一、将图像复制到训练、验证和测试的目录
#原始数据集解压目录的路径
original_dataset_dir = "F:/图像视觉/pdf/学习记录/pytorch与深度学习/dogs-vs-cats/dogs-vs-cats/train/"
#保存较小数据集的目录
base_dir = "F:/图像视觉/pdf/学习记录/python深度学习_费朗索瓦/cats_and_dogs_small/"
os.mkdir(base_dir)
#分别对应划分后的训练、验证、和测试的目录
train_dir = os.path.join(base_dir,'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
os.mkdir(test_dir)
#猫的训练图像目录
train_cats_dir = os.path.join(train_dir,'cats')
os.mkdir(train_cats_dir)
#狗的训练图像目录
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_dogs_dir,fname)
shutil.copyfile(src,dst)
查看每个分组中包含多少张图像
print('total training cat images:',len(os.listdir(train_cats_dir)))
print('total training dog images:',len(os.listdir(train_dogs_dir)))
print('total validation cat images:',len(os.listdir(validation_cats_dir)))
print('total validation dog images:',len(os.listdir(validation_dogs_dir)))
二、构建网络
model = models.Sequential()
model.add(layers.Conv2D(32,(5,5),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
配置模型及优化器
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
三、数据预处理
使用ImageDataGenerator从目录中读取图像
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150,150),
batch_size=20,class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,target_size=(150,150),
batch_size=20,class_mode='binary')
我们来看一下其中一个生成器的输出:它生成了一个150×150的RGB图像[形状为(20,150,150,20)]与二进制标签[形状为(20,)]组成的批量。每个批量中包含20个样本(批量大小)。注意生成器会不停地生成这些批量,他会不断循环目标文件夹中的图像。因此,你需要在某个时候终止(break)迭代循环。
for data_batch,labels_batch in train_generator:
print('data batch shape:',data_batch.shape)
print('labels batch shape:',labels_batch.shape)
break
利用批量生成器拟合模型
history = model.fit_generator(train_generator,steps_per_epoch=100,epochs=20,validation_data=validation_generator,validation_steps=50)
保存模型
model.save('cats_and_dogs_small_1.h5')
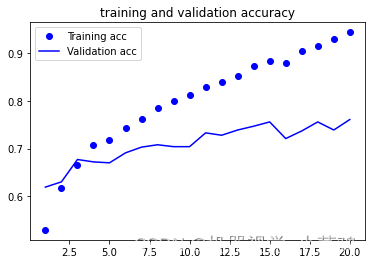
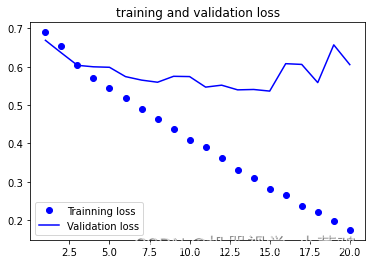
绘制损失曲线和精度曲线
import matplotlib.pyplot as plt
acc =history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc)+1)
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(epochs,val_acc,'b',label='Validation acc')
plt.title("training and validation accuracy")
plt.legend()
plt.figure()
plt.plot(epochs,loss,'bo',label='Trainning loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title("training and validation loss")
plt.legend()
plt.show()
参考教材《Python深度学习》