
Title: Fast Segment Anything
PDF: https://arxiv.org/pdf/2306.12156v1.pdf
Code: https://github.com/casia-iva-lab/fastsam
导读
SAM已经成为许多高级任务(如图像分割、图像描述和图像编辑)的基础步骤。然而,其巨大的计算开销限制了其在工业场景中的广泛应用。这种计算开销主要来自于处理高分辨率输入的Transformer架构。因此,本文提出了一种具有可比性能的加速替代方法。通过将该任务重新定义为分割生成和提示,作者发现一个常规的CNN检测器结合实例分割分支也可以很好地完成这个任务。具体而言,本文将该任务转换为经过广泛研究的实例分割任务,并仅使用SAM作者发布的SA-1B数据集的1/50进行训练现有的实例分割方法。使用这种方法,作者在50倍更快的运行时间速度下实现了与SAM方法相当的性能。本文提供了充分的实验结果来证明其有效性。
引言
SAM被认为是里程碑式的视觉基础模型,它可以通过各种用户交互提示来引导图像中的任何对象的分割。SAM利用在广泛的SA-1B数据集上训练的Transformer模型,使其能够熟练处理各种场景和对象。SAM开创了一个令人兴奋的新任务,即Segment Anything。由于其通用性和潜力,这个任务具备成为未来广泛视觉任务基石的所有要素。然而,尽管SAM及其后续模型在处理segment anything任务方面展示了令人期待的结果,但其实际应用仍然具有挑战性。显而易见的问题是与SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求。与卷积模型相比,ViT以其庞大的计算资源需求脱颖而出,这对于其实际部署,特别是在实时应用中构成了障碍。这个限制因此阻碍了segment anything任务的进展和潜力。
鉴于工业应用对segment anything模型的高需求,本文设计了一个实时解决方案,称为FastSAM,用于segment anything任务。本文将segment anything任务分解为两个连续的阶段,即全实例分割和提示引导选择。第一阶段依赖于基于卷积神经网络(CNN)的检测器的实现。它生成图像中所有实例的分割掩码。然后在第二阶段,它输出与提示相对应的感兴趣区域。通过利用CNN的计算效率,本文证明了在不太损失性能质量的情况下,可以实现实时的segment anything模型。 本文希望所提出的方法能够促进对segment anything基础任务的工业应用。
::: block-1
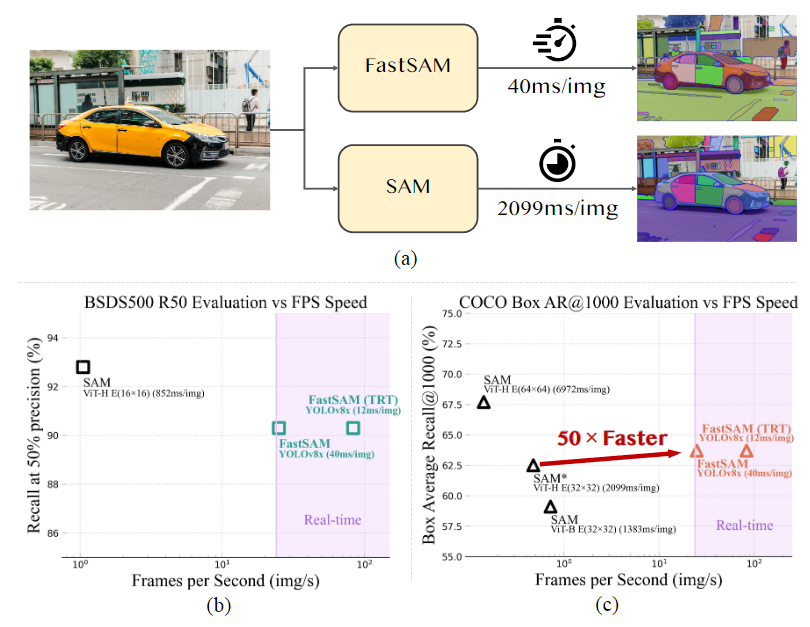
(a) FastSAM和SAM在单个NVIDIA GeForce RTX 3090上的速度比较。(b) 在BSDS500数据集[1, 28]上进行边缘检测的比较。© COCO数据集[25]上对象提议的Box AR@1000评估中FastSAM和SAM的比较。SAM和FastSAM都使用PyTorch进行推理,只有FastSAM(TRT)使用TensorRT进行推理。
:::
本文提出的FastSAM基于YOLACT方法的实例分割分支的目标检测器YOLOv8-seg。此外,还采用了由SAM发布的广泛SA-1B数据集,通过仅在SA-1B数据集的2%(1/50)上直接训练该CNN检测器,它实现了与SAM相当的性能,但大大降低了计算和资源需求,从而实现了实时应用。本文还将其应用于多个下游分割任务,展示了其泛化性能。在MS COCO 上的对象提议任务中,该方法在AR1000上达到了63.7,比使用32×32点提示输入的SAM高1.2点,但在单个NVIDIA RTX 3090上运行速度提高了50倍。
实时的segment anything模型对于工业应用非常有价值。它可以应用于许多场景。所提出的方法不仅为大量视觉任务提供了新的实用解决方案,而且速度非常快,比当前方法快几十倍或几百倍。此外,它还为通用视觉任务的大型模型架构提供了新的视角。对于特定任务来说,特定的模型仍然可以利用优势来获得更好的效率-准确性平衡。
在模型压缩的角度上,本文方法通过引入人工先验结构,展示了显著减少计算量的可行路径。本文贡献可总结如下:
- 引入了一种新颖的实时基于CNN的Segment Anything任务解决方案,显著降低了计算需求同时保持竞争性能。
- 本研究首次提出了将CNN检测器应用于segment anything任务,并提供了在复杂视觉任务中轻量级CNN模型潜力的见解。
- 通过在多个基准测试上对所提出的方法和SAM进行比较评估,揭示了该方法在segment anything领域的优势和劣势。
方法
下图2展示了FastSAM网络架构图。该方法包括两个阶段,即全实例分割和提示引导选择。前一个阶段是基础阶段,第二个阶段本质上是面向任务的后处理。与端到端的Transformer方法不同,整体方法引入了许多与视觉分割任务相匹配的人类先验知识,例如卷积的局部连接和感受野相关的对象分配策略。这使得它针对视觉分割任务进行了定制,并且可以在较少的参数数量下更快地收敛。

::: block-1
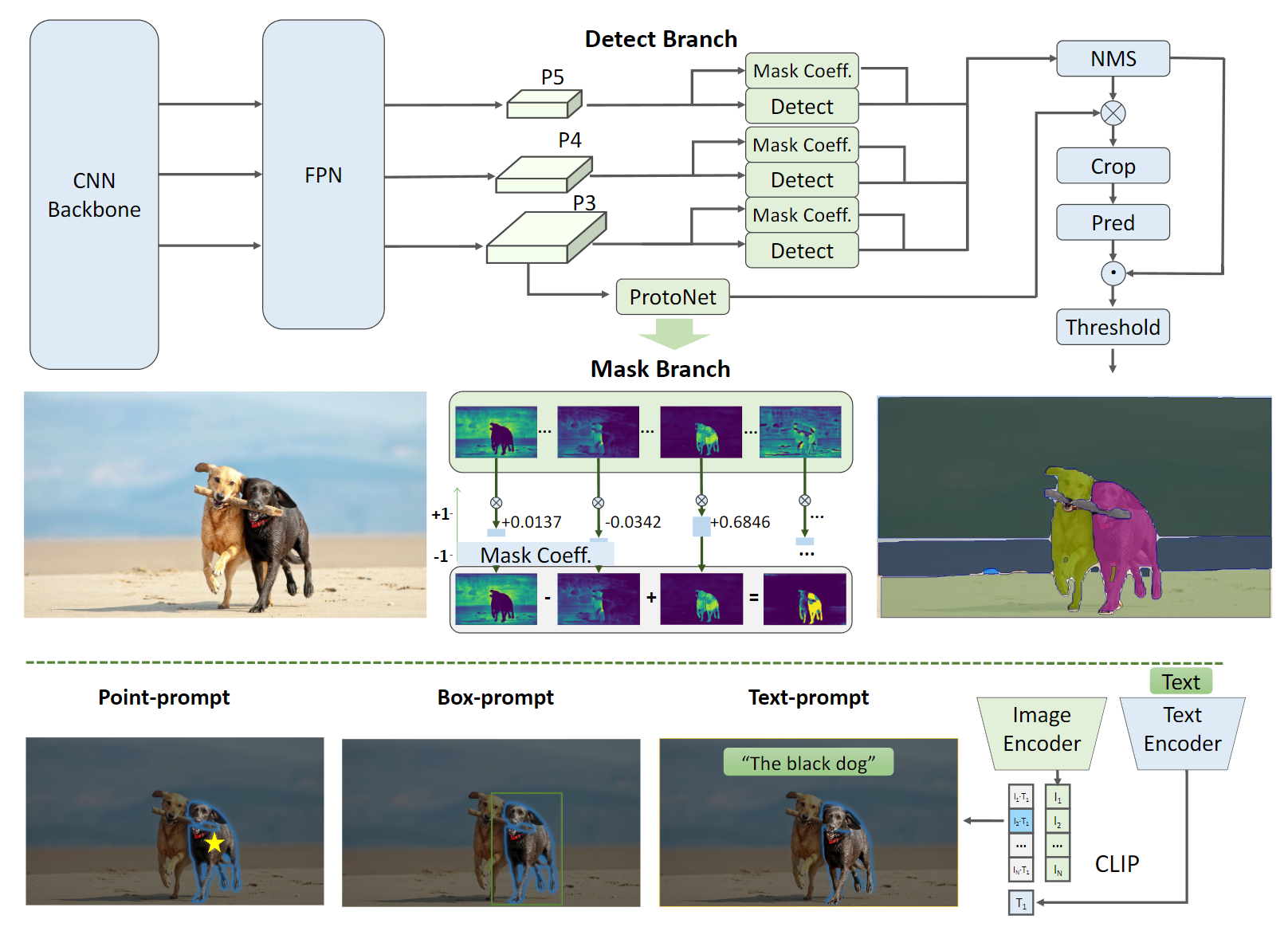
FastSAM包含两个阶段:全实例分割(AIS)和提示引导选择(PGS)。先使用YOLOv8-seg 对图像中的所有对象或区域进行分割。然后使用各种提示来识别感兴趣的特定对象。主要涉及点提示、框提示和文本提示的利用。
:::
实例分割
YOLOv8 的架构是基于其前身YOLOv5 发展而来的,融合了最近算法(如YOLOX 、YOLOv6 和YOLOv7 )的关键设计。YOLOv8的主干网络和特征融合模块(neck module)将YOLOv5的C3模块替换为C2f模块。更新后的头部模块采用解耦结构,将分类和检测分开,并从基于Anchor的方法转向了基于Anchor-Free的方法。
YOLOv8-seg应用了YOLACT的实例分割原理。它通过主干网络和特征金字塔网络(Feature Pyramid Network, FPN)从图像中提取特征,集成了不同尺度的特征。输出包括检测分支和分割分支。检测分支输出目标的类别和边界框,而分割分支输出k个原型(在FastSAM中默认为32个)以及k个掩码系数。分割和检测任务并行计算。分割分支输入高分辨率特征图,保留空间细节,并包含语义信息。该特征图经过卷积层处理,上采样,然后通过另外两个卷积层输出掩码。与检测头部的分类分支类似,掩码系数的范围在-1到1之间。通过将掩码系数与原型相乘并求和,得到实例分割结果。
YOLOv8可以用于各种目标检测任务。而通过实例分割分支,YOLOv8-Seg非常适用于segment anything任务,该任务旨在准确检测和分割图像中的每个对象或区域,而不考虑对象的类别。原型和掩码系数为提示引导提供了很多可扩展性。例如,可以额外训练一个简单的提示编码器和解码器结构,以各种提示和图像特征嵌入作为输入,掩码系数作为输出。在FastSAM中,本文直接使用YOLOv8-seg方法进行全实例分割阶段。
提示引导选择
在使用YOLOv8成功地对图像中的所有对象或区域进行分割后,segment anything 任务的第二阶段是利用各种提示来识别感兴趣的特定对象。这主要涉及到点提示、框提示和文本提示的利用。
点提示
点提示的目标是将所选点与第一阶段获得的各种掩码进行匹配,以确定点所在的掩码。类似于SAM在方法中采用前景/背景点作为提示。在前景点位于多个掩码中的情况下,可以利用背景点来筛选出与当前任务无关的掩码。通过使用一组前景/背景点,我们能够选择感兴趣区域内的多个掩码。这些掩码将被合并为一个单独的掩码,完整标记出感兴趣的对象。此外,还可以利用形态学操作来提高掩码合并的性能。
框提示
框提示涉及将所选框与第一阶段中对应的边界框进行IoU(交并比)匹配。目标是识别与所选框具有最高IoU得分的掩码,从而选择感兴趣的对象。
文本提示
在文本提示的情况下,我们使用CLIP模型提取文本的相应嵌入。然后,确定与每个掩码的固有特征进行匹配的图像嵌入,并使用相似度度量方法进行匹配。选择与文本提示的图像嵌入具有最高相似度得分的掩码。
通过精心实施这些基于提示的选择技术,FastSAM可以可靠地从分割图像中选择特定的感兴趣对象。上述方法为在实时情况下完成segment anything任务提供了高效的方式,从而极大地增强了YOLOv8模型在复杂图像分割任务中的实用性。对于更有效的基于提示的选择技术,将留待未来探索。
实验结果
::: block-1

SAM和FastSAM在单个NVIDIA GeForce RTX 3090 GPU上的运行速度对比。可以看出,FastSAM在所有提示数量上超过了SAM。此外,FastSAM的运行速度与提示数量无关,使其成为"Everything mode"的更好选择。
:::

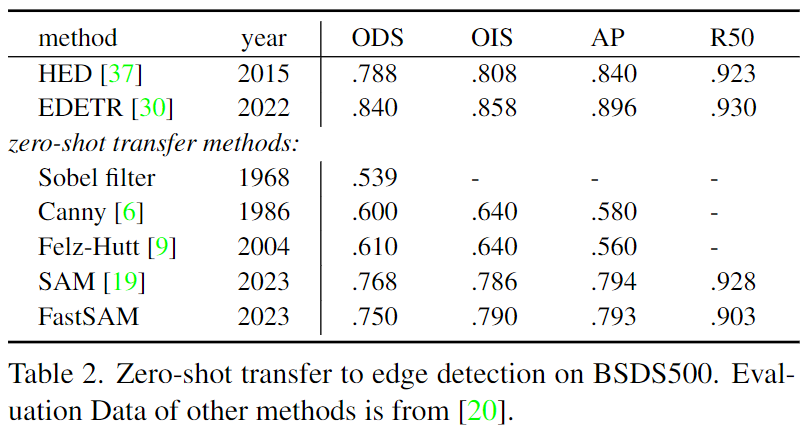
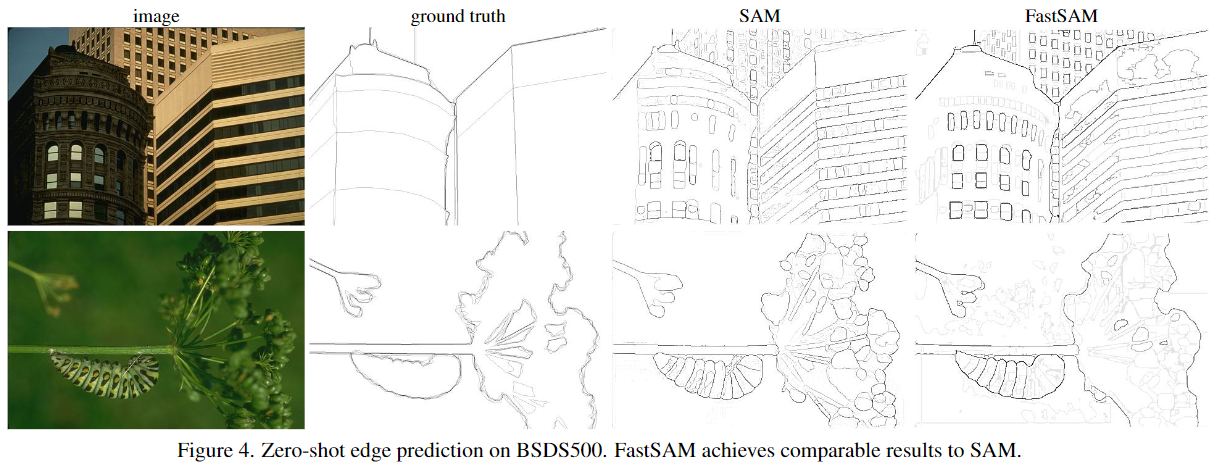
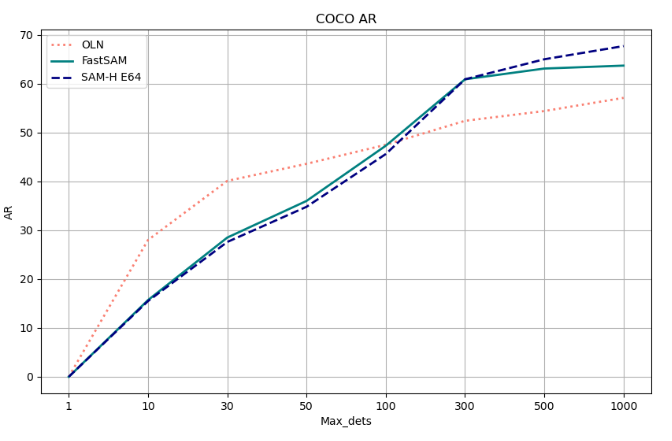
::: block-1

在COCO的所有类别上与无需学习的方法进行比较。此处报告了无需学习的方法、基于深度学习的方法(在VOC上进行训练)以及本文方法与SAM方法在所有泛化上的平均召回率(AR)和AUC对比结果。
:::



::: block-1

在异常检测中的应用,其中SAM-point/box/everything分别表示使用点提示、框提示和全部模式。
:::
::: block-1

在显著性分割中的应用,其中SAM-point/box/everything分别表示使用点提示、框提示和全部模式。
:::
::: block-1

在建筑物提取中的应用,其中SAM-point/box/everything分别表示使用点提示、框提示和全部模式。
:::
::: block-1

相比SAM,FastSAM在大对象的狭窄区域上可以生成更精细的分割掩码。
:::
Limitations
总体而言,FastSAM在性能上与SAM相当,并且比SAM (32×32) 快50倍,比SAM (64×64) 快170倍。其运行速度使其成为工业应用的良好选择,如道路障碍检测、视频实例跟踪和图像处理。在一些图像上,FastSAM甚至能够为大尺寸对象生成更好的掩码。

然而,正如实验中所展示的,FastSAM在生成框上具有明显的优势,但其掩码生成性能低于SAM,如上图11所示。FastSAM具有以下特点:
- 低质量的小尺寸分割掩码具有较高的置信度分数。作者认为这是因为置信度分数被定义为YOLOv8的边界框分数,与掩码质量关系不大。改变网络以预测掩码的IoU或其它质量指标是改进的一种方式。
- 一些微小尺寸对象的掩码倾向于接近正方形。此外,大尺寸对象的掩码可能在边界框的边缘出现一些伪影,这是YOLACT方法的弱点。通过增强掩码原型的能力或重新设计掩码生成器,可以预期解决这个问题。
结论
在本文中,我们重新思考了Segment Anything的任务和模型架构选择,并提出了一种替代方案,其运行速度比SAM-ViT-H (32×32)快50倍。实验证明,FastSAM可以很好地解决多个下游任务。然而,FastSAM还存在一些可以改进的弱点,例如评分机制和实例掩码生成范式。这些问题将留待未来的研究解决。