https://blog.csdn.net/u011501388/article/details/78410705
Fisher Vector(FV)是一种类似于BOVW词袋模型的一种编码方式,如提取图像的SIFT特征,通过矢量量化(KMeans聚类),构建视觉词典(码本),FV采用混合高斯模型(GMM)构建码本,但是FV不只是存储视觉词典的在一幅图像中出现的频率,并且FV还统计视觉词典与局部特征(如SIFT)的差异。在讲解Fisher Vector(FV)之前,先对FV有一个总体的认识,先看一下FV的代码实现。
FV采用GMM构建视觉词典,为了可视化,这里采用二维的数据,当然这里的数据可以是SIFT或其它局部特征,具体实现代码如下:
- %采用GMM模型对数据data进行拟合,构建视觉词典
- numFeatures = 5000 ; %样本数
- dimension = 2 ; %特征维数
- data = rand(dimension,numFeatures) ; %这里随机生成一些数据,这里data可以是SIFT或其它局部特征
- numClusters = 30 ; %视觉词典大小
- [means, covariances, priors] = vl_gmm(data, numClusters); %GMM拟合data数据分布,构建视觉词典
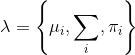
这里用GMM构建视觉词典也存在一个问题,这是GMM模型固有的问题,就是当GMM中的高斯函数个数,也就是聚类数,也就是numClusters,若与真实的聚类数不一致的话,GMM表现的不是很好(针对期望最大化EM方法估计参数
接下来,我们创建另一组随机向量,这些向量用Fisher Vector和刚获得的GMM来编码,具体代码如下:
- numDataToBeEncoded = 1000;
- dataToBeEncoded = rand(dimension,numDataToBeEncoded);
encoding = vl_fisher(datatoBeEncoded, means, covariances, priors);
如上代码片段中的encoding就是dataToBeEncoded数据的FV表示。为了提升性能,FV表示还要经过白化与归一化,具体参见 VLFeat。
现在我们已经对FV已经有了一个整体的认识,下面讲述FV的原理。
现设
- 为从图像中提取的<span style="font-size:14px;">一个D维的</span>特征向量(如SIFT描述子等),设
- 为高斯混合模型GMM拟合描述子概率分布所得的参数。在得到GMM的参数后,GMM也就确定了。现在给定一个特征描述子向量,它属于某个高斯分布(GMM中共有K个高斯分布函数)的后验概率为:

对于每个模式k(也就是GMM中的单个高斯分布),考虑均值和协方差偏差向量,得到:

在上式中
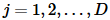
把GMM中的每个模式

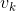

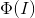
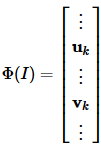
为了提升FV性能,得到的FV还要经过白化,Power Normalization和
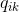
FK推导了一种数据和拟合数据得到的生成模型
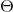


协方差矩阵可以通过生成模型得到(由生成模型生成的数据已经被中心化)如下所示:

注意,H也是模型的Fisher信息矩阵。最终的FV编码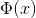

取两个这样的向量的内积产生Fisher核:
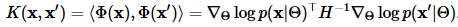
可以看出,FV编码相当于FK的映射函数。
参考:
1. 聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut
2. 漫谈 Clustering (3): Gaussian Mixture Model
3. Fisher Vector and VLAD 4. Fisher vector fundamentals