监督学习经典摸型
机器学习中监督学习模型的任务重点在于,根据已有经验知识对未知样本的标记进行预测。根据目标预测变量的类型不同,我们把监督学习任务大体分为分类学习与回归预测两类。
尽管如此,我们仍然可以对它们的共同点进行归纳,整理出如图所示的监督学习任务的基本架构和流程:
首先,准备训练数据,可以是文本、图像、音频等;然后抽取所需要的特征,形成特征向量(Feature Vectors);
接着,把这些特征向量连同对应的标记(Labels)送入学习算法(Machine LearningAlgorithm)中,训练出一个预测模型 (Predictive Model);
然后,采用同样的特征抽取方法作用于新测试数据,得到测试数据的特征向量;
最后,使用预测模型对这些新的待测试的特征向量进行预测并得到结果(Expected Label)。

分类学习
分类学习是最为常见的监督学习问题,并且其中的经典模型也最为广泛地被应用。其中,最基础的便是二分类(Binary Classification)问题,即判断是非,从两个类别中选择一个作为预测结果;除此之外还有多类分类(Multic际s Classification)的问题,即在多于两个类别中选择一个;甚至还有多标签分类(Multi一label Classification)问题,与上述二分类以及多类分类问题不同,多标签分类问题判断一个样本是否同时属于多个不同类别。
在实际生活和工作中,我们会遇到许许多多的分类问题,比如,医生对肿瘤性质的判定;邮政系统对手写体邮编数字进行识别mnist数据集,cifar10分类等;互联网资讯公司对新闻进行分类;生物学家对物种类型的鉴定;甚至,我们还能够对某些大灾难的经历者是否生还进行预测等。
线性分类器
线性分类器(Linear Classifiers),顾名思义,是一种假设特征与分类结果存在线性关系的模型。这个模型通过累加计算每个维度的特征与各自权重的乘积来帮助类别决策。
然而,我们所要处理的最简单的二分类问题希望f E{ 0,1 };因此需要一个函数把原先的f映射到(0,1)。于是我们想到了逻辑斯蒂(Logistic)函数:
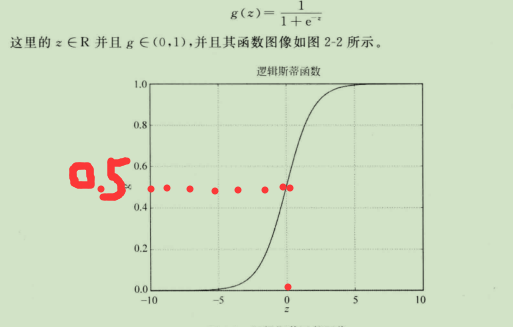
支持向量机分类(svm)
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。(因为所有数据都离超平面远些,那以这个超平面为分界面,分类更容易,效果更好,错误更少)
过两类样本中离分类面最近的点且平行于最优分类面的超平面上H1,H2的训练样本就叫做支持向量。因为整体上希望各样本点离超平面远些,那样更容易区分。但是,具体来说,肯定有一些样本点在所有样本中是离超平面最近的点,那些点满足上面的要求的点,才叫支持向量。

真实中的数据展示如下:
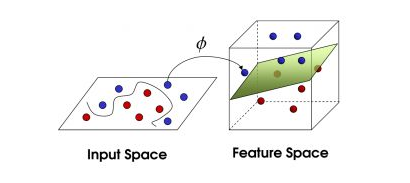
图中绿色即超平面,也叫核函数,我们现实的数据肯定不可能这么一刀切,一个平面就可以区分开来,应该是立体的不规则的形态,所以我们的核函数要更高级一点的,线性的核函数是最简单的一类分类器,还有很多其他核函数,更复杂但分类效果更好。
朴素贝叶斯
先理解一下"条件概率"(Conditional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
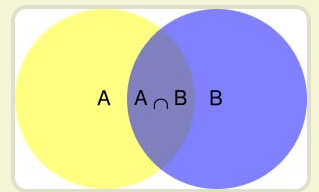
根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率:P(A∩B) 除以P(B)
形象描述为 (A∩B)的面积 除以(B)的面积。

大概过程大伙看上面写的比较精简,原书作者解释如下:

更加详细资料:
https://www.zhihu.com/question/19960417 里面很多链接慢慢享用
http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.html 感觉和我的朴素贝叶斯不一样
https://blog.csdn.net/amds123/article/details/70173402 耐心看懂这个例子估计也懂了
https://blog.csdn.net/li8zi8fa/article/details/76176597
https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
K近邻(分类)
·模型介绍:K近邻模型本身非常直观并且容易理解。算法描述起来也很简单,如图所示。假设我们有一些携带分类标记的训练样本,分布于特征空间中;蓝色、绿色的样本点各自代表其类别。对于一个待分类的红色测试样本点,未知其类别,按照成语“近朱者赤,近墨者黑”的说法,我们需要寻找与这个待分类的样本在特征空间中距离最近的K个已标记样本作为参考,来帮助我们做出分类决策。这便是K近邻算法的通俗解释。而在图中,如果我们根据最近的K:3个带有标记的训练样本做分类决策,那么待测试的样本应该属于绿色类别,因为在 3个最近邻的已标记样本中,绿色类别样本的比例最高;如果我们扩大搜索范围,设定K一7,那么分类器则倾向待测样本属于蓝色。因此我们也可以发现,随着 K的不同,我们会获得不同效果的分类器。
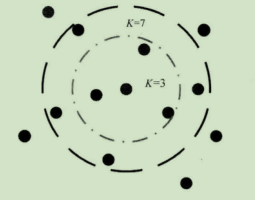
拓展小贴士;这里是想向读者暗示一件事情:K不属于模型通过训练数据学习的参数,因此要在模型初始化过程中提前确定;但是K值的不同又会对模型的表现性能有巨大影响,所以需要我们给予更多关注。
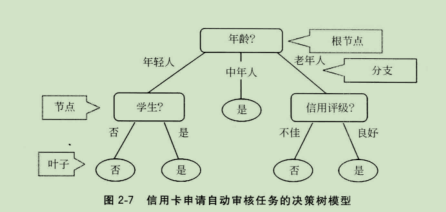
决策树(分类)
模型介绍:在前面所使用的逻辑斯蒂回归和支持向量机模型,都在某种程度上要求被学习的数据特征和目标之间遵照线性假设。然而,在许多现实场景下,这种假设是不存在的。
比如,如果要借由一个人的年龄来预测患流感的死亡率。如果采用线性模型假设,那么只有两种情况:年龄越大死亡率越高;或者年龄越小死亡率越高。然而,根据常识判断,青壮年因为更加健全的免疫系统,相较于儿童和老年人不容易因患流感死亡。因此,年龄与因流感而死亡之间不存在线性关系。如果要用数学表达式描述这种非线性关系,使用分段函数最为合理;而 在机器学习模型中,决策树就是描述这种非线性关系的不二之选 。使用多种不同特征组合搭建多层决策树的情况,模型在学习的时候就需要考虑特征节点的选取顺序。
集成模型(分类)
模型介绍:常言道:“一个篱笆三个桩,一个好汉三个帮”。集成(Ensemble)分类模型便是综合考量多个分类器的预测结果,从而做出决策。只是这种“综合考量” 的方式大体上分为两种:
一种是利用相同的训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的分类决策。比较具有代表性的模型为随机森林分类器 (Random Forest Classifier),即在相同训练数据上同时搭建多棵决策树(Decision Tree)。然而,在2. 1. 1. 5决策树一节提到过,一株标准的决策树会根据每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分裂节点的顺序;如此一来,所有在随机森林中的决策树都会受这一策略影响而构建得完全一致,从而丧失了多样性。因此,随机森林分类器在构建的过程中,每一棵决策树都会放弃这一固定的排序算法,转而随机选取特征。
另一种则是按照一定次序搭建多个分类模型。这些模型之间彼此存在依赖关系。
般而言,每一个后续模型的加人都需要对现有集成模型的综合性能有所贡献,进而不断提升更新过后的集成模型的性能,并最终期望借助整合多个分类能力较弱的分类器,搭建出具有更强分类能力的模型(三个臭皮匠顶个诸葛亮)。比较具有 代表性的当属梯度提升决策树,Harri级联分类器等 (Gradient Tree Boosting) 与构建随机森林分来器模型不同,这里每一棵决策树在生成的过程中都会尽可能降低整体集成模型在训练集上的拟合误差。