目录
0. 前言
之前用过一些很厉害的模型,图像分类领域的VGG16,目标检测领域的YoloV5,实例分割领域的Yolact等。但只是会配置好环境之后训练,最多稍微修改下源码的接口满足自己的需求。还从来没有用PyTorch从头搭建并训练一个模型出来。
正好最近在较为系统地学PyTorch,就总结一下如何从头搭建并训练一个神经网络模型。
1. 使用torchvision加载数据集并做预处理
我们使用的数据集是CIFAR10,该数据集有10个类别,图像尺寸为3 x 32 x 32,如下所示:

代码如下,重要地方代码中有注释
import torch
import cv2
import numpy as np
from torchvision import datasets, transforms
import torchvision
# 1. 使用torchvision加载数据集并做预处理
transform = transforms.Compose([transforms.ToTensor(), # 把图像转换为tensor
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)), # 归一化处理
])
# 加载训练集和测试集
trainset = torchvision.datasets.CIFAR10(root='E:\\Machine Learning\\PyTorch\\CIFAR10', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='E:\\Machine Learning\\PyTorch\\CIFAR10', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
2. 定义(搭建)自己的神经网络
代码及注释如下,整个结构很简单,就是两个卷积层,两个最大池化层,最后连接三个全连接层。
# 2. 定义卷积神经网络
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module): # 继承nn.Module
# 定义网络结构
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Net = MyModel()
这里解释一下为什么第一个全连接层的输入大小为16x5x5,16是因为最后的卷积层有16个filter(即输出的feature map有16个channel),后面的5x5并不是因为最后卷积层的kernel大小为5x5,而是因为最后的feature map大小为5x5,至于为什么是5x5可以按照下面的图算一下:
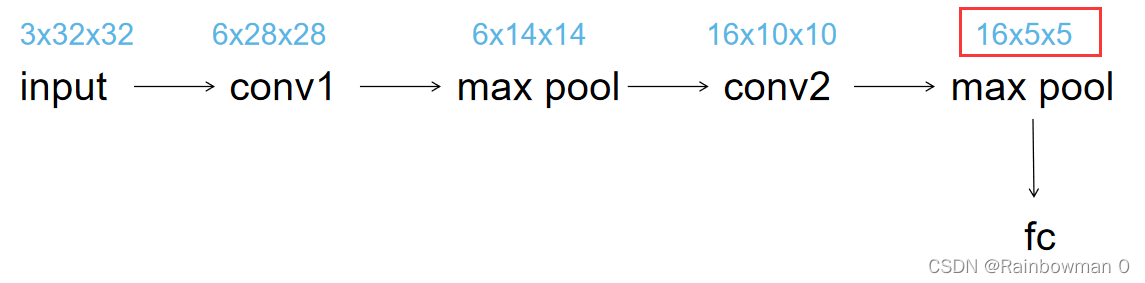
3. 定义损失函数(Loss Function)和优化器(Optimizer)
神经网络的反向传播需要损失函数,因为是多分类问题,所以我们用交叉熵损失函数:
# 3. 定义损失函数和优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss() # 多分类问题,用交叉熵损失函数
optimizer = optim.SGD(Net.parameters(), lr=0.001, momentum=0.9) # 用SGD优化器
4. 训练神经网络
接着开始训练我们的模型,共训练2个epoch,batch_size=4,先用CPU训练,看看时间如何。
# 4. 训练神经网络
epochs = 2 # 训练两个epoch,batch_size = 4 (batch_size的大小定义在第一步torch.utils.data.DataLoader中)
e1 = cv2.getTickCount() # 记录训练时间
for epoch in range(epochs):
total_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 得到inputs
inputs, labels = data
optimizer.zero_grad()
# forward + backward + optimize
# 前向传播+反向传播+更新参数
outputs = Net(inputs) # 前向传播,得到outputs
loss = criterion(outputs, labels) # 得到损失函数
loss.backward() # 后向传播
optimizer.step() # 更新参数
# 输出训练过程
total_loss += loss.item()
if (i+1) % 1000 == 0: # 每1000次(就是4000张图像)输出一次loss
print('第{}个epoch:第{:5d}次:目前的训练损失loss为:{:.3f}'.format(epoch+1, i+1, total_loss/1000))
total_loss = 0.0
e2 = cv2.getTickCount()
print('用CPU训练总共用时:{} s'.format((e2-e1)/cv2.getTickFrequency()))
# 输出结果:
第1个epoch:第 1000次:目前的训练损失loss为:2.294
第1个epoch:第 2000次:目前的训练损失loss为:2.087
第1个epoch:第 3000次:目前的训练损失loss为:1.902
第1个epoch:第 4000次:目前的训练损失loss为:1.799
第1个epoch:第 5000次:目前的训练损失loss为:1.709
第1个epoch:第 6000次:目前的训练损失loss为:1.660
第1个epoch:第 7000次:目前的训练损失loss为:1.623
第1个epoch:第 8000次:目前的训练损失loss为:1.586
第1个epoch:第 9000次:目前的训练损失loss为:1.550
第1个epoch:第10000次:目前的训练损失loss为:1.497
第1个epoch:第11000次:目前的训练损失loss为:1.468
第1个epoch:第12000次:目前的训练损失loss为:1.469
第2个epoch:第 1000次:目前的训练损失loss为:1.392
第2个epoch:第 2000次:目前的训练损失loss为:1.382
第2个epoch:第 3000次:目前的训练损失loss为:1.364
第2个epoch:第 4000次:目前的训练损失loss为:1.361
第2个epoch:第 5000次:目前的训练损失loss为:1.344
第2个epoch:第 6000次:目前的训练损失loss为:1.349
第2个epoch:第 7000次:目前的训练损失loss为:1.313
第2个epoch:第 8000次:目前的训练损失loss为:1.327
第2个epoch:第 9000次:目前的训练损失loss为:1.306
第2个epoch:第10000次:目前的训练损失loss为:1.302
第2个epoch:第11000次:目前的训练损失loss为:1.275
第2个epoch:第12000次:目前的训练损失loss为:1.288
用CPU训练总共用时:83.7945317 s
用时83.79秒。
5. 测试模型结果
# 5. 测试模型准确率如何
correct = 0
total = 0
e1 = cv2.getTickCount() # 记录测试时间
with torch.no_grad(): # 不跟踪梯度
for data in testloader:
images, labels = data
outputs = Net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
e2 = cv2.getTickCount()
print('用CPU测试总共用时:{} s'.format((e2-e1)/cv2.getTickFrequency()))
print('在测试集上的准确率为:{:.3f}%'.format(correct*100/total))
我们来看看结果如何
# 结果
用CPU测试总共用时:5.3146039 s
在测试集上的准确率为:55.460%
准确率大概55%,虽然不高,但可以看出我们的模型确实学到了东西(因为10分类问题随机预测的话准确率在10%左右)。并且这个博客的目的在于梳理训练神经网络的大致流程,而非构建一个优秀的模型。
6. 嫌CPU太慢?换GPU训练并推测试试!
首先看看是否安装了对应版本的cuda和cudnn,具体安装步骤就不说了,csdn上很多优秀教程。
# 检测电脑上是否安装了对应版本的cuda
device = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')
print('设备名称: ', device)
print('查看cuda版本: ', torch.version.cuda)
# 结果
设备名称: cuda:0
查看cuda版本: 10.1
PyTorch使用GPU训练非常方便,相较于第4步用CPU训练,只需增加两行代码:
(1)把神经网络模型加载到cuda
(2)把数据加载到cuda
代码及注释如下:
# 6. 用GPU训练神经网络
###### 第1处不一样 ########
Net.to(device) # 把神经网络模型加载到cuda
epochs = 2 # 训练两个epoch,batch_size = 4 (batch_size的大小定义在第一步torch.utils.data.DataLoader中)
e1 = cv2.getTickCount() # 记录训练时间
for epoch in range(epochs):
total_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 得到inputs
inputs, labels = data
###### 第2处不一样 ########
inputs, labels = inputs.to(device), labels.to(device) # 把数据加载到cuda
optimizer.zero_grad()
# forward + backward + optimize
# 前向传播+反向传播+更新参数
outputs = Net(inputs) # 前向传播,得到outputs
loss = criterion(outputs, labels) # 得到损失函数
loss.backward() # 后向传播
optimizer.step() # 更新参数
# 输出训练过程
total_loss += loss.item()
if (i+1) % 1000 == 0: # 每1000次(就是4000张图像)输出一次loss
print('第{}个epoch:第{:5d}次:目前的训练损失loss为:{:.3f}'.format(epoch+1, i+1, total_loss/1000))
total_loss = 0.0
e2 = cv2.getTickCount()
print('用CPU训练总共用时:{} s'.format((e2-e1)/cv2.getTickFrequency()))
看看结果如何:
# 结果
第1个epoch:第 1000次:目前的训练损失loss为:2.231
第1个epoch:第 2000次:目前的训练损失loss为:2.032
第1个epoch:第 3000次:目前的训练损失loss为:1.872
第1个epoch:第 4000次:目前的训练损失loss为:1.745
第1个epoch:第 5000次:目前的训练损失loss为:1.702
第1个epoch:第 6000次:目前的训练损失loss为:1.634
第1个epoch:第 7000次:目前的训练损失loss为:1.603
第1个epoch:第 8000次:目前的训练损失loss为:1.548
第1个epoch:第 9000次:目前的训练损失loss为:1.513
第1个epoch:第10000次:目前的训练损失loss为:1.494
第1个epoch:第11000次:目前的训练损失loss为:1.459
第1个epoch:第12000次:目前的训练损失loss为:1.452
第2个epoch:第 1000次:目前的训练损失loss为:1.396
第2个epoch:第 2000次:目前的训练损失loss为:1.372
第2个epoch:第 3000次:目前的训练损失loss为:1.350
第2个epoch:第 4000次:目前的训练损失loss为:1.361
第2个epoch:第 5000次:目前的训练损失loss为:1.338
第2个epoch:第 6000次:目前的训练损失loss为:1.312
第2个epoch:第 7000次:目前的训练损失loss为:1.322
第2个epoch:第 8000次:目前的训练损失loss为:1.289
第2个epoch:第 9000次:目前的训练损失loss为:1.277
第2个epoch:第10000次:目前的训练损失loss为:1.269
第2个epoch:第11000次:目前的训练损失loss为:1.293
第2个epoch:第12000次:目前的训练损失loss为:1.283
用CPU训练总共用时:74.0288839 s
相较于CPU的83秒,GPU用了74秒,快了一些,但提升不够明显。这是因为我们的网络很小,参数也很少。另外我的笔记本的GPU也挺老的,1050核显。
我们在试试用GPU推断会加速多少:
# 6. 使用GPU推断
correct = 0
total = 0
Net.to(device) # 把神经网络模型加载到cuda
e1 = cv2.getTickCount() # 记录测试时间
with torch.no_grad(): # 不跟踪梯度
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device) # 把数据加载到cuda
outputs = Net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
e2 = cv2.getTickCount()
print('用CPU测试总共用时:{} s'.format((e2-e1)/cv2.getTickFrequency()))
print('在测试集上的准确率为:{:.3f}%'.format(correct*100/total))
看看结果如何
# 结果
用CPU测试总共用时:4.3125164 s
在测试集上的准确率为:54.090%
相较于CPU推断需要5.3秒,使用GPU推断需要4.3秒,速度也有提升。