(本文基于Kubernetes v1.7)
概述
调度器Scheduler是Kubernetes的重要组件之一。其作用是要将待调度的Pod依据某调度策略调度到最适合它运行的节点上运行。这里就涉及到三个对象:待调度的Pod、调度策略、待部署的节点队列。
我们先来看下Scheduler及其相关联组件的框架图。然后再聊下Scheduler的调度策略。
Scheduler及相关联组件框架图
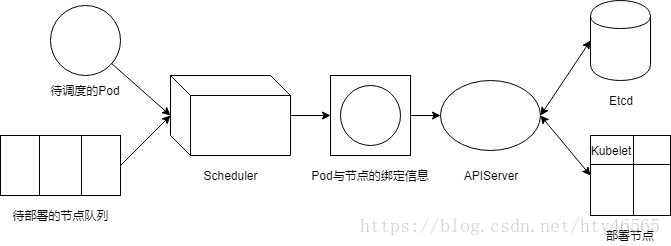
我们可以看到,调度器相当于一个黑盒子,输入待调度的Pod及待部署的节点队列,则会输出一个Pod与某节点的绑定信息。也就是说,经过调度器的调度,一个Pod就会与一个特定的节点相关联。接下来这个绑定信息则会通过APIServer这个入口组件输入给Etcd存储起来。Etcd是一个强一致、高可用的服务发现存储仓库,里面存储了Kubernetes的许多重要信息。接下来与该待调度Pod绑定的节点上的Kubelet会通过APIServer监听Etcd,发现自己所在节点被绑定了,那么就会依据Pod的信息开始进行容器在该节点的创建工作。
Scheduler的调度策略
Scheduler的调度流程分为两步:预选调度、优选调度。
预选调度:简单说就是筛选出可以被调度的节点。像是节点有故障或者资源不够Pod的申请量等情况肯定是不能作为被调度的节点的。
优选调度:从刚才预选调度中筛选出来的可以被调度的节点中再一次进行筛选。这次要挑出来一个最适合被调度的节点。
预选调度
首先我们看下预选调度中的调度策略有哪些:
(1)NoDiskConflict:判断待调度Pod的GCEPersistentDisk或AWSElasticBlockStore和备选节点中的Pod是否存在冲突。
(2)PodFitsResources:判断备选节点的资源是否满足待调度Pod的需求。
(3)PodFitsPorts:判断备选Pod所用的端口列表中的端口是否在备选节点中已被占用。
(4)MatchNodeSelector:检查Node节点的label定义是否满足Pod的NodeSelector属性的要求。该策略以后会被NodeAffinity取代。
(5)HostName:检查主机名称是否是Pod指定的NodeName。
(6)NoVolumeZoneConflict:检查给定的zone限制前提下,如果在此主机中部署Pod是否存在卷冲突。
(7)PodToleratesNodeTaints:确保Pod定义的tolerates能接纳Node定义的taints。
(8)CheckNodeMemoryPressure:检查Pod是否可以调度到已经报告了主机内存压力过大的节点。
(9)CheckNodeDiskPressure:检查Pod是否可以调度到已经报告了主机存储压力过大的节点。
(10)MaxEBSVolumeCount:确保已挂载的EBS存储卷不超过设置的最大值,默认39
(11)MaxGCEPDVolumeCount:确保已挂载的GCE存储卷不超过设置的最大值,默认16
(12)MaxAzureDiskVolumeCount:确保已挂载的Azure存储卷不超过设置的最大值,默认16
(13)MatchInterPodAffinity:检查Pod和其他Pod是否符合亲和性规则。
(14)GeneralPredicates:检查Pod与主机上Kubernetes相关组件是否匹配。
(15)NodeVolumeNodeConflict:检查给定的Node限制前提下,如果在此主机中部署Pod是否存在卷冲突。
优选调度
经过了上面预选调度的筛选,剩下的节点就都是可以被调度的节点了。
那么,我们需要从这些节点中选择出一个最适合的节点,该如何选择呢?
最简便靠谱的方法当然是给每一个节点都得一个分值,分值最高者则是最适合的节点。
因此,我们给出判断一个节点是否合适作为被调度节点的一些标准,每个标准都会得出一个分值,这些标准分值的加权总和则是该节点的得分了。
下面我们看一下这些标准是什么:
(1)EqualPriority:所有节点同样优先级,无实际效果。(默认不加载)
(2)ImageLocalityPriority:根据主机上是否已具备Pod运行的环境来打分,得分计算:不存在所需镜像,返回0分,存在镜像,镜像越大得分越高
(3)LeastRequestedPriority:计算Pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优,得分计算公式:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
(4)BalancedResourceAllocation:节点上各项资源(CPU、内存)使用率最均衡的为最优,得分计算公式:10 – abs(totalCpu/cpuNodeCapacity-totalMemory/memoryNodeCapacity)*10
(5)SelectorSpreadPriority:按Service和Replicaset归属计算Node上分布最少的同类Pod数量,得分计算:数量越少得分越高
(6)NodeAffinityPriority:节点亲和性选择策略,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求)
(7)TaintTolerationPriority:类似于Predicates策略中的PodToleratesNodeTaints,优先调度到标记了Taint的节点。
(8)InterPodAffinityPriority:pod亲和性选择策略,类似NodeAffinityPriority,提供两种选择器支持:requiredDuringSchedulingIgnoredDuringExecution(保证所选的主机必须满足所有Pod对主机的规则要求)、preferresDuringSchedulingIgnoredDuringExecution(调度器会尽量但不保证满足NodeSelector的所有要求),两个子策略:podAffinity和podAntiAffinity。
(9)MostRequestedPriority:动态伸缩集群环境比较适用,会优先调度pod到使用率最高的主机节点,这样在伸缩集群时,就会腾出空闲机器,从而进行停机处理。
Scheduler调度算法的注册
Kubernetes调度器的调度流程是通过插件方式加载的AlgorithmProvider具体实现的。一个AlgorithmProvider其实就是包括了一组预选策略和一组优选策略的结构体。
注册默认AlgorithmProvider的函数如下:
factory.RegisterAlgorithmProvider(factory.DefaultProvider, defaultPredicates(), defaultPriorities())
它包含三个参数:“factory.DefaultProvider”参数为默认调度算法名;“defaultPredicates()”参数为算法用到的默认预选策略集合;“defaultPriorities()”为算法用到的默认优选策略集合。
当然,我们也可以根据自己具体的场景需求来自定义更适合自己的调度策略进行加载。
总结
本文主要从原理角度宏观的概述了Kubernetes的调度器,包括调度器做了什么、怎么做,也提了一下调度器的算法注册函数。对于具体这些策略怎么使用,要视不同的使用场景而定。