概率分布估计方法
想要估计一个数列的概率分布,可以使用概率密度估计方法。这种方法可以通过样本数据来估计概率密度函数或者分布函数。以下是一些常用的概率密度估计方法:
核密度估计(KDE)
核密度估计(KDE):KDE是一种非参数估计方法,它可以通过样本数据来估计概率密度函数。KDE的基本思想是将每个样本点看作一个高斯分布,然后将所有高斯分布叠加起来得到概率密度函数1。
核密度估计(Kernel Density Estimation,KDE)是一种非参数的概率密度估计方法,它可以通过样本数据来估计概率密度函数。KDE的基本思想是将每个样本点看作一个高斯分布,然后将所有高斯分布叠加起来得到概率密度函数。KDE的优点在于它不需要假设数据的分布形式,因此可以适用于各种类型的数据。以下是KDE的一些特点:
- KDE是一种非参数估计方法,因此不需要对数据的分布形式进行假设。
- KDE可以通过样本数据来估计概率密度函数,因此可以适用于各种类型的数据。
- KDE的估计结果具有很好的光滑性,因此可以用于数据的可视化。
- KDE的估计结果对带宽参数的选择比较敏感,因此需要选择合适的带宽参数。
KDE的实现方法有很多种,其中最常用的是基于高斯核函数的方法。具体来说,对于每个样本点,可以将其看作一个高斯分布,然后将所有高斯分布叠加起来得到概率密度函数。
- 核密度估计Kernel Density Estimation(KDE)及python代码 - 知乎 (zhihu.com):从简单逐渐推广到复杂,这才是真正好的学习路线
- 【seaborn】kdeplot用法 & 核密度估计(KDE)原理介绍_kdeplot中的density如何计算-CSDN博客
- 核密度估计图(Kernel Density Estimation, KDE) - 知乎 (zhihu.com)
python实现:
import plotly.graph_objects as go
from scipy.stats import gaussian_kde
# 计算概率密度函数
density = gaussian_kde(metrics_df[fea])
x_values = np.linspace(min(metrics_df[fea]), max(metrics_df[fea]), 200)
density_values = density(x_values)
# 创建柱状图
fig = go.Figure()
fig.add_trace(go.Histogram(x=metrics_df[fea], nbinsx=50, name='Histogram', yaxis='y1'))
# 创建概率密度曲线
fig.add_trace(go.Scatter(x=x_values, y=density_values, mode='lines', name='Density', yaxis='y2'))
# 设置图像布局
fig.update_layout(
title_text=title,
yaxis=dict(title='Histogram'),
yaxis2=dict(title='Density', overlaying='y', side='right')
)
fig.show()
直方图法
直方图法:直方图法是一种简单的概率密度估计方法,它将样本数据划分为若干个区间,然后计算每个区间的频率。最后,将频率除以区间长度得到概率密度2。
[直方图法是一种简单的概率密度估计方法,它将样本数据划分为若干个区间,然后计算每个区间的频率。最后,将频率除以区间长度得到概率密度。以下是制作直方图的一些步骤:
- 将样本数据划分为若干个区间,每个区间的长度相等。
- 统计每个区间内的样本数量,得到频数。
- 计算每个区间的频率,即频数除以样本总数。
- 将频率除以区间长度,得到概率密度。
- 用概率密度作为纵坐标,区间的中点作为横坐标,绘制直方图。
直方图法的优点在于它简单易用,可以通过直观的图形来展示数据的分布情况。但是,直方图法也有一些缺点。例如,直方图法对区间的选择比较敏感,不同的区间选择可能会导致不同的结果。此外,直方图法也不能很好地处理缺失数据和异常值。
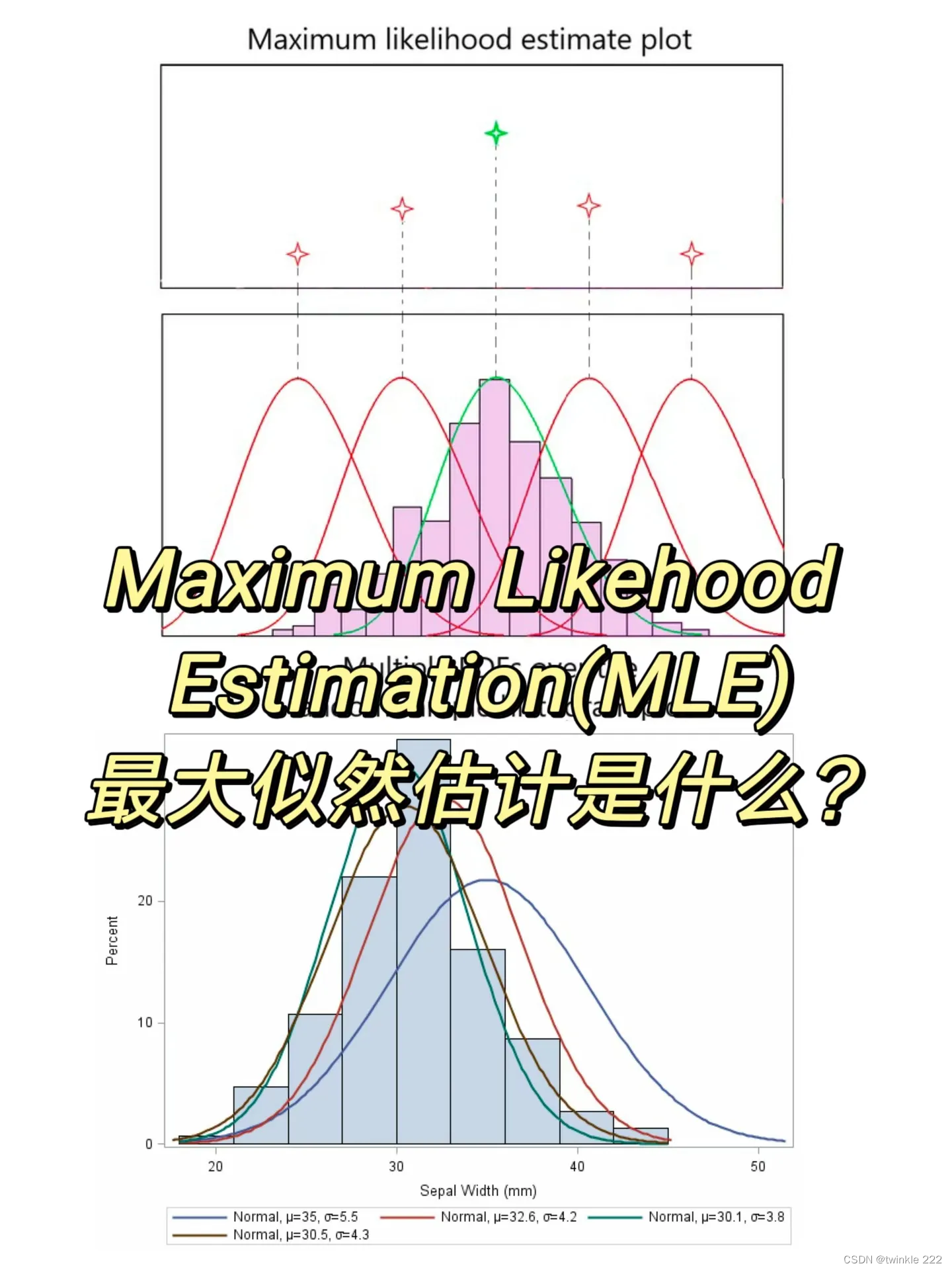
最大似然估计(MLE)
最大似然估计(MLE):MLE是一种参数估计方法,它可以通过样本数据来估计分布函数的参数。MLE的基本思想是选择一组参数,使得样本数据出现的概率最大3。
最大似然估计(Maximum Likelihood Estimation,MLE)是一种参数估计方法,它可以通过样本数据来估计分布函数的参数。MLE的基本思想是选择一组参数,使得样本数据出现的概率最大。以下是MLE的一些特点:
- MLE是一种参数估计方法,因此需要对数据的分布形式进行假设。
- MLE可以通过样本数据来估计分布函数的参数,因此可以适用于各种类型的数据。
- MLE的估计结果具有很好的光滑性,因此可以用于数据的可视化。
- MLE的估计结果对初始值的选择比较敏感,因此需要选择合适的初始值。
MLE的实现方法有很多种,其中最常用的是基于最大似然函数的方法。具体来说,对于每个样本点,可以计算其出现的概率密度函数,然后将所有概率密度函数的乘积作为似然函数。MLE的目标是找到使似然函数最大的参数值。通常情况下,MLE的求解需要使用数值优化算法,例如梯度下降算法。