':mse}],
ignore_index=True)
return result
model_combine = model_mix(y_pred,y_pred1,linear_predict,rf_predict)
model_combine.sort_values(by='Combine', inplace=True)
model_combine.head()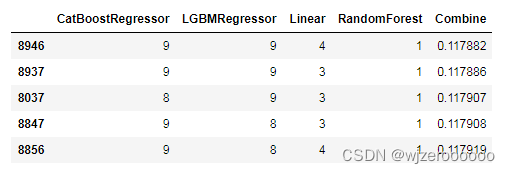
这里注意catboost及gbm要与linear、RandomForest保持一致,用单次训练,保证y_test是一致的
这里验证集的权重是9941,最后经过测试,权重系数为Linear:9,RandomForest:9,CatBoostRegressor:9,CatBoostRegressor:1 ,这个线上分数:0.1181
通过验证集的权重筛选可以为模型权重提供参考,是一种不错的筛选方式
3.新权重的模型加权融合
with open("/pre_lr.txt") as fr:
df_lr=pd.read_table(fr,header=None,sep="\t")
with open("/pre_rf.txt") as fr:
df_rf=pd.read_table(fr,header=None,sep="\t")
with open("/test.txt") as fr:
df_test=pd.read_table(fr,header=None,sep="\t")
with open("/test_gbm1.txt") as fr:
df_test_gbm=pd.read_table(fr,header=None,sep="\t")
# 加权计算
mix_predict = (9*df_lr + 9*df_rf+9*df_test+1*df_test_gbm) /28
np.savetxt('/four_mix_4predict.txt',mix_predict)六、线上分数、排名
总结
1. 对于集成模型,尽量保留数据的完整性,对于线性模型,需要删除分布不一致的特征,否则容易过拟合。
2. 特征工程也会根据模型及划分的随机种子不同造成结果差异。
3. BOX-COX变换在本次模型中没有用到,还需要继续研究。
4. 模型融合对于线上分数的提高是很明显的,方式也有很多,可以多多利用。