无监督学习
无监督学习(Unsupervised Learning)着重于发现数据本身的分布特点。与监督学习 (Supervised Learning)不同,无监督学习不需要对数据进行标记。这样,在节省大量人工的同时,也让可以利用的数据规模变得不可限量。
从功能角度讲,无监督学习模型可以帮助我们发现数据的“群落”,同时也可以寻找“离群”的样本;另外,对于特征维度非常高的数据样本,我们同样可以通过无监督的学习对数据进行降维,保留最具有区分性的低维度特征。
这些都是在海量数据处理中是非常实用的技术。
数据聚类
数据聚类是无监督学习的主流应用之一。最为经典并且易用的聚类模型,当属K均值(K means)算法。该算法要求我们预先设定聚类的个数,然后不断更新聚类中心;经过几轮这样的迭代,最后的目标就是要让所有数据点到其所属聚类中心距离的平方和趋于稳定。
K均值算法
·模型介绍:这是在数据聚类中是最经典的,也是相对容易理解的模型。算法执行的过程分为4个阶段,如图所示:
1首先,随机布设K个特征空间内的点作为初始的聚类中心;
2然后,对于根据每个数据的特征向量,从K个聚类中心中寻找距离最近的一个,并且把该数据标记为从属于这个聚类中心;
3接着,在所有的数据都被标记过聚类中心之后,根据这些数据新分配的类簇,重新对K个聚类中心做计算;
4如果一轮下来,所有的数据点从属的聚类中心与上一次的分配的类簇没有变化,那么迭代可以停止;
否则回到步骤2继续循环。


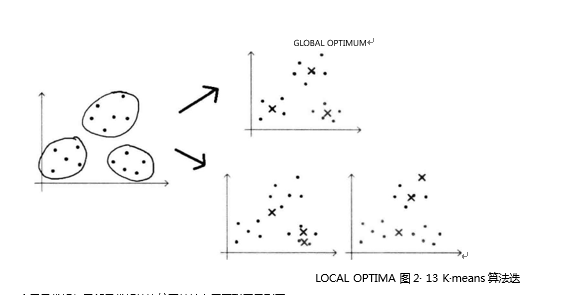
特点分析:K一mean 聚类模型所采用的迭代式算法,直观易懂并且非常实用。只是有两大缺陷:容易收敛到局部最优解;需要预先设定簇的数量。
首先解释什么叫做局部最优解。假设图左侧为实际数据以及正确的所属类簇。如果聚类算法可以收敛至全局最优解,那么三个类簇的聚类中心应如右侧Global Optimum所示,聚类结果同正确结果一致。但是,K一means算法无法保证能够使得三个类簇的中心迭代至上述的全局最优解。相反很有可能受到随机初始类簇中心点位置的影响,最终迭代到如右侧Local Optimum所示的两种情况而收敛。这样便导致无法继续更新聚类中心,使得聚类结果与正确结果又很大出人。这是算法自身的理论缺陷所造成的,无法轻易地从模型设计上弥补;却可以通过执行多次K一means算法来挑选性能表现更好的初始中心点,这样的工程方法代替。
然后,我们介绍一种“肘部”观察法用于粗略地预估相对合理的类簇个数。因为Kmeans模型最终期望所有数据点到其所属的类簇距离的平方和趋于稳定,所以我们可以通过观察这个数值随着K的走势来找出最佳的类簇数量。理想条件下,这个折线在不断下降并且趋于平缓的过程中会有斜率的拐点,同时意味着从这个拐点对应的K值开始。
特征降维
特征降维是无监督学习的另一个应用,目的有二:其一,我们会经常在实际项目中遭遇特征维度非常之高的训练样本,而往往又无法借助自己的领域知识人工构建有效特征;其二,在数据表现方面,我们无法用肉眼观测超过三个维度的特征。因此,特征降维不仅重构了有效的低维度特征向量,同时也为数据展现提供了可能。在特征降维的方法中,主成分分析(Principal Component Analysis)是最为经典和实用的特征降维技术,特别在辅助图像识别方面有突出的表现。
主成分分析(PCA)
·模型介绍:首先我们思考两个小例子,这也是作者经常用来向周围朋友解释降低维度、信息冗余和PCA功能的