转自:http://blog.csdn.net/wzmsltw/article/details/52040010
参考的博客内容:
http://blog.csdn.net/ikerpeng/article/details/41644197 从高斯分布开始介绍了FV,比较易于理解
http://blog.csdn.net/happyer88/article/details/46576379
http://blog.csdn.net/garfielder007/article/details/50767716
完整介绍Fisher Vector方法的论文
"ImageClassification with the Fisher Vector: Theory and Practice"
Fisher Vector的详细概念可以见以上的几篇博文(或是直接看论文)。下面主要从FV的计算步骤的角度进行介绍。首先给出以上的论文中的算法步骤做参考:

对于一副图像,提取T个描述子(比如SIFT,比如iDT),每个描述子是D维的,那么可以用 X={xt , t= 1…T}来描述这张图片。这里做一个假设,假设这t个描述子独立同分布(i.i.d)。那么则有:
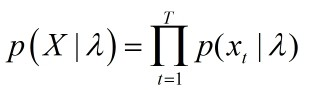
取对数后可以得到:
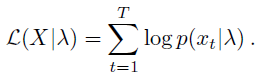
此处的lamda为描述独立同分布的参数。现在要用一组K个高斯分布的线性组合(即GMM混合高斯模型)来逼近这个分布,其参数即为lamda。GMM模型可以用下式描述:
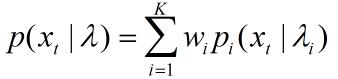
其中pi为第i个高斯分布
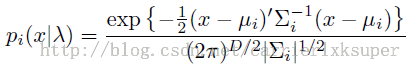
以下参数lamda,注意此处的lamda在计算FV时是已知量,是预先通过GMM求解得到的先验值:
wi为系数,wi>=0,sum(wi)=1。另外两个参数为高斯分布中的平均值和标准差。
在计算之前先定义占有概率,即特征xt由第i个高斯分布生成的概率:
对各个参数求偏导可以得到
注意此处的i是指第i个高斯分布,d是指xt的第d维,因此得到的结果数目为 w:K-1个;均值:K*D个;标准差K*D个。因此共有(2D+1)*K-1个偏导结果,这里的-1是由于wi的约束。
在计算完之后,还需要进行归一化。对三种变量分别计算归一化需要的fisher matrix的对角线元素的期望:
此处T为最开始的描述子的数目。最终归一化后的fisher vector的结果为:
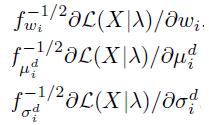
在上面提及的”Image Classification with the Fisher Vector: Theory andPractice“一文中,对最后的归一化步骤进行了改进。先对fisher vector中的每个值做功率归一化,再对fisher vector做L2正则化得到最后的结果。
综上所述,基于Fisher Vector的图像学习的完整过程应该描述为下面几个步骤。
1.选择GMM中K的大小
1.用训练图片集中所有的特征(或其子集)来求解GMM(可以用EM方法),得到各个参数;
2.取待编码的一张图像,求得其特征集合;
3.用GMM的先验参数以及这张图像的特征集合按照以上步骤求得其fv;
4.在对训练集中所有图片进行2,3两步的处理后可以获得fishervector的训练集,然后可以用SVM或者其他分类器进行训练。
经过fisher vector的编码,大大提高了图像特征的维度,能够更好的用来描述图像。FisherVector相对于BOV的优势在于,BOV得到的是一个及其稀疏的向量,由于BOV只关注了关键词的数量信息,这是一个0阶的统计信息;FisherVector并不稀疏,同时,除了0阶信息,Fisher Vector还包含了1阶(期望)信息、2阶(方差信息),因此FisherVector可以更加充分地表示一幅图片。