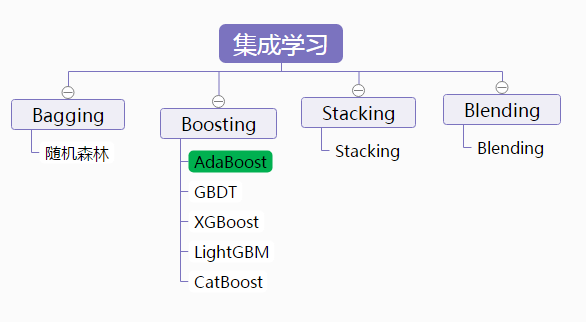
一、AdaBoost初识
这个方法主要涉及到2种权重:
样本权重:每个样本都对应一个权重。在构建第一个弱模型之前,所有训练样本的权重是一样的。第一个模型完成后,要加大那些被这个模型错误分类(分类问题)、或者预测值与真实值的差值较大(回归问题)的样本的权重。依次迭代,最终构建多个弱模型。每个弱模型所对应的训练数据集样本是一样的,只是样本权重是不一样的。
弱模型权重:得到的每个弱模型都对应一个权重。精度越高(分类问题的错分率越低,回归问题的错误率越低)的模型,其权重也就越大,在最终集成结果时,其话语权也就越大。
二、AdaBoost流程图
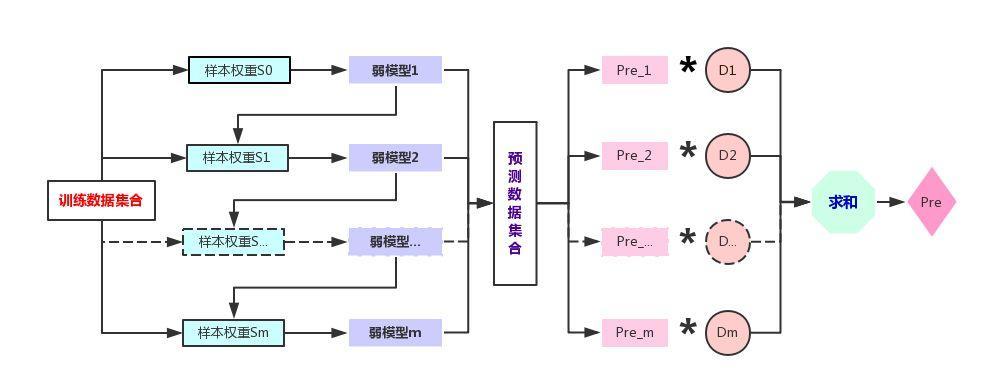
三、AdaBoost步骤
分类问题

回归和分类的最大不同在于:回归问题错误率的计算方式。因为回归有很多的变种,下面以Adaboost R2算法为例给出回归问题的步骤:
回归问题

四、AdaBoost正则化

五、AdaBoost答疑
- 这个弱模型可以是什么?
经常用的就是单层的决策树,也称为决策树桩(Decision Stump),例如单层的CART。其实这个层数也是参数,需要交叉验证得到最好的。当然这个弱模型也可以是SVM、逻辑回归、神经网络等。 - 增加的样本权重如何在下一个模型训练时体现出作用?
以决策树为例,计算最佳分割点基尼系数时,或者MSE时,要乘以样本权重。总之,对于样本的计算量,要乘以相应的样本的权重。如果没在这个AdaBoost的框架下,则相当于原来的样本的权重都是一样的,所以乘或者不乘是一样的,现在在这个AdaBoost的框架下,因为样本权重发生了改变,所以需要乘。这样就把样本权重的改变体现了出来。
六、Sklearn包中的Adaboost类库概述
Adaboost类库中有两个框架:AdaBoostClassifier和AdaBoostRegressor。前者用于分类问题,后者用于回归问题。其中前者使用了两种算法:SAMME和SAMME.R。而后者使用的算法为Adaboost.R2。
对Adaboost调参,包括2部分:一是对框架进行调参, 二是对弱模型进行调参。
- 框架参数
base_estimator:弱模型。常用的为CART决策树或者神经网络MLP。默认是前者。即分类默认使用CART分类树DecisionTreeClassifier,而回归默认使用CART回归树DecisionTreeRegressor;
algorithm:算法。只有分类框架才有,为SAMME或者SAMME.R。默认为后者;
loss:损失函数。只有回归框架有,有”linear“:线性,”square“:平方;”exponential“:指数,三种选择,默认是线性。可交叉验证选择合适的;
n_estimators: 弱模型的个数。值太小,容易欠拟合,值太大,又容易过拟合,一般选择一个适中的数值。默认是50。可交叉验证选择合适的;
learning_rate:每个弱模型权重的缩减系数,可以和n_estimators一起调参。默认是1;
仅给出默认的CART决策树的参数。即CART分类树DecisionTreeClassifier和CART回归树DecisionTreeRegressor。这里只介绍比较重要的参数:
- 弱模型参数
max_features:划分时考虑的最大特征数。默认是"None",考虑所有的特征数;
**max_depth:**决策树的最大深度。 默认的话,决策树在建立子树的时候不会限制子树的深度。可交叉验证选择合适的;
**min_samples_split:**内部节点再划分所需最小样本数。如果某节点的样本数少于此数,则不会分裂,默认是2;
**min_samples_leaf:**叶子节点最少样本数。 如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1;
max_leaf_nodes:最大叶子节点数。默认不限制最大的叶子节点数。
七、实例
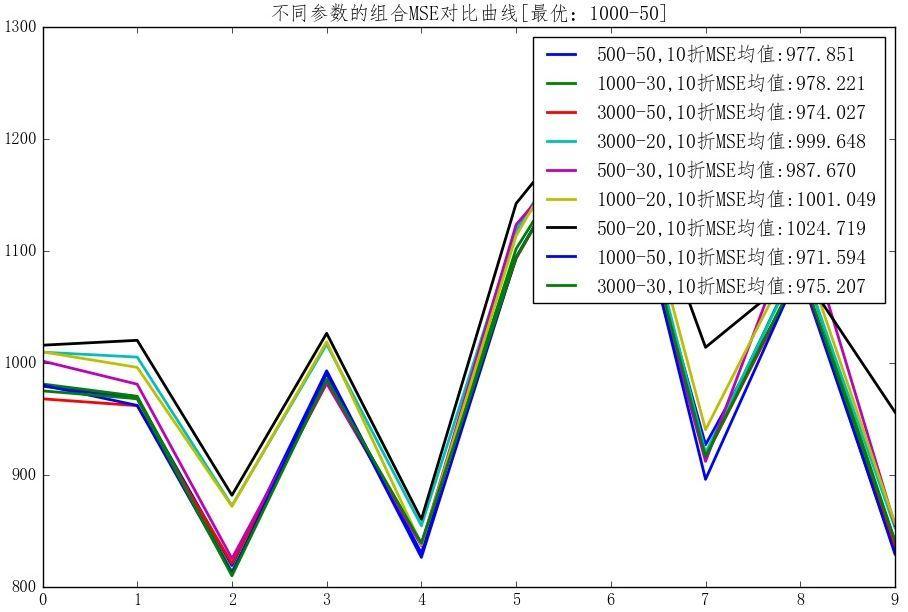
- 北京市Pm2.5预测
交叉选择参数:
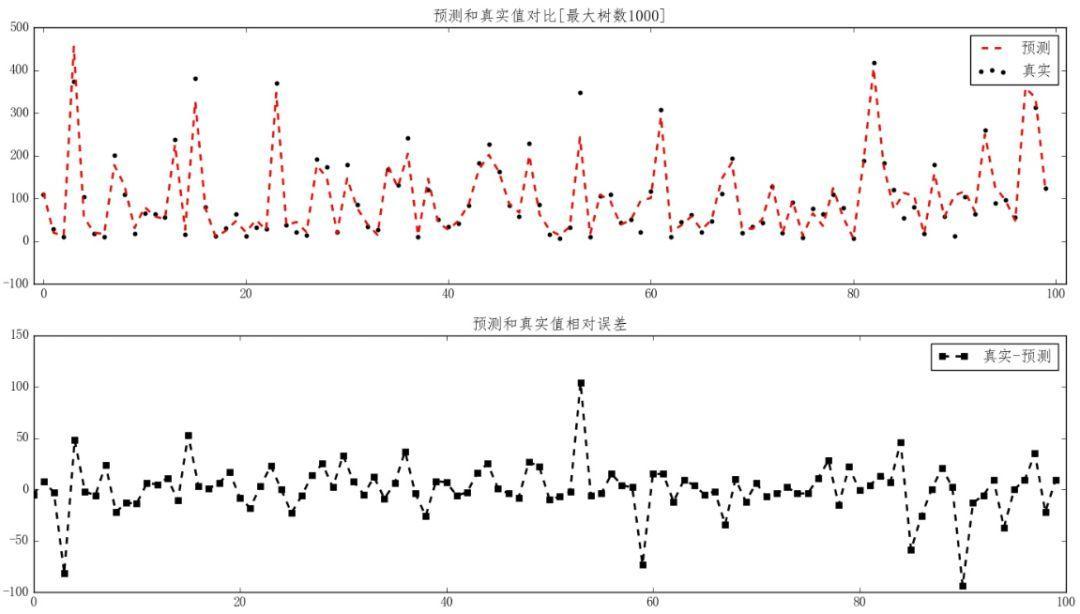
预测数据结果
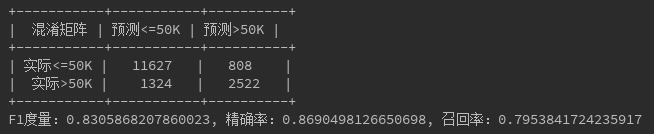
- 成年人收入分类
交叉选择参数:

预测数据结果:

实例代码:AdaBoost,扫描下方二维码或者微信公众号直接搜索”Python范儿“,关注微信公众号pythonfan, 获取更多实例和代码。
