Kubernetes的调度器是Kubernetes众多组件的一部分,独立于API服务器之外。调度器本身是可插拔的,任何理解调度器和API服务器之间调用关系的工程师都可以编写定制的调度器。本文后面的介绍将聚焦Kubernetes的默认调度器。如前所述,Kubernetes的调度器和API服务器是异步工作的,他们之间通过HTTP通讯。调度器通过和API服务器建立List&Watch连接来获取调度过程中需要使用的集群状态信息,例如节点的状态、Service的状态(用于Service内Pod的反亲和)、Controller的状态、所有未调度和已经被调度的Pod的状态等。
调度器工作步骤具体如下。
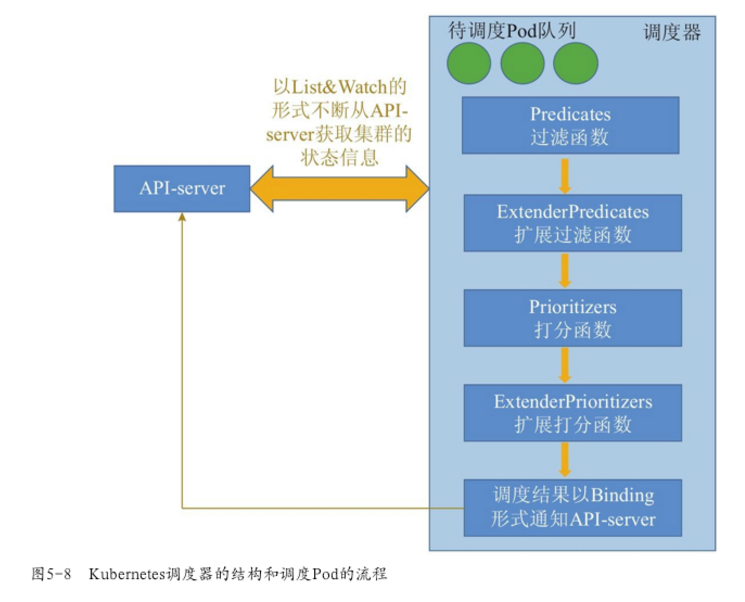
从待调度的Pod队列中取出一个Pod。
依次执行调度算法中配置的过滤函数(Predicate),得到一组符合Pod基本部署条件的节点的列表。过滤函数是一些“硬约束”,例如资源是否足够,Pod要求的Label是否满足等。
对上一步骤中得到的节点列表中的节点依次执行打分函数(Prioritizer),为各个节点进行打分。每个打分函数输出一个0~10之间的分数,最终一个节点的得分是各个打分函数输出分数的加权和(每个打分函数都有一个权值)。
对所有节点的得分由高到低排序,把排名第一的节点作为Pod的部署节点(如果不唯一则在所有得分最高的节点中随机选择一个),创建一个名为Binding的API对象,通知API服务器将被调度Pod的部署节点改为计算得到的节点。
目前Kubernetes的调度器支持多种维度的过滤和打分函数,考虑的因素包括但不限于:各个节点的Label(Pod可以通过LabelSelector指定自己希望部署在具有哪些Label的节点上);基于Service的反亲和;Pod对指定节点的反亲和;持久化硬盘的挂载情况检查;节点的端口使用情况;指定节点名字的部署等。调度过程中还会考虑资源使用情况,注意这里资源使用情况不是实时的资源使用情况,而是Pod中的各个Container的Request字段所指定的资源数量之和,调度器考虑候选节点能否满足该Pod的Request资源请求。关于Pod或Container的Request资源,请参考Kubernetes中关于Pod的QoS(QualityofService)的介绍,此处不再赘述。Kubernetes支持用户自定义调度算法,即可以通过模板配置使用哪些过滤和打分函数。用户也可以根据自己的需求编写相应的过滤或者打分函数作为调度函数库的一部分,并放到自定义调度算法中。除了自定义/编写调度算法,Kubernetes还支持Extender机制来进一步扩展调度逻辑,用户可以在系统中另外启动一个SchedulerExtender,其中可以包含其他自定义的过滤或者打分函数,每当默认调度器的过滤和打分函数执行之后,调度器可以分别调用(HTTP调用)Extender中的过滤和打分函数形成最终的调度结果。
图5-8简单描述了调度器的调度过程。
Kubernetes调度器在调度过程中还会搜集调度的延时数据,为工程师提供数据支持,统计的延时数据包括以下几点。端到端调度延时:从待调度队列中取出到Binding生效的间隔。调度算法延时:从开始执行第一个过滤函数到计算得到最终部署节点的间隔。Binding生效延时:从调度器向API服务器发送Binding请求到收到回复成功(即Binding生效)的间隔。除了上面提到的在调度算法库中添加新的函数和使用Extender外,Kubernetes还支持同时使用多个调度器来对不同类型的Pod进行调度。用户只需要在Pod的Annotation的中填写“scheduler.alpha.kubernetes.io/name:my-scheduler”便可以指定该Pod仅可以被名为my-scheduler的调度器调度,默认调度器或其他名字的调度器不会为Pod进行调度。为了提高调度器的吞吐量,社区贡献者让调度器缓存一些集群信息来提高调度决策的速度,缓存的信息包括节点的资源信息,已部署Pod的信息等,另外充分利用Go语言的特性对过滤和打分过程进行并行处理。目前调度器可以达到至少支持数百个Pod每秒的调度吞吐量,具体数值和集群的规模和Pod数目有关。未来,Kubernetes还会添加Re-scheduler来进一步强化Kubernetes集群资源配置的运行时优化,与Kubernetes的调度器、QoS分类等一起,实现更加高效容器集群资源管理。
- 当新增一个容器时,集群会在可用的集群节点中寻找最合适的节点来运行相应的容器。
- 首先,集群会排出如下节点:
a. 节点状态为不可用的“如节点不通或者k8s服务运行异常等”;
b. 节点剩余的CPU,内存资源不足以运行容器的;
c. 容器运行时占用的宿主机端口出现冲突的;
d. 按照节点选择label不匹配的; - 在排除不符合的节点之后,剩下的节点均为候选节点。容器具体调度到集群的哪台宿主机上,由调度器的积分机制决定。
- 例如节点A的打分将由如下公式决定:
finalScoreNodeA = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + ……
这里,有不同的评价策略以及其权重。每个节点获得的分值为节点按照各个评价策略及权重加和的值。 - 默认的选择策略如下:
LeastRequestedPriority
打分标准公式如下:
cpu ( ( capacity - sum ( requested ) ) * 10 / capacity) + memory ( ( capacity - sum ( requested) ) * 10 / capacity ) /2
例如CPU的可用资源为100,运行容器申请的资源为15,则cpu分值为8.5分,内存可用资源为100,运行容器申请资源为20,则内存分支为8分。则此评价规则在此节点的分数为(8.5 +8) / 2 = 8.25分。
BalanceResourceAllocation
打分标准公式如下:
score = 10 -abs ( cpuFraction - memoryFraction ) * 10
其中, cpuFraction = requested / capacity, memoryFraction = requested / capacity
该调度策略是出于平衡度的考虑,避免出现CPU,内存消耗不均匀的事情。例如某节点的CPU剩余资源还比较充裕,假如为100,申请10,则cpuFraction为0.1,而内存剩余资源不多,假如为20,申请10,则memoryFraction为0.5,这样由于CPU和内存使用不均衡,此节点的得分为10-abs ( 0.1 - 0.5 ) * 10 = 6 分。假如CPU和内存资源比较均衡,例如两者都为0.5,那么代入公式,则得分为10分。
CalculateSpreadPriority
此处的打分原则是:
Score = 10 * ((maxCount -counts)/ (maxCount))
这里主要针对多实例的情况下使用。例如,一个web服务,可能存在5个实例,例如当前节点已经分配了2个实例了,则本节点的得分为10*((5-2)/ 5)=6分,而没有分配实例的节点,则得分为10 * ((5-0) / 5)=10分。没有分配实例的节点得分越高。 - 默认的各个调度的策略权重为1,因此,调度的结果为各个调度策略得分的和,然后按照得分进行排序处理。
- 通过如上的评判标准,k8s积分制评价出各个节点的得分值,按照得分多少,将容器运行在最佳节点上。
- 另:节点的调度规则是采用的plugin方式,可自行编写调度策略进行调度打分处理。