文章目录
概要

最近,Segment Anything Model (SAM) 已经展示出了强大的分割能力,在计算机视觉领域引起了广泛关注。基于预训练的 SAM 的大量研究工作已经开发了各种应用,并在下游视觉任务上取得了令人印象深刻的性能。然而,SAM 包含重的架构,需要大量的计算能力,这阻碍了 SAM 在计算受限的边缘设备上的进一步应用。
为此,在本文中提出了一种框架,在保持强大的零样本性能的同时,获得一个微小的分割 anything 模型(TinySAM)。作者首先提出了一种全阶段知识蒸馏方法,采用在线硬提示采样策略来蒸馏一个轻量级的的学生模型。作者还适应了后训练量化到可提示的分割任务,并进一步降低了计算成本。
此外,作者提出了一种分层的分割 everything 策略,以将 everything 推理加速 2 倍,几乎不降低性能。通过所提出的所有方法,作者的 TinySAM 导致计算减少了数个数量级,并推动了高效分割 anything 任务的极限。在各种零样本迁移任务上的广泛实验表明,作者的 TinySAM 与对应方法相比具有显著的优势。
预训练模型和代码:
Pytorch:https://github.com/xinghaochen/TinySAM
MindSpore:https://gitee.com/mindspore/models/
整体架构流程
物体分割是计算机视觉领域的一个重要且基础的任务。广泛的视觉应用,如物体定位和验证,都依赖于准确的快速物体分割。许多先前的研究工作都关注于分割任务,包括语义分割,实例分割和全景分割。最近,Kirillov 引入了一个强大的分割 anything 模型(SAM),以及一个大规模的分割数据集 SA-1B,该数据集包含了 11 亿张图像上的超过 10 亿个Mask。具有任意形状和类别的目标的强大的分割能力,SAM 已成为许多下游任务的基础框架,如物体跟踪,图像修复 和 3D 视觉。此外,SAM 的强大零样本分割能力使医学影像等数据较少的研究领域受益。
尽管 SAM 在下游视觉任务上取得了令人印象深刻的性能,但复杂的架构和巨大的计算成本使得 SAM 在资源受限的设备上部署起来困难。SAM 模型对 1024×1024 图像的推理时间在现代 GPU 上可以达到 2 秒。一些最近的努力试图获得更高效的分割 anything 模型。例如,MobileSAM 试图用 TinyViT 轻量级架构替换图像编码器的重量组件。
但是,它只通过与教师网络的图像嵌入的解耦知识蒸馏策略,使用紧凑的图像编码器网络进行训练。这种部分训练策略不可避免地导致性能衰减,而没有最终Mask预测的监督。FastSAM 将分割 anything 任务转移到具有一个 foreground 类别的实例分割任务,与 Yolov8 配合使用。为了实现可提示的分割,FastSAM 应用了一种后处理策略与实例分割网络相结合。然而,这种改写的框架无法在下游零样本任务上达到与 SAM comparable 的性能。
为了进一步推动高效分割 anything 模型的极限,本文提出了一种完整的框架来获得 TinySAM,在降低计算成本的同时,尽可能地保持零样本分割能力。具体来说,作者提出了一种全阶段的知识蒸馏方法,以提高紧凑学生网络的能力。学生网络以端到端的方式,在教师网络不同阶段的监督下进行蒸馏。
此外,作者提出了一种在线硬提示采样策略,使蒸馏过程更加关注硬例子,从而提高最终性能。作者还将后训练量化适应到可提示的分割任务,并进一步降低计算成本。此外,作者发现,由于需要从网格提示点生成大量Mask,在图像上分割 everything 需要巨大的计算成本。
为此,作者提出了一种分层的分割 everything 策略,将 everything 推理加速 2 倍,几乎不降低性能。通过所提出的所有方法,作者的 TinySAM 导致了计算减少了数个数量级,并推动了高效分割 anything 任务的极限。例如,与原始 SAM 相比,TinySAM 可以实现 100 倍的加速。在各种零样本迁移任务上的广泛实验表明,作者的 TinySAM 与对应方法相比具有显著的优势。
Related Work
Segment Anything Model
最近提出的分割 anything 模型(SAM)在目标分割和下游视觉任务中证明了其通用性和灵活性。SAM 由三个子网络组成,即图像编码器、提示编码器和Mask解码器。图像编码器是一个基于重视觉 Transformer 的网络,它将输入图像提取成图像嵌入。提示编码器设计用于编码输入点、框、任意形状的Mask和自由形式文本,并使用位置信息。
几何提示和文本提示分别使用不同的网络进行处理。Mask解码器包含一个双向 Transformer ,将图像编码器和提示编码器的输出用于生成最终的Mask预测。与提出的 SA-1B 数据集相结合,该数据集包含 1.1 亿张高分辨率图像和超过 10 亿个高质量分割Mask,SAM 展示了针对任何类别和形状目标的令人印象深刻的高质量分割能力。
此外,SAM 在零样本下游视觉任务上展示了强大的泛化能力,包括边缘检测、目标 Proposal 、实例分割和文本到Mask预测。由于灵活的提示模式和高质量分割能力,SAM 被认为是视觉应用的基础模型。然而,SAM,尤其是图像编码器网络,包含大量参数,需要高计算能力进行部署。因此,在资源受限的边缘设备上应用 SAM 并不容易。SAM 的压缩和加速已成为一个重要的研究主题[49, 50]。
Knowledge Distillation
Hinton等人提出了一种知识蒸馏方法,通过教师网络的输出来监督轻量级学生网络的训练。自那时以来,知识蒸馏已成为在训练过程中改进紧凑网络性能的重要方法。知识蒸馏方法可以大致分为两类,即针对网络输出的蒸馏和针对中间特征的蒸馏。大多数关于知识蒸馏方法的研究都集中在图像分类任务上。后续的工作提出了用于高级计算机视觉任务(如目标检测和语义分割)的知识蒸馏方法。Zhang等人提出使用蒸馏方法来获得一个高效的分割 anything 模型(MobileSAM)。
然而,MobileSAM只使用图像和原始 SAM 的相应图像和图像嵌入来监督图像编码器网络。这种部分蒸馏策略可能导致轻量级学生网络从教师网络或Token数据中没有指导,无法获得Mask Level 信息,从而造成相当大的性能下降。
Quantization
模型量化也是常用的模型压缩方法之一,它将更高位宽的重量或激活值量化到较低位宽,以减少存储要求和计算复杂性,同时允许有限的准确性损失。模型量化方法可以分为两类,量化感知训练(QAT)和后训练量化(PTQ)。
QAT 方法需要一个带有标签的训练数据集和大量的训练成本,而 PTQ 方法只需要一个小型的无标签校准数据集,因此更加高效。许多先前的 PTQ 方法[30, 38]已经提出,以寻找卷积神经网络(CNN)的适当量化参数。
随着视觉 Transformer (ViT)在各种视觉任务上取得了显著的性能,最近的工作研究了如何将后训练量化应用于基于 ViT 的模型,并已使用 8 位量化配置实现了强大的性能。然而,对于提示性分割任务,尤其是分割 anything 模型,量化尚未得到充分探索。
3 Methodology
Overview of TinySAM
本文提出了一种框架,以获取高度高效的 SAM,如图 1 所示。
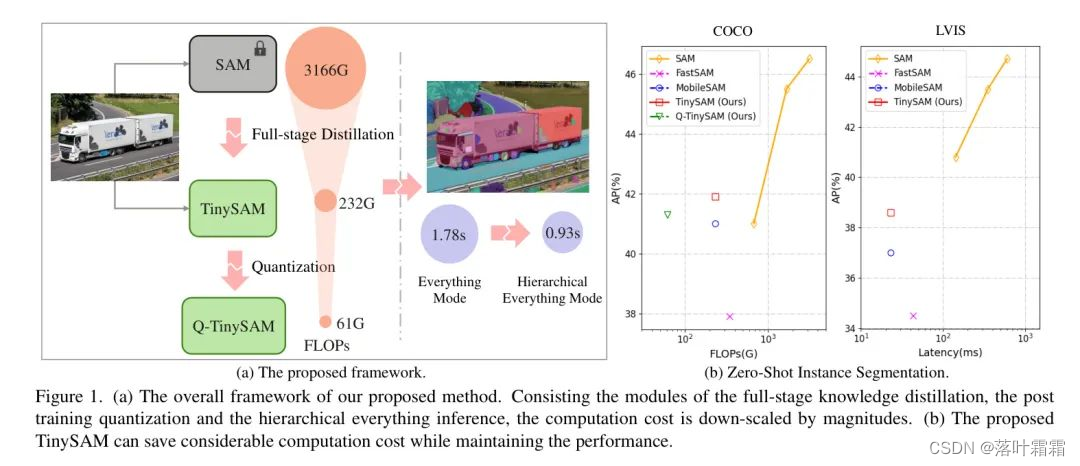
首先,在 3.2 节中,作者引入了一种专门为 SAM 设计的全阶段知识蒸馏。为了进一步激活蒸馏过程,作者使用了在线硬提示采样,以挖掘教师网络到学生网络之间的硬知识。其次,在 3.3 节中描述的后训练量化方法被适应到可提示分割任务,并应用于轻量级学生网络。第三,在 3.4 节中描述的分层 everything 推理模式被设计为分割 anything 任务,可以避免只有微小精度损失的巨额冗余计算,并加快推理时间,实现 的加速。
Full-Stage Knowledge Distillation
SAM 包括三个子网络,即图像编码器、提示编码器和Mask解码器。图像编码器网络基于视觉 Transformer,消耗大量的计算成本。受到 MobileSAM 的启发,作者使用轻量级 TinyViT 替换原始的沉重图像编码器网络。这种简单的替换存在相当大的性能衰减。因此,作者提出了一种全阶段知识蒸馏策略,在多个知识 Level 上指导轻量级图像编码器在学习过程中。
除了预测结果与真实标签之间的传统损失之外,作者在图 2 中引入了多个在不同阶段的蒸馏损失。
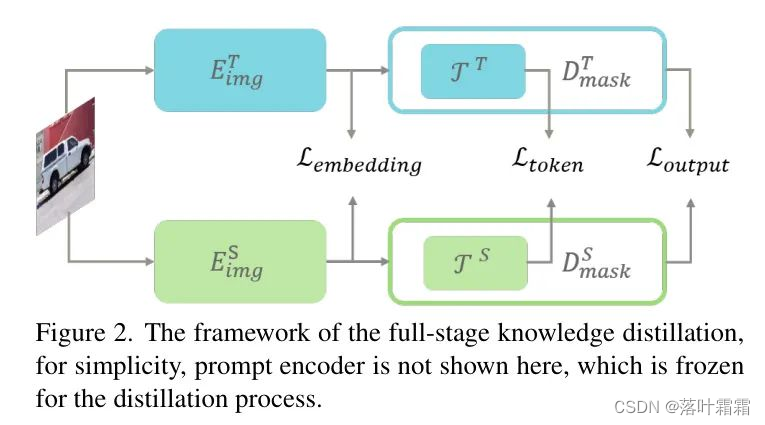
具体而言,作者从教师网络的多个节点中选择来指导学生网络从多个知识 Level 的学习。首先,作者将图像编码器的输出特征,即图像嵌入,作为蒸馏信息。图像嵌入集中了输入图像的信息,这在预测过程中是基本知识。对于一个输入图像 ,图像嵌入的蒸馏损失函数可以表示为:



Hierarchical Segmenting Everything
SAM 提出了一个自动Mask生成器,以网格方式采样点来分割 everything。然而,作者发现密集点网格会导致过细粒度的分割结果,并占用大量的计算资源。一方面,对于完整的目标,过多的采样点可能会导致目标的某些不同部分被错误地分割为独立的Mask。另一方面,由于图像编码器已经大幅缩减, everything 模式推理的时间成本主要在Mask解码器部分。
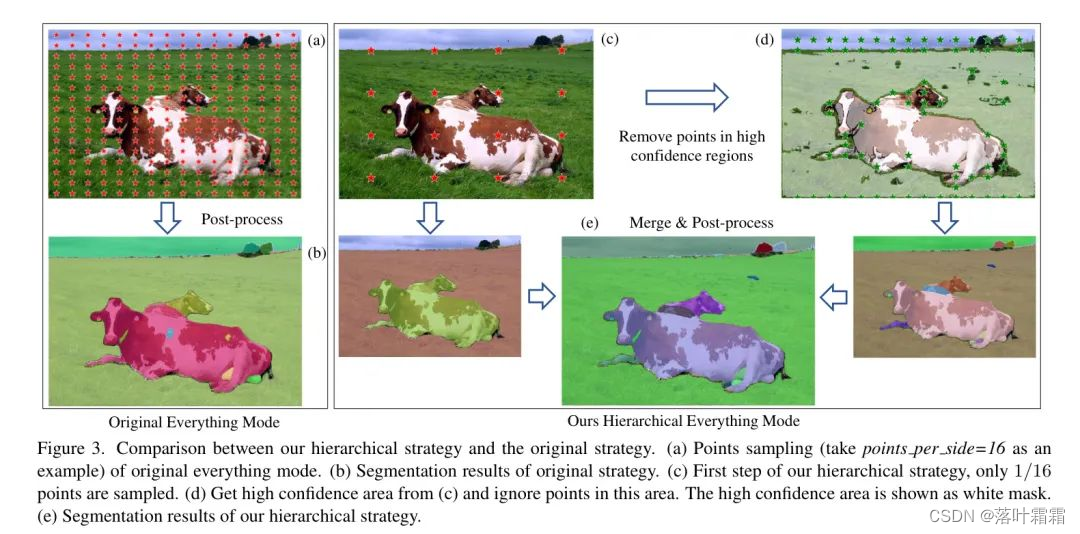
为了减少 everything 模式的时间成本,作者提出了一个分层的Mask生成方法。如图 3 所示,作者的分层策略与原始策略进行了比较。与原始 everything 模式不同,在第一步中,作者只使用了每边 的点,因此总点数为原始设置的 ,如图 3© 所示。然后,作者使用这些提示来推理提示编码器和Mask解码器,并得到结果。
然后作者筛选出置信度超过阈值 的Mask,并将对应的位置Token为可能被视为最终预测的区域。对于这些区域,由于它们被认为是置信度较高的实例的分割结果,因此不需要再生点提示。然后作者以与原始设置相同但忽略上述区域的密度采样点。如图 3(d) 所示,作者的策略忽略了第一头牛的草和身体上的大多数点。与此同时,第二头牛和天空上的点被保留以进一步分割。
具体而言,第二头牛在第一轮中被错误地分割为与第一头牛相同的目标。这种策略可以避免推理时间的成本和目标的过度细分。然后作者利用第二轮采样的点提示来获得Mask预测。最后,将这两轮的结果合并并进行后处理以获得最终Mask。作者的方法忽略了超过 50% 的点,从而带来了巨大的延迟减少。
xperiments
Implementation Details
作者使用 TinyViT-5M 作为轻量级学生图像编码器,并采用 SAM-H 作为教师模型,遵循先前的研究工作。作者只使用 SA-1B 数据集的 1%,即 11000 张图像作为全阶段蒸馏的训练数据。作者采用 Adam 优化器,并在 8 个 epoch 中训练学生网络。对于每个迭代,作者根据在线硬提示采样策略 [3.2] 按 64 个提示采样。
为了加速蒸馏过程,作者在训练时间内预先计算并存储了教师网络的图像嵌入。因此,教师网络的图像编码器在训练时间内不需要重复计算。对于后训练量化,作者量化所有卷积层、线性层、反卷积层和矩阵乘法层。在卷积层和反卷积层中,作者使用通道缩放因子。而对于线性层和矩阵乘法层,作者分别应用层缩放因子和头缩放因子。
对于迭代搜索,作者设置 。作者在 SA-1B 数据集上使用 8 张图像校准量化模型。作者在实例分割和点提示分割等下游任务上进行零样本评估。遵循 SAM 的建议,作者采用多输出模式,并认为最终Mask预测具有最高的 IoU 预测。
Zero-Shot Instance Segmentation
对于零样本实例分割任务,作者严格遵循 SAM 的实验设置,并使用 ViTDet-H 的目标检测结果作为实例分割的边界提示。作者在 COCO 数据集和 LVIS v1 数据集的基准上评估了零样本实例分割任务,并与不同的 SAM 变体以及先前的有效模型(如 FastSAM 和 MobileSAM)进行了比较。
技术细节
提示:这里可以添加技术细节
例如:
- API
- 支持模型类型
小结
提示:这里可以添加总结
例如:
提供先进的推理,复杂的指令,更多的创造力。