单发多框检测(SSD)(Liu et al., 2016)。 该模型简单、快速且被广泛使用。尽管这只是其中一种目标检测模型,但本节中的一些设计原则和实现细节也适用于其他模型。
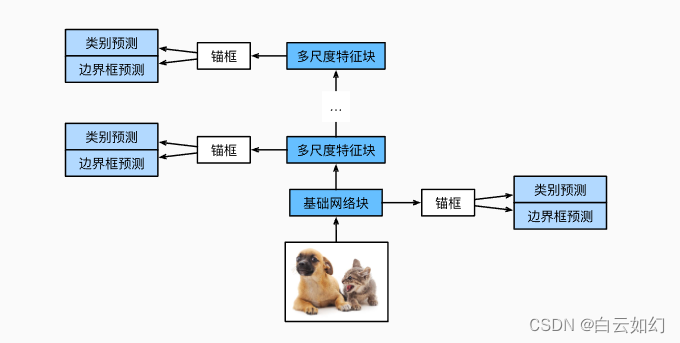
下图描述了单发多框检测模型的设计。 此模型主要由基础网络组成,其后是几个多尺度特征块。 基本网络用于从输入图像中提取特征,因此它可以使用深度卷积神经网络。 单发多框检测论文中选用了在分类层之前截断的VGG(Liu et al., 2016),现在也常用ResNet替代。 我们可以设计基础网络,使它输出的高和宽较大。 这样一来,基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标。 接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使特征图中每个单元在输入图像上的感受野变得更广阔。
通过深度神经网络分层表示图像的多尺度目标检测的设计。 由于接近下图顶部的多尺度特征图较小,但具有较大的感受野,它们适合检测较少但较大的物体。 简而言之,通过多尺度特征块,单发多框检测生成不同大小的锚框,并通过预测边界框的类别和偏移量来检测大小不同的目标,因此这是一个多尺度目标检测模型。