一、相关理论
本篇博文主要介绍南京大学周志华教授在2017年提出的一种深度森林结构——gcForest(多粒度级联森林)。近年来,深度神经网络在图像和声音处理领域取得了很大的进展。关于深度神经网络,我们可以把它简单的理解为多层非线性函数的堆叠,当我们人工很难或者不想去寻找两个目标之间的非线性映射关系,我们就多堆叠几层,让机器自己去学习它们之间的关系,这就是深度学习最初的想法。既然神经网络可以堆叠为深度神经网络,那我们可以考虑,是不是可以将其他的学习模型堆叠起来,以获取更好的表示性能,gcForest就是基于这种想法提出来的一种深度结构。gcForest通过级联的方式堆叠多层随机森林,以获得更好的特征表示和学习性能。
深度神经网络虽然取得很好的性能,但是也存在一些问题。
第一、要求大量的训练数据。深度神经网络的模型容量很大,为了获得比较好的泛化性能,需要大量的训练数据,尤其是带标签的数据。获取大规模数据需要耗费很大的人工成本;
第二、深度神经网络的计算复杂度很高,需要大量的参数,尤其是有很多超参数(hyper-parameters)需要优化。比如网络层数、层节点数等。所以神经网络的训练需要很多trick;
第三、深度神经网络目前最大的问题就是缺少理论解释。就像“炼丹”一样,反正“丹药”出来了,怎么出来的我也不知道。
gcForest使用级联的森林结构来进行表征学习,需要很少的训练数据,就能获得很好的性能,而且基本不怎么需要调节超参数的设置。gcForest不是要推翻深度神经网络,也不是以高性能为目的的研究,只是在深度结构研究方面给我们提供了一些思路,而且确实在一些应用领域获得了很好的结果,是一项很有意义的研究工作。
二、算法介绍
这种方法生成一个深度树集成方法(deep forest ensemble method),使用级联结构让gcForest学习。
gcForest模型把训练分成两个阶段:Multi-Grained Scanning和Cascade Forest。Multi-Grained Scanning生成特征,Cascade Forest经过多个森林多层级联得出预测结果。
Cascade Forest(级联森林)
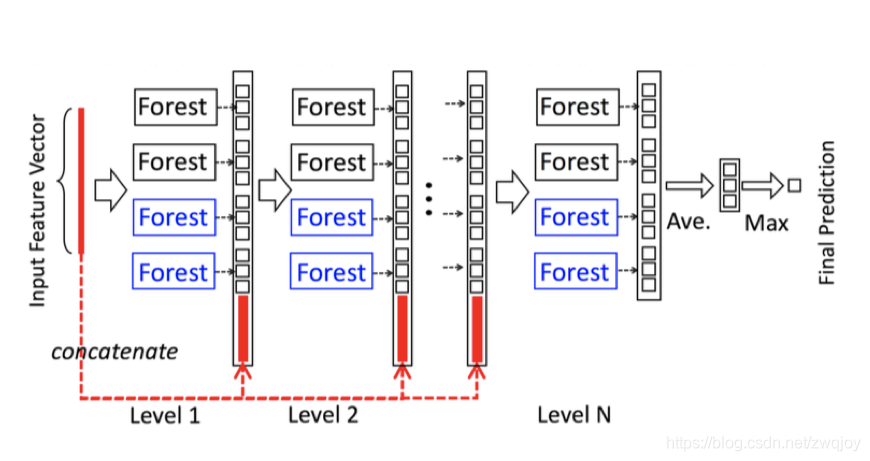
1. 级联中的每一级接收到由前一级处理的特征信息,并将该级的处理结果输出给下一级。
2. 级联的每个级别包括两个随机森林(蓝色字体标出)和两个完全随机树木森林(黑色)。[可以是多个,为了简单这里取了2种森林4个弱分类器]
3. 每个完全随机的树森林包含1000(超参数)个完全随机树,通过随机选择一个特征在树的每个节点进行分割实现生成,树一直生长,直到每个叶节点只包含相同类的实例或不超过10个实例。
4. 类似地,每个随机森林也包含1000(超参数)棵树,通过随机选择√d数量(输入特征的数量开方)的特征作为候选,然后选择具有最佳gini值的特征作为分割。(每个森林中的树的数值是一个超参数)
假设有三个类要预测; 因此,每个森林将输出三维类向量,然后将其连接输入特征以重新表示下一次原始输入。
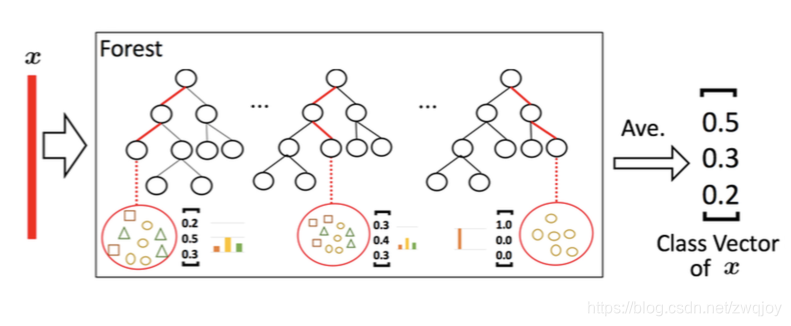
类别概率向量生成:
给定一个实例,每个森林会通过计算在相关实例落入的叶节点处的不同类的训练样本的百分比,然后对森林中的所有树计平均值,以生成对类的分布的估计。即每个森林会输出一个类别概率向量。
为了降低过拟合风险,每个森林产生的类向量由k折交叉验证(k-fold cross validation)产生。具体来说,每个实例都将被用作 k -1 次训练数据,产生 k -1 个类向量,然后对其取平均值以产生作为级联中下一级的增强特征的最终类向量。需要注意的是,在扩展一个新的级后,整个级联的性能将在验证集上进行估计,如果没有显着的性能增益,训练过程将终止;因此,级联中级的数量是自动确定的。与模型的复杂性固定的大多数深度神经网络相反,gcForest 能够适当地通过终止训练来决定其模型的复杂度(early stop)。这使得 gcForest 能够适用于不同规模的训练数据,而不局限于大规模训练数据。
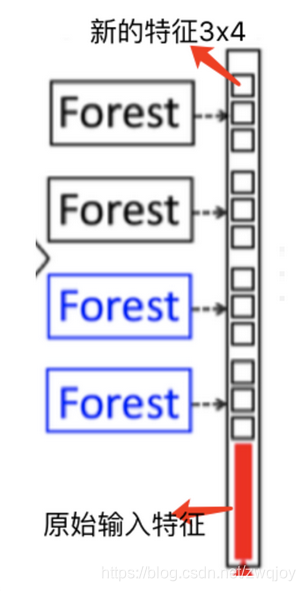
假设有三个类,则四个森林每一个都将产生一个三维的类向量,因此,级联的下一级将接收12 = 3×4个增强特征(augmented feature)则下一层的输入特征向量维度为(3×4 + length of x)。
Multi-Grained Scanning(多粒度扫描)
用多粒度扫描流程来增强级联森林,使用滑动窗口扫描的生成实例,输入森林后结果合并,生成新的特征。
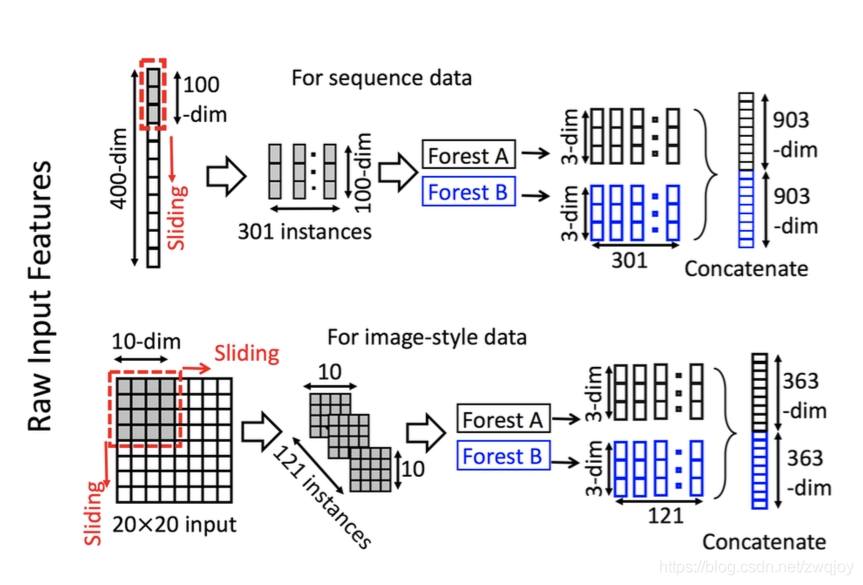
对于400维的序列数据,采用100维的滑动窗对输入特征进行处理,得到301(400 - 100 + 1)个100维的特征向量。
对于20×20的图像数据,采用10×10的滑动窗对输入特征进行处理,得到121((20-10+1)*(20-10+1))个10×10的二维特征图。
然后将得到的特征向量(或特征图)分别输入到一个completely-random tree forest和一个random forest中(不唯一,也可使用多个森林),以三分类为例,会得到301(或121)个3维类分布向量,将这些向量进行拼接,得到1806(或726)维的特征向量。
维度变化:1个实例400维->301个实例100维->2棵森林301个实例3维->1806维(2x301x3)
维度变化:1个实例20*20->121个实例10*10->2棵森林121个3维->726维(2x121x3)
整体流程
阶段1:
1. 利用滑动窗口切分成多实例特征向量,经过森林变换输出类别概率向量。
2. 合并类别概率向量生成新的特征。
阶段2:
3. 输入特征经过森林输出类别概率向量,连接原始输入作为下一层输出。
4. 经过多个级联森林,输出最终的类别概率向量。
5. 对多个森林输出的类别概率向量求类别的均值概率向量,取最大的类别概率为预测结果。
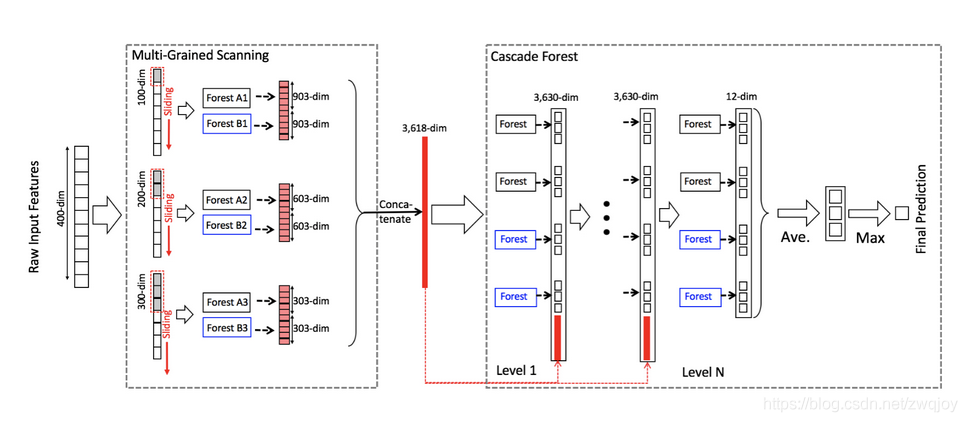
使用多粒度扫描对输入特征进行预处理。以使用三个尺寸的滑动窗为例,分别为100-dim,200-dim和300-dim。输入数据为400-dim的序列特征,使用100-dim滑动窗会得到301个100-dim向量,然后输入到一个completely-random tree forest和一个random forest中,两个森林会分别得到的301个3-dim向量(3分类),将两个森林得到的特征向量进行拼接,会得到1806-dim的特征向量。同理,使用200-dim和300-dim滑动窗会分别得到1206-dim和606-dim特征向量
三、算法实现
gcForest模型的Python实现
GitHub上有两个star比较多的gcForest项目,这里要说明的是其中 是官方提供(由gcForest的作者之一Ji Feng维护)的一个Python版本。
目前gcForest算法的官方Python包并未托管在Pypi, 但v1.1.1支持Python3.5
1. 官方开源地址:https://github.com/kingfengji/gcForest
使用请参考:https://mp.csdn.net/postedit/84774888
2 实现基于Python3.x的gcForest version0.1.6版本(https://github.com/pylablanche/gcForest),但其功能要相对弱
四、总结
相比于深度神经网络,gcForest具有以下优点:
1. 对于某些领域,gcForest的性能较之深度神经网络具有很强的竞争力
2. gcForest所需参数少,较深度神经网络容易训练得多
3. gcForest具有少得多的超参数,并且对参数设置不太敏感,在几乎完全一样的超参数设置下,在处理不同领域的不同数据时,也能达到极佳的性能,即对于超参数设定性能鲁棒性高。
4. gcForest对于数据量没有要求,在小数据集上也能获得很好的性能。
5. gcForest训练过程效率高且可扩展,适用于并行的部署,其效率高的优势就更为明显。
参考
Paper:https://arxiv.org/abs/1702.08835v3
Github:https://github.com/kingfengji/gcForest
Website:http://lamda.nju.edu.cn/code_gcForest.ashx