python机器学习库scikit-learn: Lasso Regression
在数据挖掘和机器学习算法的模型建立之初,为了尽量的减少因缺少重要变量而出现的模型偏差问题,我们通常会尽可能的多的选择自变量。但是在实际建模的过程中,通常又需要寻找 对响应变量具有解释能力的自变量子集,以提高模型的解释能力与预测精度,这个过程称为特征选择。
特征选择主要有两个功能:1.减少特征数量、降维,使模型泛化能力更强,减少过拟合 2.增强对特征和特征值之间的理解
Lasso回归模型,是一个用于估计稀疏参数的线性模型,特别适用于参数数目缩减。
一个简单的例子(这个例子简单介绍了Lasso应该如何使用):
from sklearn.datasets import make_regression
from sklearn.linear_model import Lasso
'''创造数据X Y'''
reg_data, reg_target = make_regression(n_samples=200, n_features=10, n_informative=5, noise=5)
''' 通过交叉检验来获取最优参数'''
from sklearn.linear_model import LassoCV
lassocv = LassoCV()
lassocv.fit(reg_data, reg_target)
alpha = lassocv.alpha_
print('利用Lasso交叉检验计算得出的最优alpha:' + str(alpha))
'''lasso回归'''
lasso = Lasso(1)
lasso.fit(reg_data, reg_target)
'''计算系数不为0的个数'''
import numpy as np
n = np.sum(lasso.coef_ != 0)
print('Lasso回归后系数不为0的个数:' + str(n))
'''输出结果
如果names没有定义,则用X1 X2 X3代替
如果Sort = True,会将系数最大的X放在最前'''
def pretty_print_linear(coefs, names = None, sort = False):
if names == None:
names = ["X%s" % x for x in range(len(coefs))]
lst = zip(coefs, names)
if sort:
lst = sorted(lst, key = lambda x:-np.abs(x[0]))
return " + ".join("%s * %s" % (round(coef, 3), name)
for coef, name in lst)
print('Y = '+ pretty_print_linear(lasso.coef_))
输出结果为:
利用Lasso交叉检验计算得出的最优alpha:0.282356340883
Lasso回归后系数不为0的个数:5
Y = 18.051 * X0 + -0.0 * X1 + -0.0 * X2 + 22.808 * X3 + 78.003 * X4 + 0.342 * X5 + -0.0 * X6 + 0.0 * X7 + 0.0 * X8 + 98.271 * X9
再来一个例子(这个例子证明了Lasso的有效性):
# -*- coding: utf-8 -*-
"""
Lasso 回归应用于稀疏信号
"""
import numpy as np
import matplotlib.pyplot as plt
import time
from sklearn.linear_model import Lasso
from sklearn.metrics import r2_score
# 用于产生稀疏数据
np.random.seed(int(time.time()))
# 生成系数数据,样本为50个,参数为200维
n_samples, n_features = 50, 200
# 基于高斯函数生成数据
X = np.random.randn(n_samples, n_features)
# 每个变量对应的系数
coef = 3 * np.random.randn(n_features)
# 变量的下标
inds = np.arange(n_features)
# 变量下标随机排列
np.random.shuffle(inds)
# 仅仅保留10个变量的系数,其他系数全部设置为0
# 生成稀疏参数
coef[inds[10:]] = 0
# 得到目标值,y
y = np.dot(X, coef)
# 为y添加噪声
y += 0.01 * np.random.normal((n_samples,))
# 将数据分为训练集和测试集
n_samples = X.shape[0]
X_train, y_train = X[:int(n_samples / 2)], y[:int(n_samples / 2)]
X_test, y_test = X[int(n_samples / 2):], y[int(n_samples / 2):]
# Lasso 回归的参数
alpha = 0.1
lasso = Lasso(max_iter=10000, alpha=alpha)
# 基于训练数据,得到的模型的测试结果
# 这里使用的是坐标轴下降算法(coordinate descent)
y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test)
# 这里是R2可决系数(coefficient of determination)
# 回归平方和(RSS)在总变差(TSS)中所占的比重称为可决系数
# 可决系数可以作为综合度量回归模型对样本观测值拟合优度的度量指标。
# 可决系数越大,说明在总变差中由模型作出了解释的部分占的比重越大,模型拟合优度越好。
# 反之可决系数小,说明模型对样本观测值的拟合程度越差。
# R2可决系数最好的效果是1。
r2_score_lasso = r2_score(y_test, y_pred_lasso) # 实际的y,与lasso预测的y
print("测试集上的R2可决系数 : %f" % r2_score_lasso)
lasso.fit(X_train, y_train)
plt.plot(lasso.coef_, label='Lasso coefficients')
plt.plot(coef, '--', label='original coefficients')
plt.legend(loc='best')
plt.title('train sample')
plt.show()
lasso.fit(X_test, y_test)
plt.plot(lasso.coef_, label='Lasso coefficients')
plt.plot(coef, '--', label='original coefficients')
plt.legend(loc='best')
plt.title('test sample')
plt.show()
lasso.fit(X,y)
plt.plot(lasso.coef_, label='Lasso coefficients')
plt.plot(coef, '--', label='original coefficients')
plt.legend(loc='best')
plt.title('all sample')
plt.show()
运行结果:
测试集上的R2可决系数 : 0.619846


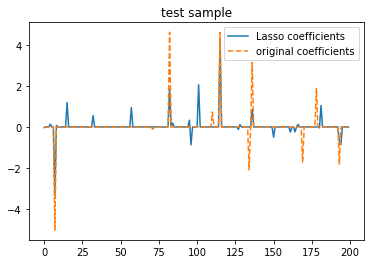
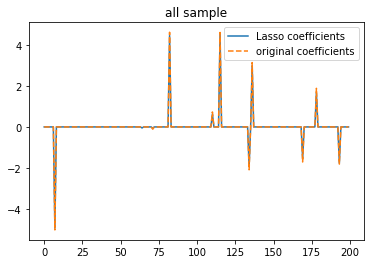
这个例子用于证明Lasso的有效性,给Lasso一个子集,它回归出来的系数与原系数coef很接近。当给Lasso一个全集时,即使在开头对y加入了噪音,它的回归结果与原coef也是几乎完全一致。
再来一个例子(这个例子证明了Lasso的特征选择,可以在不改变模型测试集准去率的情况下,减小特征维度):
# -*- coding: utf-8 -*-
"""
Created on Wed Sep 27 15:38:48 2017
@author: Jackie
"""
import numpy as np
import time
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris #导入某个数据集
from sklearn.feature_selection import SelectFromModel
from sklearn.metrics import r2_score
'''导入iris数据集
这个数据集一共有150个样本,特征维数为4维'''
np.random.seed(int(time.time()))
iris = load_iris()
X, y = iris.data, iris.target
print('X矩阵的尺寸:' + str(X.shape[0]) + '行,' + str(X.shape[1]) + '列')
#print(X)
'''将原始样本的数据打乱,
此时inds = [148 8 117 ..., 104 89 127]'''
inds = np.arange(X.shape[0])
np.random.shuffle(inds)
'''提取训练数据集和测试数据集
inds[:100] 是 [148 8 117 ..., 104 89 127]的前100个'''
X_train = X[inds[:100]] # 随机挑100行数据,每行4维
y_train = y[inds[:100]]
X_test = X[inds[100:]]
y_test = y[inds[100:]]
'''数据有4维'''
print('原始特征的维度:', X_train.shape[1])
'''线性核的支持向量机分类器
Linear kernel Support Vector Machine classifier
支持向量机的参数C为0.01,使用l1正则化项'''
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X_train, y_train)
print('原始特征,在测试集上的准确率:', lsvc.score(X_test, y_test))
print('原始特征,在测试集上的R2可决系数:', r2_score(lsvc.predict(X_test), y_test))
'''基于l1正则化的特征选择'''
model = SelectFromModel(lsvc, prefit=True)
'''将原始特征,转换为新的特征'''
X_train_new = model.transform(X_train)
X_test_new = model.transform(X_test)
#print(X_train_new)
#print(X_train)
print('新特征的维度:', X_train_new.shape[1])
'''用新的特征重新训练模型'''
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X_train_new, y_train)
print('新特征,在测试集上的准确率:', lsvc.score(X_test_new, y_test))
print('新始特征,在测试集上的R2可决系数:', r2_score(lsvc.predict(X_test_new), y_test))X矩阵的尺寸:150行,4列
原始特征的维度: 4
原始特征,在测试集上的准确率: 0.62
原始特征,在测试集上的R2可决系数: 0.446386946387
新特征的维度: 3
新特征,在测试集上的准确率: 0.62
新始特征,在测试集上的R2可决系数: 0.446386946387
由运行结果可以看出,基于Lasso的特征选择,在不改变模型测试集准去率的情况下,减小了特征的维度。