开始之前,先说一下ioremap的作用,ioremap主要是把寄存器做映射。
为什么要映射?
内核空间只能访问虚拟地址的3~4G的地址空间,通常3~4G的空间一部分是映射物理内存,通常默认不会映射寄存器,如果想要访问某个寄存器,则需要把这个寄存的虚拟地址映射到高端内存上。这样内核空间才能直接访问。
下面这篇文章,对3~4G的内核空间和io映射分析的比较好,值得好好看一下。
https://blog.csdn.net/godleading/article/details/18702029
打开源码,搜索ioremap,可以看得到有三个函数原型
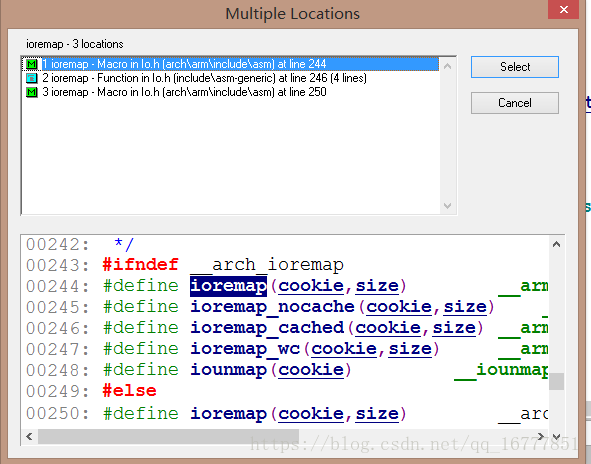
其中一个是在include/sam-generic/目录下,仔细看它里面的源码,它并没有做任何形式的映射,只有在不开MMU的时候才可能用它

剩下的两个都在下面函数中定义的
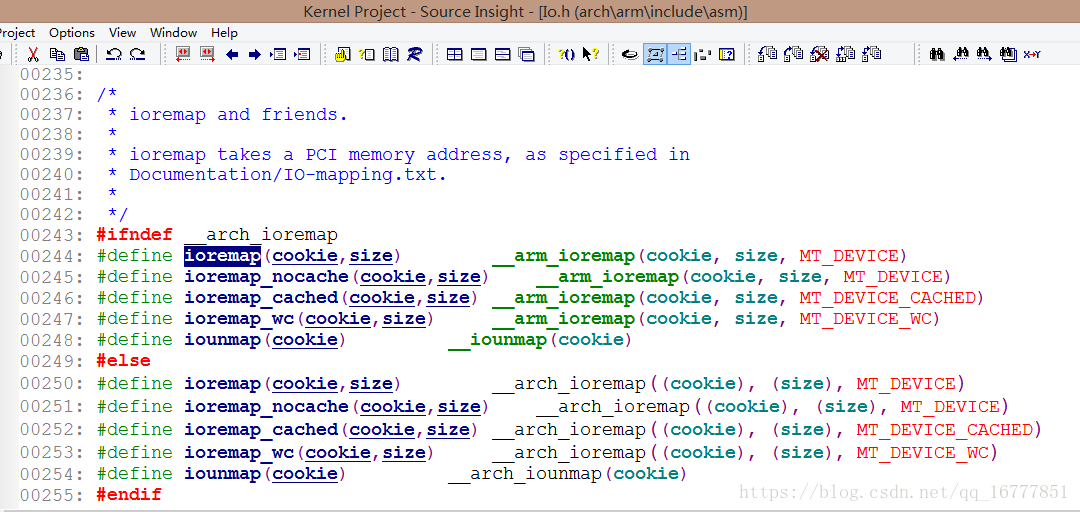
从名字上可以看到我们是使用ram相关的,同时我也是在source insght中没加其它架构相关的源码,所以__arch_ioremap中也没高亮
上面相关的函数比较多,就以最长用的ioremap函数为例来分析
#define ioremap(cookie,size) __arm_ioremap(cookie, size, MT_DEVICE)我们知道第一个参数是寄存器的起始物理地址,第二个是要映射的寄存器的范围
__arm_ioremap第三个参数,表示上面列出来ioremap的几种形式,我们主要是使用普通的形式,下面的分析都默认以传入参数0来分析
#define MT_DEVICE 0
#define MT_DEVICE_NONSHARED 1
#define MT_DEVICE_CACHED 2
#define MT_DEVICE_WC 3查找,共有两个函数,一个是nommu版本的,如下,直接返回传入地址,肯定不是我们要分析的

另一个则是我们需要分析的内容,这里它除了调用传入的三个参数外,还调用了另一个函数作为它的入口参数。。
void __iomem *
__arm_ioremap(unsigned long phys_addr, size_t size, unsigned int mtype)
{
return __arm_ioremap_caller(phys_addr, size, mtype,
__builtin_return_address(0));
}
__builtin_return_address(0)的含义是,得到当前函数返回地址,即此函数被别的函数调用,然后此函数执行完毕后,返回,所谓返回地址就是那时候的地址。如下所示。
6000 0000: ldr r0, =0x666
6000 0004: bl call_func /* 函数调用 */
6000 0008: str r0, =0x555 /* 调用返回地址 */所以这个__arm_ioremap函数第四个参数的位置是调用ioremap函数完后,下一条指定的地址
接下来就看这个函数做了什么吧,
#ifdef __ASSEMBLY__ /* 是否把X强制转换成XY还是X */
#define _AC(X,Y) X
#define _AT(T,X) X
#else
#define __AC(X,Y) (X##Y)
#define _AC(X,Y) __AC(X,Y)
#define _AT(T,X) ((T)(X))
#endif
#define PAGE_SHIFT 12
/* 1和1UL对我们是一样的,这里是把1<<12位,即确定一个页的大小为0x1000即4096字节 */
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
/* 0x1000 - 1 --> 0xfff 后 ~0xfff,在32位系统中是0xffff,f000,这里用这个的作用是
* mmu的内存管理最小是一个页,即4096字节,所以要叶对齐时&使用 */
#define PAGE_MASK (~(PAGE_SIZE-1))
#define __phys_to_pfn(paddr) ((paddr) >> PAGE_SHIFT) /* 物理地址到所属页 */
void __iomem *__arm_ioremap_caller(unsigned long phys_addr, size_t size,
unsigned int mtype, void *caller)
{
unsigned long last_addr;
unsigned long offset = phys_addr & ~PAGE_MASK; /* 确定物理地址在页内的偏移 */
unsigned long pfn = __phys_to_pfn(phys_addr); /* 找到物理地址所在的页地址 */
/*
* Don't allow wraparound or zero size
* 注释说的很明白,不允许映射的范围为0,也不允许结束地址小于起始地址(即phys_addr + size - 1 > 0xffff,ffff)
*/
last_addr = phys_addr + size - 1;
if (!size || last_addr < phys_addr)
return NULL;
/* 这里传入参数分别是 页位置 页内偏移 映射大小 类型(我们默认是0) caller(ioremap后面的指定的地址) */
return __arm_ioremap_pfn_caller(pfn, offset, size, mtype,
caller);
}
/* 仔细追这里面每个宏的定义,可以发现是页表的一些定义Hardware page table definitions. */
static struct mem_type mem_types[] = {
[MT_DEVICE] = { /* Strongly ordered / ARMv6 shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED |
L_PTE_SHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE | PMD_SECT_S,
.domain = DOMAIN_IO,
},
[MT_DEVICE_NONSHARED] = { /* ARMv6 non-shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_NONSHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE,
.domain = DOMAIN_IO,
},
.....................
[MT_MEMORY] = { /* 内存 */
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
[MT_ROM] = { /* NOR 之类n */
.prot_sect = PMD_TYPE_SECT,
.domain = DOMAIN_KERNEL,
},
[MT_MEMORY_NONCACHED] = {
.prot_sect = PMD_TYPE_SECT | PMD_SECT_AP_WRITE,
.domain = DOMAIN_KERNEL,
},
};
上面的表,其实就是我们页表中包括cache、权限管理等一些组合起来的配置,做成表后方便后建立页表时直接使用其中某一项。
#define __pfn_to_phys(pfn) ((pfn) << PAGE_SHIFT) /* 页到物理地址转换 */
/*
* ARMv6 supersection address mask and size definitions.
*/
#define SUPERSECTION_SHIFT 24
#define SUPERSECTION_SIZE (1UL << SUPERSECTION_SHIFT) /* 0x1000000 */
#define SUPERSECTION_MASK (~(SUPERSECTION_SIZE-1)) /* 0xff00,0000 */
const struct mem_type *get_mem_type(unsigned int type)
{
return type < ARRAY_SIZE(mem_types) ? &mem_types[type] : NULL;
}
void __iomem * __arm_ioremap_pfn_caller(unsigned long pfn,
unsigned long offset, size_t size, unsigned int mtype, void *caller)
{
const struct mem_type *type;
int err;
unsigned long addr;
struct vm_struct * area;
/*
* High mappings must be supersection aligned
* 对高映射,即大于4G空间映射,必须是16M对齐,我们32位的一般不会出错在这里
*/
if (pfn >= 0x1000 && (__pfn_to_phys(pfn) & ~SUPERSECTION_MASK))
return NULL;
type = get_mem_type(mtype); /* 我们传入的MT_DEVICE(设备[寄存器]),可以得到对应的在表中的该项的地址 */
if (!type)
return NULL;
/*
* Page align the mapping size, taking account of any offset.
* 将页面大小对其, 例如起始地址0x5fff,fff8,范围0x20字节,则也要映射两页
*/
size = PAGE_ALIGN(offset + size);
/* 找到一块满足size大小的区域 */
area = get_vm_area_caller(size, VM_IOREMAP, caller);
if (!area)
return NULL;
/* 将来映射好后,在高端内存区域的首地址 */
addr = (unsigned long)area->addr;
/* 下面就是根据高端内存区域动态映射区域查找的地址,以及页信息,进行映射*/
#ifndef CONFIG_SMP /* 我们不是多核CPU,所以要运行 */
if (DOMAIN_IO == 0 &&
(((cpu_architecture() >= CPU_ARCH_ARMv6) && (get_cr() & CR_XP)) ||
cpu_is_xsc3()) && pfn >= 0x100000 &&
!((__pfn_to_phys(pfn) | size | addr) & ~SUPERSECTION_MASK)) {
area->flags |= VM_ARM_SECTION_MAPPING;
err = remap_area_supersections(addr, pfn, size, type);
} else if (!((__pfn_to_phys(pfn) | size | addr) & ~PMD_MASK)) {
area->flags |= VM_ARM_SECTION_MAPPING;
err = remap_area_sections(addr, pfn, size, type);
} else
#endif
err = remap_area_pages(addr, pfn, size, type);
if (err) {
vunmap((void *)addr);
return NULL;
}
flush_cache_vmap(addr, addr + size);
return (void __iomem *) (offset + addr); /* 返回的地址是映射到内核空间的地址了 */
}
#define VMALLOC_OFFSET (8*1024*1024) /* 8M */
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
#define VMALLOC_END (0xFC000000)
/* GFP_KERNEL这个标志位分配内存的一个选项,GFP_KERNEL是内核内存分配时最常用的,无内存可用时可引起休眠 */
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
struct vm_struct *get_vm_area_caller(unsigned long size, unsigned long flags,
void *caller)
{
/* */
return __get_vm_area_node(size, 1, flags, VMALLOC_START, VMALLOC_END,
-1, GFP_KERNEL, caller);
}
static struct vm_struct *__get_vm_area_node(unsigned long size,
unsigned long align, unsigned long flags, unsigned long start,
unsigned long end, int node, gfp_t gfp_mask, void *caller)
{
static struct vmap_area *va;
struct vm_struct *area;
/* #define VM_IOREMAP 0x00000001 /* ioremap() and friends */在前面定义传进来的 */
BUG_ON(in_interrupt());
if (flags & VM_IOREMAP) {
int bit = fls(size);
if (bit > IOREMAP_MAX_ORDER)
bit = IOREMAP_MAX_ORDER;
else if (bit < PAGE_SHIFT)
bit = PAGE_SHIFT;
align = 1ul << bit;
}
size = PAGE_ALIGN(size); /* 页对齐 */
if (unlikely(!size))
return NULL;
/* 申请一个struct vm_struct空间,存放未使用空间信息初始化 */
area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node);
if (unlikely(!area))
return NULL;
/*
* We always allocate a guard page. 每次都多申请一个保护页面
*/
size += PAGE_SIZE;
/* start 和 end 分别为 VMALLOC_START 和 VMALLOC_END align 为 1
* 已经使用的 vm 的信息分别存在各个 vmap_area 结构体中
* 所有的 vmap_area 结构体都在红黑树 vmap_area_root 中
* alloc_vmap_area 函数的主要功能是,查找红黑树 vmap_area_root ,找到 start 和 end 之间满足 size 大小的未使用空间,
*/
va = alloc_vmap_area(size, align, start, end, node, gfp_mask);
if (IS_ERR(va)) {
kfree(area);
return NULL;
}
/* 将该结构体插入到红黑树 */
insert_vmalloc_vm(area, va, flags, caller);
return area;
}
/* 初始化该结构体,并将其插入到红黑树中 */
static void insert_vmalloc_vm(struct vm_struct *vm, struct vmap_area *va,
unsigned long flags, void *caller)
{
struct vm_struct *tmp, **p;
vm->flags = flags;
vm->addr = (void *)va->va_start;
vm->size = va->va_end - va->va_start;
vm->caller = caller;
va->private = vm;
va->flags |= VM_VM_AREA;
write_lock(&vmlist_lock);
for (p = &vmlist; (tmp = *p) != NULL; p = &tmp->next) {
if (tmp->addr >= vm->addr)
break;
}
vm->next = *p;
*p = vm;
write_unlock(&vmlist_lock);
}主要做了下面几件重要的事:
1.参数检查,确定不是RAM,地址不要越界等
2.在VMALLOC_START到VMALLOC_END之间找到所需要大小的地址空间。
3.建立页表
iounmap
明显就是做一些,移除红黑树节点,释放内存空间之类的事情了。
说明:
在一个进程中,同一个(一组)寄存器可以多次ioremap,每次ioremap,都会为其建立新的页表,即也会有不同的虚拟地址。但这些虚拟地址都是映射的同一片物理地址,所以无论操纵那一个ioremap返回的虚拟地址,最终都操作能够的是那块物理地址。