一、小目标检测研究思路
1.1 数据增强
数据增强是一种提升小目标检测性能的最简单和有效的方法,通过不同的数据增强策略可以扩充训练数据集的规模,丰富数据集的多样性,从而增强检测模型的鲁棒性和泛化能力。在相对早期的研究中,Yaeger等[20]通过使用扭曲变形、旋转和缩放等数据增强方法显著提升了手写体识别的精度。之后,数据增强中又衍生出了弹性变形[21]、随机裁剪[22]和平移[23]等策略。目前,这些数据增强策略已被广泛应用于目标检测中。
近些年来,基于深度学习的卷积神经网络在处理计算机视觉任务中获得了巨大的成功。深度学习的成功很大程度上归功于数据集的规模和质量,大规模和高质量的数据能够大幅度提升模型的泛化能力。数据增强策略在目标检测领域有着广泛应用,例如Fast R‑CNN[24]、Cascade R‑CNN[25]中使用的水平翻转,YOLO[26]、YOLO9000[27]中使用的调整图像曝光和饱和度,还有常被使用的CutOut[28]、MixUp[29]、CutMix[30]等方法。最近,更是有诸如马赛克增强(YOLOv4[31])、保持增强[32]等创新策略提出,但是这些数据增强策略主要是针对常规目标检测。
聚焦到小目标检测领域,小目标面临着分辨率低、可提取特征少、样本数量匮乏及分布不均匀等诸多挑战,数据增强的重要性愈发显著。近些年来,出现了一些适用于小目标的数据增强方法(表 1)。Yu等[17]在对数据的处理中,提出了尺度匹配策略,根据不同目标尺寸进行裁剪,缩小不同大小目标之间的差距,从而避免常规缩放操作中小目标信息易丢失的情形。Kisantal等[33]针对小目标覆盖的面积小、出现位置缺乏多样性、检测框与真值框之间的交并比远小于期望的阈值等问题,提出了一种复制增强的方法,通过在图像中多次复制粘贴小目标的方式来增加小目标的训练样本数,从而提升了小目标的检测性能。在Kisantal等的基础上,Chen等[34]在RRNet中提出了一种自适应重采样策略进行数据增强,这种策略基于预训练的语义分割网络对目标图像进行考虑上下文信息的复制,以解决简单复制过程中可能出现的背景不匹配和尺度不匹配问题,从而达到较好的数据增强效果。Chen等[35]则从小目标数量占比小、自身包含信息少等问题出发,在训练过程中对图像进行缩放与拼接,将数据集中的大尺寸目标转换为中等尺寸目标,中等尺寸目标转换为小尺寸目标,并在提高中/小尺寸目标的数量与质量的同时也兼顾考虑了计算成本。在针对小目标的特性设计对应的数据增强策略之外,Zoph等[36]超越了目标特性限制,提出了一种通过自适应学习方法例如强化学习选择最佳的数据增强策略,在小目标检测上获得了一定的性能提升。


数据增强这一策略虽然在一定程度上解决了小目标信息量少、缺乏外貌特征和纹理等问题,有效提高了网络的泛化能力,在最终检测性能上获得了较好的效果,但同时带来了计算成本的增加。而且在实际应用中,往往需要针对目标特性做出优化,设计不当的数据增强策略可能会引入新的噪声,损害特征提取的性能,这也给算法的设计带来了挑战。
1.2 多尺度学习
小目标与常规目标相比可利用的像素较少,难以提取到较好的特征,而且随着网络层数的增加,小目标的特征信息与位置信息也逐渐丢失,难以被网络检测。这些特性导致小目标同时需要深层语义信息与浅层表征信息,而多尺度学习将这两种相结合,是一种提升小目标检测性能的有效策略。
早期的多尺度检测有两个思路。一种是使用不同大小的卷积核通过不同的感受野大小来获取不同尺度的信息,但这种方法计算成本很高,而且感受野的尺度范围有限,Simonyan和Zisserman[13]提出使用多个小卷积核代替大卷积核具备巨大优势后,使用不同大小卷积核的方法逐渐被弃用。之后,Yu等[37]提出的空洞卷积和Dai等[38]提出的可变卷积又为这种通过不同感受野大小获取不同尺度信息的方法开拓了新的思路。另一种来自于图像处理领域的思路——图像金字塔[39],通过输入不同尺度的图像,对不同尺度大小的目标进行检测,这种方法在早期的目标检测中有所应用[40‑41](见图2(a))。但是,基于图像金字塔训练卷积神经网络模型对计算机算力和内存都有极高的要求。近些年来,图像金字塔在实际研究应用中较少被使用,仅有文献[42‑43]等方法针对数据集目标尺度差异过大等问题而使用。
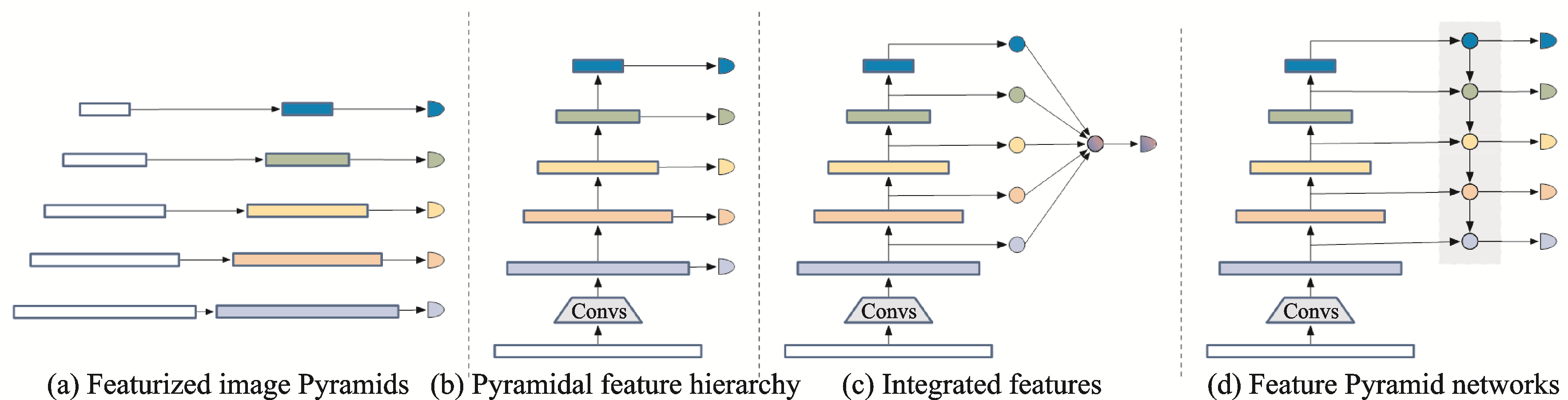
图2 多尺度学习的4种方式
目标检测中的经典网络如Fast R‑CNN[24]、Faster R‑CNN[44]、SPPNet[45]和R‑FCN[46]等大多只是利用了深度神经网络的最后层来进行预测。然而,由于空间和细节特征信息的丢失,难以在深层特征图中检测小目标。在深度神经网络中,浅层的感受野更小,语义信息弱,上下文信息缺乏,但是可以获得更多空间和细节特征信息。从这一思路出发,Liu等[47]提出一种多尺度目标检测算法SSD(Single shot multibox detector),利用较浅层的特征图来检测较小的目标,而利用较深层的特征图来检测较大的目标,如图2(b)所示。Cai等[48]针对小目标信息少,难以匹配常规网络的问题,提出统一多尺度深度卷积神经网络,通过使用反卷积层来提高特征图的分辨率,在减少内存和计算成本的同时显著提升了小目标的检测性能。
针对小目标易受环境干扰问题,Bell等[49]为提出了ION(Inside‑outside network)目标检测方法,通过从不同尺度特征图中裁剪出同一感兴趣区域的特征,然后综合这些多尺特征来预测,以达到提升检测性能的目的。与ION的思想相似,Kong等[50]提出了一种有效的多尺度融合网络,即HyperNet,通过综合浅层的高分辨率特征和深层的语义特征以及中间层特征的信息显著提高了召回率,进而提高了小目标检测的性能(见图2(c))。这些方法能有效利用不同尺度的信息,是提升小目标特征表达的一种有效手段。但是,不同尺度之间存在大量重复计算,对于内存和计算成本的开销较大。
为节省计算资源并获得更好的特征融合效果,Lin等[51]结合单一特征映射、金字塔特征层次和综合特征的优点,提出了特征金字塔FPN(Feature Pyramid network)。FPN是目前最流行的多尺度网络,它引入了一种自底向上、自顶向下的网络结构,通过将相邻层的特征融合以达到特征增强的目的(见图2(d))。在FPN的基础上,Liang等[52]提出了一种深度特征金字塔网络,使用具有横向连接的特征金字塔结构加强小目标的语义特征,并辅以特别设计的锚框和损失函数训练网络。为了提高小目标的检测速度,Cao等[53]提出一种多层次特征融合算法,即特征融合SSD,在SSD的基础上引入上下文信息,较好地平衡了小目标检测的速度与精度。但是基于SSD的特征金字塔方法需要从网络的不同层中抽取不同尺度的特征图进行预测,难以充分融合不同尺度的特征。针对这一问题,Li和Zhou[54]提出一种特征融合单次多箱探测器,使用一个轻量级的特征融合模块,联系并融合各层特征到一个较大的尺度,然后在得到的特征图上构造特征金字塔用于检测,在牺牲较少速度的情形下提高了对小目标的检测性能。针对机场视频监控中的小目标识别准确率较低的问题,韩松臣等[55]提出了一种结合多尺度特征融合与在线难例挖掘的机场路面小目标检测方法,该方法采用ResNet‑101作为特征提取网络,并在该网络基础上建立了一个带有上采样的“自顶向下”的特征融合模块,以生成语义信息更加丰富的高分辨率特征图。
最近,多尺度特征融合这一方法又有了新的拓展,如Nayan等[56]针对小目标经过多层网络特征信息易丢失这一问题,提出了一种新的实时检测算法,该算法使用上采样和跳跃连接在训练过程中提取不同网络深度的多尺度特征,显著提高了小目标检测的检测精度与速度。Liu等[57]为了降低高分辨率图像的计算成本,提出了一种高分辨率检测网络,通过使用浅层网络处理高分辨率图像和深层网络处理低分辨率图像,在保留小目标尽可能多的位置信息同时提取了更多的语义信息,在降低计算成本的情形下提升了小目标的检测性能。Deng等[58]发现虽然多尺度融合可以有效提升小目标检测性能,但是不同尺度的特征耦合仍然会影响性能,于是提出了一种扩展特征金字塔网络,使用额外的高分辨率金字塔级专门用于小目标检测。
总体来说,多尺度特征融合同时考虑了浅层的表征信息和深层的语义信息,有利于小目标的特征提取,能够有效地提升小目标检测性能。然而,现有多尺度学习方法在提高检测性能的同时也增加了额外的计算量,并且在特征融合过程中难以避免干扰噪声的影响,这些问题导致了基于多尺度学习的小目标检测性能难以得到进一步提升。
1.3 上下文学习
在真实世界中,“目标与场景”和“目标与目标”之间通常存在一种共存关系,通过利用这种关系将有助于提升小目标的检测性能。在深度学习之前,已有研究[59]证明通过对上下文进行适当的建模可以提升目标检测性能,尤其是对于小目标这种外观特征不明显的目标。随着深度神经网络的广泛应用,一些研究也试图将目标周围的上下文集成到深度神经网络中,并取得了一定的成效。以下将从基于隐式上下文特征学习和基于显式上下文推理的目标检测两个方面对国内外研究现状及发展动态进行简要综述。
(1)基于隐式上下文特征学习的目标检测。隐式上下文特征是指目标区域周围的背景特征或者全局的场景特征。事实上,卷积神经网络中的卷积操作在一定程度上已经考虑了目标区域周围的隐式上下文特征。为了利用目标周围的上下文特征,Li等[60]提出一种基于多尺度上下文特征增强的目标检测方法,该方法首先在图像中生成一系列的目标候选区域,然后在目标周围生成不同尺度的上下文窗口,最后利用这些窗口中的特征来增强目标的特征表示(见图3(a))。随后,Zeng等[61]提出一种门控双向卷积神经网络,该网络同样在目标候选区域的基础上生成包含不同尺度上下文的支撑区域,不同之处在于该网络让不同尺度和分辨率的信息在生成的支撑区域之间相互传递,从而综合学习到最优的特征。为了更好地检测复杂环境下的微小人脸,Tang等[62]提出一种基于上下文的单阶段人脸检测方法,该方法设计了一种新的上下文锚框,在提取人脸特征的同时考虑了其周围的上下文信息,例如头部信息和身体信息。郑晨斌等[63]提出一种强化上下文模型网络,该网络利用双空洞卷积结构来节省参数量的同时,通过扩大有效感受野来强化浅层上下文信息,并在较少破坏原始目标检测网络的基础上灵活作用于网络中浅预测层。然而,这些方法大多依赖于上下文窗口的设计或受限于感受野的大小,可能会导致重要上下文信息的丢失。
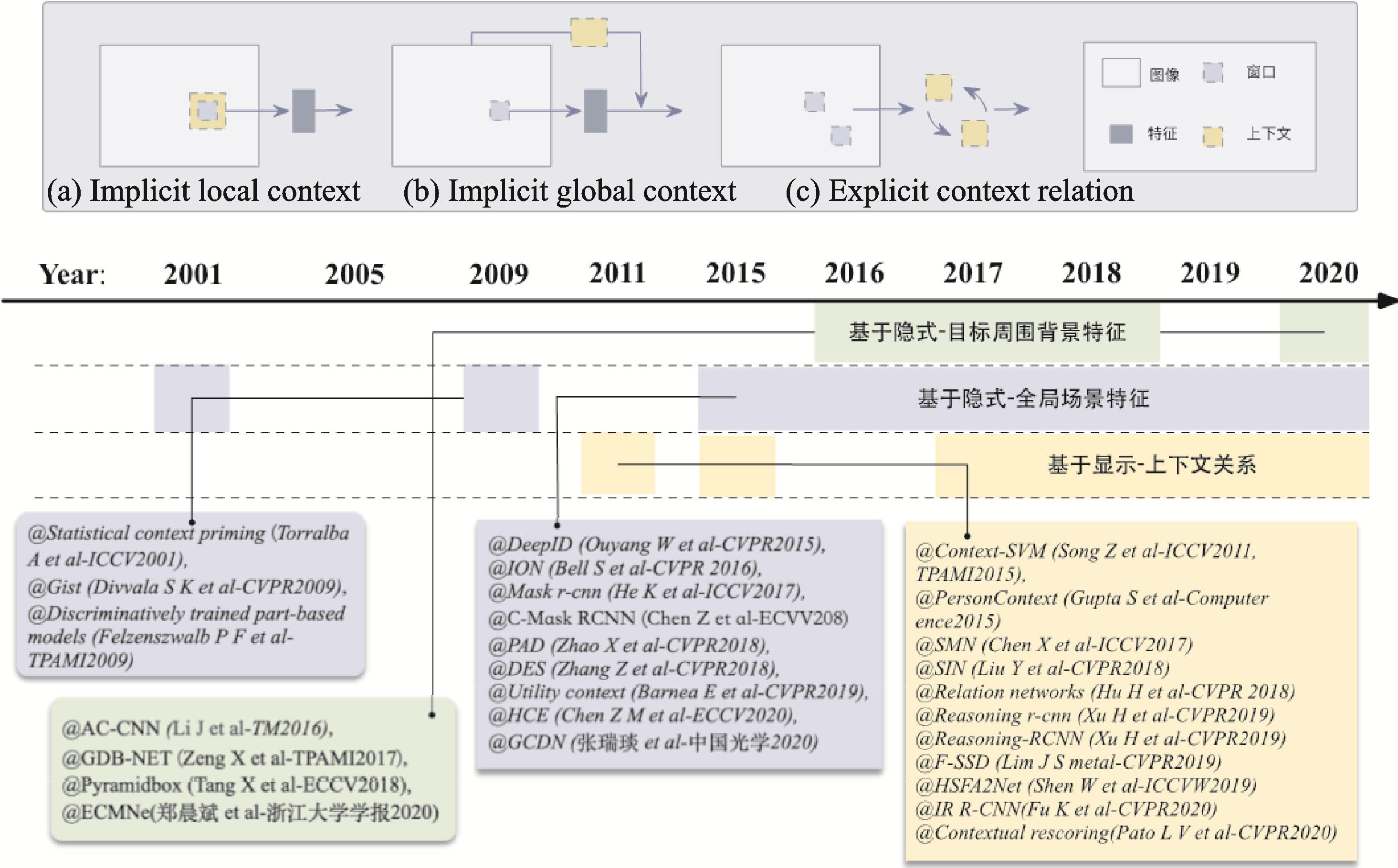
图3 上下文在目标检测中的探索历程
为了更加充分地利用上下文信息,一些方法尝试将全局的上下文信息融入到目标检测模型中(见 图3(b))。对于早期的目标检测算法,一种常用的集成全局上下文方法是通过构成场景元素的统计汇总,例如Gist[64]。Torralba等[65]提出通过计算全局场景的低级特征和目标的特征描述符的统计相关性来对视觉上下文建模。随后,Felzenszwalb等[66]提出一种基于混合多尺度可变形部件模型的目标检测方法。该方法通过引入上下文来对检测结果进行二次评分,从而进一步提升检测结果的可靠性。对于目前的基于深度学习的目标检测算法,主要通过较大的感受野、卷积特征的全局池化或把全局上下文看作一种序列信息3种方式来感知全局上下文。Bell等[49]提出基于循环神经网络的上下文传递方法,该方法利用循环神经网络从4个方向对整个图像中的上下文信息进行编码,并将得到的4个特征图进行串联,从而实现对全局上下文的感知。然而,该方法使模型变得复杂,并且模型的训练严重依赖于初始化参数的设置。Ouyang等[67]通过学习图像的分类得分,并将该得分作为补充的上下文特征来提升目标检测性能。为了提升候选区域的特征表示,Chen等[68]提出一种上下文微调网络,该网络首先通过计算相似度找到与目标区域相关的上下文区域,然后利用这些上下文区域的特征来增强目标区域特征。随后,Barnea等[69]将上下文的利用视为一个优化问题,讨论了上下文或其他类型的附加信息可以将检测分数提高到什么程度,并表明简单的共现性关系是最有效的上下文信息。此外,Chen等[70]提出一种层次上下文嵌入框架,该框架可以作为一个即插即用的组件,通过挖掘上下文线索来增强候选区域的特征表达,从而提升最终的检测性能。最近,张瑞琰等[71]提出了面向光学遥感目标的全局上下文检测模型,该模型通过全局上下文特征与目标中心点局部特征相结合的方式生成高分辨率热点图,并利用全局特征实现目标的预分类。此外,一些方法通过语义分割来利用全局上下文信息。He等[72]提出一种统一的实例分割框架,利用像素级的监督来优化检测器,并通过多任务的方式联合优化目标检测和实例分割模型。尽管通过语义分割可以显著提高检测性能,但是像素级的标注是非常昂贵的。鉴于此,Zhao等[73]提出一种生成伪分割标签的方法,通过利用伪分割标签来于优化检测器,并取得了不错的效果。进一步地,Zhang等[74]提出一种无监督的分割方法,在无像素级的标注下通过联合优化目标检测和分割来增强用于目标检测的特征图。目前,基于全局上下文的方法在目标检测上已经取得了较大的进展,但如何从全局场景中找到有利于提升小目标检测性能的上下文信息仍然是当前的研究难点。
(2)基于显式上下文推理的目标检测。显示上下文推理是指利用场景中明确的上下文信息来辅助推断目标的位置或类别,例如利用场景中天空区域与目标的上下文关系来推断目标的类别。上下文关系通常指场景中目标与场景或者目标与目标之间的约束和依赖关系(见图3(c))。为了利用上下文关系,Chen等[75]提出一种自适应上下文建模和迭代提升的方法,通过将一个任务的输出作为另一个任务的上下文来提升目标分类和检测性能。此后,Gupta等[76]提出一种基于空间上下文的目标检测方法。该方法能够准确地捕捉到上下文和感兴趣目标之间的空间关系,并且有效地利用了上下文区域的外观特征。进一步地,Liu等[77]提出一种结构推理网络,通过充分考虑场景上下文和目标之间的关系来提升目标的检测性能。为了利用先验知识,Xu等[78]在Faster R‑CNN[44]的基础上提出了一种Reasoning‑RCNN,通过构建知识图谱来编码上下文关系,并利用先验的上下文关系来影响目标检测。Chen等[79]提出了一种空间记忆网络,空间记忆实质上是将目标实例重新组合成一个伪图像表示,并将伪图像表示输入到卷积神经网络中进行目标关系推理,从而形成一种顺序推理体系结构。在注意力机制的基础上,Hu等[80]提出一种轻量级目标关系网络,通过引入不同物体之间的外观和几何结构关系来做约束,实现物体之间的关系建模。该网络无需额外的监督,并且易于嵌入到现有的网络中,可以有效地过滤冗余框,从而提升目标的检测性能。
近年来,基于上下文学习的方法得到了进一步发展。Lim等[81]提出一种利用上下文连接多尺度特征的方法,该方法中使用网络不同深度层级中的附加特征作为上下文,辅以注意力机制聚焦于图像中的目标,充分利用了目标的上下文信息,进而提升了实际场景中的小目标检测精度。针对室内小尺度人群检测面临的目标特征与背景特征重叠且边界难以区分的问题,Shen等[82]提出了一种室内人群检测网络框架,使用一种特征聚合模块(Feature aggregation module, FAM)通过融合和分解的操作来聚合上下文特征信息,为小尺度人群检测提供更多细节信息,进而显著提升了对于室内小尺度人群的检测性能。Fu等[83]提出了一种新颖的上下文推理方法,该方法对目标之间的固有语义和空间布局关系进行建模和推断,在提取小目标语义特征的同时尽可能保留其空间信息,有效解决了小目标的误检与漏检问题。为了提升目标的分类结果,Pato等[84]提出一种基于上下文的检测结果重打分方法,该方法通过循环神经网络和自注意力机制来传递候选区域之间的信息并生成上下文表示,然后利用得到的上下文来对检测结果进行二次评估。
基于上下文学习的方法充分利用了图像中与目标相关的信息,能够有效提升小目标检测的性能。但是,已有方法没有考虑到场景中的上下文信息可能匮乏的问题,同时没有针对性地利用场景中易于检测的结果来辅助小目标的检测。鉴于此,未来的研究方向可以从以下两个角度出发考虑:(1)构建基于类别语义池的上下文记忆模型,通过利用历史记忆的上下文来缓解当前图像中上下文信息匮乏的问题;(2)基于图推理的小目标检测,通过图模型和目标检测模型的结合来针对性地提升小目标的检测性能。
1.4 生成对抗学习
生成对抗学习的方法旨在通过将低分辨率小目标的特征映射成与高分辨率目标等价的特征,从而达到与尺寸较大目标同等的检测性能。前文所提到的数据增强、特征融合和上下文学习等方法虽然可以有效地提升小目标检测性能,但是这些方法带来的性能增益往往受限于计算成本。针对小目标分辨率低问题,Haris等[85]提出一种端到端的联合训练超分辨率和检测模型的方法,该方法一定程度上提升了低分辨率目标的检测性能。但是,这种方法对于训练数据集要求较高,并且对小目标检测性能的提升不足。
目前,一种有效的方法是通过结合生成对抗网络(Generative adversarial network, GAN)[86]来提高小目标的分辨率,缩小小目标与大/中尺度目标之间的特征差异,增强小目标的特征表达,进而提高小目标检测的性能。在Radford等[87]提出了DCGAN(Deep convolutional GAN)后,计算视觉的诸多任务开始利用生成对抗模型来解决具体任务中面临的问题。针对训练样本不足的问题,Sixt等[88]提出了RenderGAN,该网络通过对抗学习来生成更多的图像,从而达到数据增强的目的。为了增强检测模型的鲁棒性,Wang等[89]通过自动生成包含遮挡和变形特征的样本,以此提高对困难目标的检测性能。随后,Li等[90]提出了一种专门针对小目标检测的感知GAN方法,该方法通过生成器和鉴别器相互对抗的方式来学习小目标的高分辨率特征表示。在感知GAN中,生成器将小目标表征转换为与真实大目标足够相似的超分辨表征。同时,判别器与生成器对抗以识别生成的表征,并对生成器施加条件要求。该方法通过生成器和鉴别器相互对抗的方式来学习小目标的高分辨率特征表示。这项工作将小目标的表征提升为“超分辨”表征,实现了与大目标相似的特性,获得了更好的小目标检测性能。
近年来,基于GAN对小目标进行超分辨率重建的研究有所发展,Bai等[91]提出了一种针对小目标的多任务生成对抗网络(Multi‑task generative adversarial network, MTGAN)。在MTGAN中,生成器是一个超分辨率网络,可以将小模糊图像上采样到精细图像中,并恢复详细信息以便更准确地检测。判别器是多任务网络,区分真实图像与超分辨率图像并输出类别得分和边界框回归偏移量。此外,为了使生成器恢复更多细节以便于检测,判别器中的分类和回归损失在训练期间反向传播到生成器中。MTGAN由于能够从模糊的小目标中恢复清晰的超分辨目标,因此大幅度提升了小目标的检测性能。进一步地,针对现有的用于小目标检测的超分辨率模型存在缺乏直接的监督问题,Noh等[92]提出一种新的特征级别的超分辨率方法,该方法通过空洞卷积的方式使生成的高分辨率目标特征与特征提取器生成的低分辨率特征保持相同的感受野大小,从而避免了因感受野不匹配而生成错误超分特征的问题。此外,Deng等[58]设计了一种扩展特征金字塔网络,该网络通过设计的特征纹理模块生成超高分辨率的金字塔层,从而丰富了小目标的特征信息。
基于生成对抗模型的目标检测算法通过增强小目标的特征信息,可以显著提升检测性能。同时,利用生成对抗模型来超分小目标这一步骤无需任何特别的结构设计,能够轻易地将已有的生成对抗模型和检测模型相结合。但是,目前依旧面临两个无法避免的问题:(1)生成对抗网络难以训练,不易在生成器和鉴别器之间取得好的平衡;(2)生成器在训练过程中产生样本的多样性有限,训练到一定程度后对于性能的提升有限。
1.5 无锚机制
锚框机制在目标检测中扮演着重要的角色。许多先进的目标检测方法都是基于锚框机制而设计的,但是锚框这一设计对于小目标的检测极不友好。现有的锚框设计难以获得平衡小目标召回率与计算成本之间的矛盾,而且这种方式导致了小目标的正样本与大目标的正样本极度不均衡,使得模型更加关注于大目标的检测性能,从而忽视了小目标的检测。极端情况下,设计的锚框如果远远大于小目标,那么小目标将会出现无正样本的情况。小目标正样本的缺失,将使得算法只能学习到适用于较大目标的检测模型。此外,锚框的使用引入了大量的超参,比如锚框的数量、宽高比和大小等,使得网络难以训练,不易提升小目标的检测性能。近些年无锚机制的方法成为了研究热点,并在小目标检测上取得了较好效果。
一种摆脱锚框机制的思路是将目标检测任务转换为关键点的估计,即基于关键点的目标检测方法。基于关键点的目标检测方法主要包含两个大类:基于角点的检测和基于中心的检测。基于角点的检测器通过对从卷积特征图中学习到的角点分组来预测目标边界框。DeNet[93]将目标检测定义为估计目标4个角点的概率分布,包括左上角、右上角、左下角和右下角(见图4(a))。首先利用标注数据来训练卷积神经网络,然后利用该网络来预测角点分布。之后,利用角点分布和朴素贝叶斯分类器来确定每个角点对应的候选区域是否包含目标。在DeNet之后,Wang等[94]提出了一种新的使用角点和中心点之间的连接来表示目标的方法,命名为PLN(Point linking network)。PLN首先回归与DeNet相似的4个角点和目标的中心点,同时通过全卷积网络预测关键点两两之间是否相连,然后将角点及其相连的中心点组合起来生成目标边界框。PLN对于稠密目标和具有极端宽高比率目标表现良好。但是,当角点周围没有目标像素时,PLN由于感受野的限制将很难检测到角点。继PLN之后,Law等[95]提出了一种新的基于角点的检测算法,命名为CornerNet。CornerNet将目标检测问题转换为角点检测问题,首先预测所有目标的左上和右下的角点,然后将这些角点进行两两匹配,最后利用配对的角点生成目标的边界框。CornetNet的改进版本——CornerNet‑Lite[96],从减少处理的像素数量和减少在每个像素上进行的计算数量两个角度出发进行改进,有效解决了目标检测中的两个关键用例:在不牺牲精度的情况下提高效率以及实时效率的准确性。与基于锚框的检测器相比,CornerNet系列具有更简洁的检测框架,在提高检测效率的同时获得了更高的检测精度。但是,该系列仍然会因为错误的角点匹配预测出大量不正确的目标边界框。
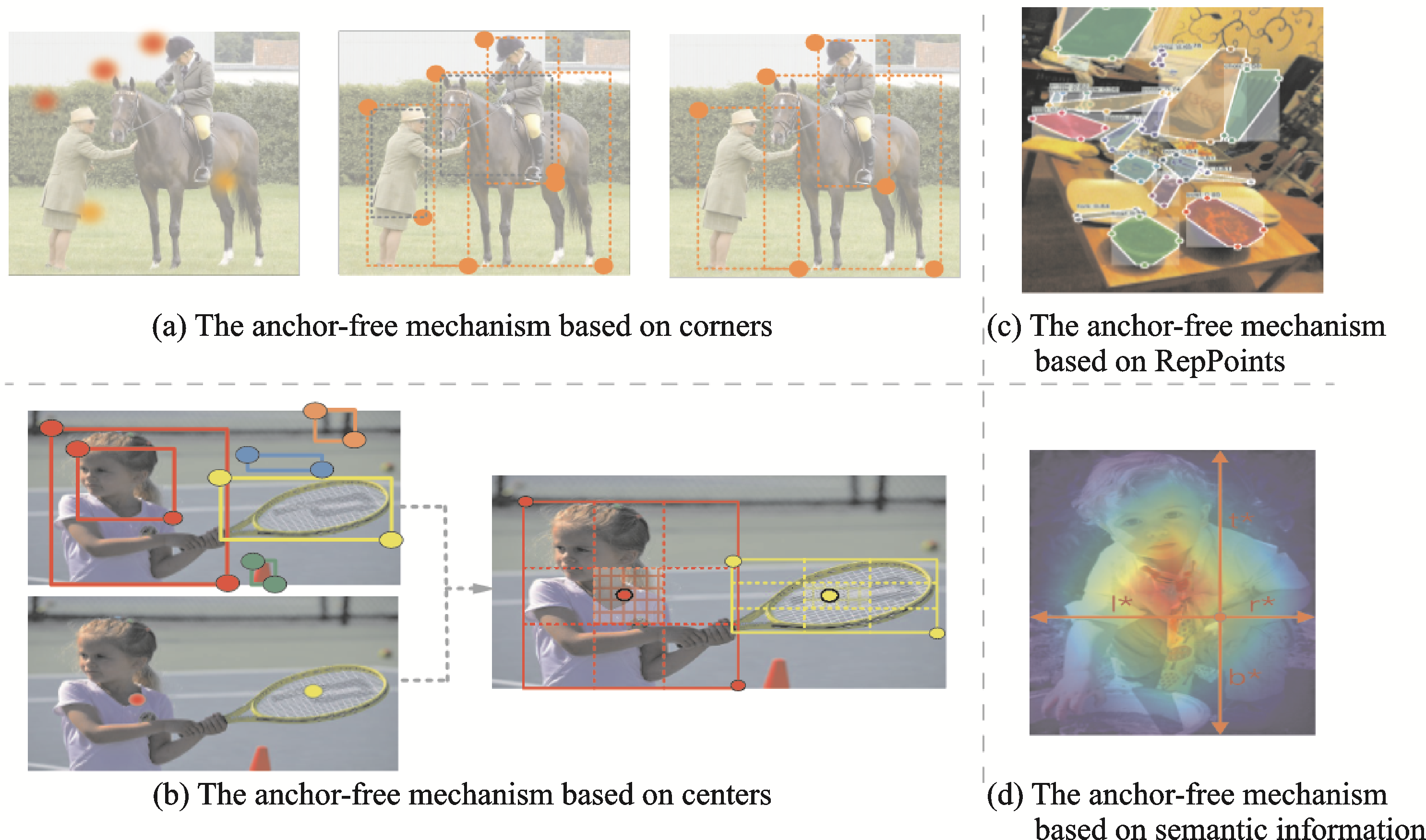
图4 无锚机制的4种形式
为了进一步提高目标检测性能,Duan等[97]提出了一种基于中心预测的目标检测框架,称为CenterNet(见图4(b))。CenterNet首先预左上角和右下角的角点以及中心关键点,然后通过角点匹配确定边界框,最后利用预测的中心点消除角点不匹配引起的不正确的边界框。与CenterNet类似,Zhou等[98]通过对极值点和中心点进行匹配,提出了一种自下而上的目标检测网络,称为ExtremeNet。ExtremeNet首先使用一个标准的关键点估计网络来预测最上面、最下面、最左边、最右边的4个极值点和中心点,然后在5个点几何对齐的情况下对它们进行分组以生成边界框。但是ExtremeNet和CornerNet等基于关键点的检测网络都需要经过一个关键点分组阶段,这降低了算法整体的速度。针对这一问题,Zhou等[99]将目标建模为其一个单点,即边界框中心点,无需对构建点进行分组或其他后处理操作。然后在探测器使用关键点估计来查找中心点,并回归到所有其他对象属性,如大小、位置等。这一方法很好地平衡了检测的精度与速度。
近年来,基于关键点的目标检测方法又有了新的扩展。Yang等[100]提出了一种名为代表点(RepPoints)的检测方法,提供了更细粒度的表示方式,使得目标可以被更精细地界定。同时,这种方法能够自动学习目标的空间信息和局部语义特征,一定程度上提升了小目标检测的精度(见图4(c))。更进一步地,Kong等[101]受到人眼的中央凹(视网膜中央区域,集中了绝大多数的视锥细胞,负责视力的高清成像)启发,提出了一种直接预测目标存在的可能性和边界框坐标的方法,该方法首先预测目标存在的可能性,并生成类别敏感语义图,然后为每一个可能包含目标的位置生成未知类别的边界框。由于摆脱了锚框的限制,FoveaBox对于小目标等具有任意横纵比的目标具备良好的鲁棒性和泛化能力,并在检测精度上也得到了较大提升。与FoveaBox相似,Tian等[102]使用语义分割的思想来解决目标检测问题,提出了一种基于全卷积的单级目标检测器FCOS(Fully convolutional one‑stage),避免了基于锚框机制的方法中超参过多、难以训练的问题(见图4(d))。此外,实验表明将两阶段检测器的第一阶段任务换成FCOS来实现,也能有效提升检测性能。而后,Zhu等[103]将无锚机制用于改进特征金字塔中的特征分配问题,根据目标语义信息而不是锚框来为目标选择相应特征,同时提高了小目标检测的精度与速度。Zhang等[104]则从基于锚框机制与无锚机制的本质区别出发,即训练过程中对于正负样本的定义不同,提出了一种自适应训练样本选择策略,根据对象的统计特征自动选择正反样本。针对复杂的场景下小型船舶难以检测的问题,Fu等[105]提出了一种新的检测方法——特征平衡与细化网络,采用直接学习编码边界框的一般无锚策略,消除锚框对于检测性能的负面影响,并使用基于语义信息的注意力机制平衡不同层次的多个特征,达到了最先进的性能。为了更有效地处理无锚框架下的多尺度检测,Yang等[106]提出了一种基于特殊注意力机制的特征金字塔网络,该网络能够根据不同大小目标的特征生成特征金字塔,进而更好地处理多尺度目标检测问题,显著提升了小目标的检测性能。
1.6 其他优化策略
在小目标检测这一领域,除了前文所总结的几个大类外,还有诸多优秀的方法。针对小目标训练样本少的问题,Kisantal等[33]提出了一种过采样策略,通过增加小目标对于损失函数的贡献,以此提升小目标检测的性能。除了增加小目标样本权重这一思路之外,另一种思路则是通过增加专用于小目标的锚框数量来提高检测性能。Zhang等[107]提出了一种密集锚框策略,通过在一个感受野中心设计多个锚框来提升小目标的召回率。与密集锚框策略相近,Zhang等[108]设计了一种基于有效感受野和等比例区间界定锚框尺度的方法,并提出一种尺度补偿锚框匹配策略来提高小人脸目标的召回率。增加锚框数量对于提升小目标检测精度十分有效,同时也额外增加了巨大的计算成本。Eggert等[109]从锚框尺度的优化这一角度入手,通过推导小目标尺寸之间的联系,为小目标选择合适的锚框尺度,在商标检测上获得了较好的检测效果。之后,Wang等[110]提出了一种基于语义特征的引导锚定策略,通过同时预测目标中心可能存在的位置及目标的的尺度和纵横比,提高了小目标检测的性能。此外,这种策略可以集成到任何基于锚框的方法中。但是,这些改进没有实质性地平衡检测精度与计算成本之间的矛盾。
近些年来,随着计算资源的增加,越来越多的网络使用级联思想来平衡目标漏检率与误检率。级联这一思想来源已久[111],并在目标检测领域得到了广泛的应用。它采用了从粗到细的检测理念:用简单的计算过滤掉大多数简单的背景窗口,然后用复杂的窗口来处理那些更困难的窗口。随着深度学习时代的到来,Cai等[25]提出了经典网络Cascade R‑CNN,通过级联几个基于不同IoU阈值的检测网络达到不断优化预测结果的目的。之后,Li等[112]在Cascade R‑CNN的基础上进行了扩展,进一步提升了小目标检测性能。受到级联这一思想的启发,Liu等[113]提出了一种渐近定位策略,通过不断增加IoU阈值来提升行人检测的检测精度。另外,文献[114‑116]展现了级联网络在困难目标检测上的应用,也一定程度上提升了小目标的检测性能。
另外一种思路则是分阶段检测,通过不同层级之间的配合平衡漏检与误检之间的矛盾。Chen等[117]提出一种双重探测器,其中第一尺度探测器最大限度地检测小目标,第二尺度探测器则检测第一尺度探测器无法识别的物体。进一步地,Drenkow等[118]设计了一种更加高效的目标检测方法,该方法首先在低分辨率下检查整个场景,然后使用前一阶段生成的显著性地图指导后续高分辨率下的目标检测。这种方式很好地权衡了检测精度和检测速度。此外,文献[119‑121]针对空中视野图像中的困难目标识别进行了前后景的分割,区分出重要区域与非重要区域,在提高检测性能的同时也减少了计算成本。
优化损失函数也是一种提升小目标检测性能的有效方法。Redmon等[26]发现,在网络的训练过程中,小目标更容易受到随机误差的影响。随后,他们针对这一问题进行了改进[27],提出一种依据目标尺寸设定不同权重的损失函数,实现了小目标检测性能的提升。Lin等[122]则针对类别不均衡问题,在RetinaNet中提出了焦距损失,有效解决了训练过程中存在的前景‑背景类不平衡问题。进一步地,Zhang等[123]将级联思想与焦距损失相结合,提出了Cascade RetinaNet,进一步提高了小目标检测的精度。针对小目标容易出现的前景与背景不均衡问题,Deng等[58]则提出了一种考虑前景‑背景之间平衡的损失函数,通过全局重建损失和正样本块损失提高前景与背景的特征质量,进而提升了小目标检测的性能。
为了权衡考虑小目标的检测精度和速度,Sun等[124]提出了一种多接受域和小目标聚焦弱监督分割网络,通过使用多个接收域块来关注目标及其相邻背景,并依据不同空间位置设置权重,以达到增强特征可辨识性的目的。此外,Yoo等[125]将多目标检测任务重新表述为边界框的密度估计问题,提出了一种混合密度目标检测器,通过问题的转换避免了真值框与预测框匹配以及启发式锚框设计等繁琐过程,也一定程度上解决了前景与背景不平衡的问题。
二、参考文献
- YAEGER L,LYON R,WEBB B.Effective training of a neural network character classifier for word recognition[J].Advances in Neural Information Processing Systems,1996,9: 807‑816. [百度学术]
- SIMARD P Y, STEINKRAUS D, PLATT J C. Best practices for convolutional neural networks applied to visual document analysis[C]//Proceedings of ICDAR. [S.l.]: IEEE, 2003, 3(2003). [百度学术]
- KRIZHEVSKY A, SUTSKEVER I, HINTON G E.Imagenet classification with deep convolutional neural networks[J].Advances in Neural Information Processing Systems,2012,25: 1097‑1105. [百度学术]
- WAN L, ZEILER M, ZHANG S, et al. Regularization of neural networks using dropconnect[C]//Proceedings of International Conference on Machine Learning. [S.l.]: PMLR, 2013: 1058‑1066. [百度学术]
- GIRSHICK R. Fast R‑CNN[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2015: 1440‑1448. [百度学术]
- CAI Z, VASCONCELOS N. Cascade R‑CNN: Delving into high quality object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 6154‑6162. [百度学术]
- REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real‑time object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779‑788. [百度学术]
- REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 7263‑7271. [百度学术]
- DEVRIES T,TAYLOR G W.Improved regularization of convolutional neural networks with cutout[EB/OL].(2017‑08‑15)[2017‑11‑29].https://arxiv.org/abs/1708.04552. [百度学术]
- ZHANG H,CISSE M,DAUPHIN Y N,et al.Mixup: Beyond empirical risk minimization[EB/OL].(2017‑10‑25)[2018‑04‑27].https://arxiv.org/abs/1710.09412. [百度学术]
- YUN S, HAN D, OH S J, et al. Cutmix: Regularization strategy to train strong classifiers with localizable features[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 6023‑6032. [百度学术]
- BOCHKOVSKIY A,WANG C Y,LIAO H Y M.Yolov4: Optimal speed and accuracy of object detection[EB/OL].(2020‑04‑23)[2020‑04‑23].https://arxiv.org/abs/2004.10934. [百度学术]
- GONG C,WANG D,LI M,et al.KeepAugment: A simple information‑preserving data augmentation approach[EB/OL].(2020‑11‑23)[2020‑11‑23].https://arxiv.org/abs/2011.11778. [百度学术]
- KISANTAL M,WOJNA Z,MURAWSKI J,et al. Augmentation for small object detection[EB/OL].(2019‑02‑19)[2019‑02‑19]. https://arxiv.org/abs/1902.07296. [百度学术]
- CHEN C, ZHANG Y, LV Q, et al. RRNet: A hybrid detector for object detection in drone‑captured images[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. Los Alamitos: IEEE, 2019: 100‑108. [百度学术]
- CHEN Y,ZHANG P,LI Z,et al.Stitcher: Feedback‑driven data provider for object detection[EB/OL].(2020‑04‑26)[2021‑03‑14]. https://arxiv.org/abs/2004.12432. [百度学术]
- ZOPH B, CUBUK E D, GHIASI G, et al. Learning data augmentation strategies for object detection[C]//Proceedings of European Conference on Computer Vision. Cham: Springer, 2020: 566‑583. [百度学术]
- YU F,KOLTUN V.Multi‑scale context aggregation by dilated convolutions[EB/OL].(2015‑11‑23)[2016‑04‑30].https://arxiv.org/abs/1511.07122. [百度学术]
- DAI J, QI H, XIONG Y, et al.Deformable convolutional networks[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 764‑773. [百度学术]
- ADELSON E H,ANDERSON C H,BERGEN J R,et al.Pyramid methods in image processing[J].RCA Engineer,1984,29(6): 33‑41. [百度学术]
- LOWE D G.Distinctive image features from scale‑invariant keypoints[J].International Journal of Computer Vision,2004,60(2): 91‑110. [百度学术]
- DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//Proceedings of IEEE Computer Society Conference on Computer Vision & Pattern Recognition. [S.l.]: IEEE, 2005. [百度学术]
- SINGH B, DAVIS L S. An analysis of scale invariance in object detection snip[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 3578‑3587. [百度学术]
- SINGH B,NAJIBI M,DAVIS L S.Sniper: Efficient multi‑scale training[EB/OL].(2018‑05‑23)[2018‑12‑13].https://arxiv.org/abs/1805.09300. [百度学术]
- REN S,HE K,GIRSHICK R,et al.Faster R‑CNN: Towards real‑time object detection with region proposal networks[EB/OL].(2015‑06‑04)[2016‑01-06].https://arxiv.org/abs/1506.01497. [百度学术]
- HE K,ZHANG X,REN S,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9): 1904-1916. [百度学术]
- DAI J, LI Y, HE K, et al.R-FCN: Object detection via region-based fully convolutional networks[EB/OL].(2016-05-20)[2016-06-21].https://arxiv.org/abs/1605.06409. [百度学术]
- LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//Proceedings of European Conference on Computer Vision. Cham: Springer, 2016: 21-37. [百度学术]
- CAI Z, FAN Q, FERIS R S, et al. A unified multi-scale deep convolutional neural network for fast object detection[C]//Proceedings of European Conference on Computer Vision. Cham: Springer, 2016: 354-370. [百度学术]
- BELL S, ZITNICK C L, BALA K, et al. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 2874-2883. [百度学术]
- KONG T, YAO A, CHEN Y, et al. Hypernet: Towards accurate region proposal generation and joint object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 845-853. [百度学术]
- LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 2117-2125. [百度学术]
- LIANG Z, SHAO J, ZHANG D, et al. Small object detection using deep feature pyramid networks[C]//Proceedings of Pacific Rim Conference on Multimedia. Cham: Springer, 2018: 554-564. [百度学术]
- CAO G, XIE X, YANG W, et al. Feature-fused SSD: Fast detection for small objects[C]//Proceedings of Ninth International Conference on Graphic and Image Processing (ICGIP 2017). Bellingham: SPIE-int SOC Optical Engineering, 2018: 106151E. [百度学术]
- LI Z,ZHOU F.FSSD: Feature fusion single shot multibox detector[EB/OL].(2017-12-04)[2018-05-17].https://arxiv.org/abs/1712.00960. [百度学术]
- 韩松臣,张比浩,李炜,等.基于改进Faster-RCNN的机场场面小目标物体检测算法[J].南京航空航天大学学报,2019,51(6):735-741. [百度学术]
- NAYAN A A,SAHA J,MOZUMDER A N,et al.Real time detection of small objects[EB/OL].(2020-03-17)[2020-04-14].https://arxiv.org/abs/2003.07442. [百度学术]
- LIU Z,GAO G,SUN L,et al.HRDNet: High-resolution detection network for small objects[EB/OL].(2020-06-13)[2020-06-13].https://arxiv.org/abs/2006.07607. [百度学术]
- DENG C,WANG M,LIU L,et al.Extended feature pyramid network for small object detection[EB/OL].(2020-05-16)[2020-04-09].https://arxiv.org/abs/2003.07021. [百度学术]
- OLIVA A,TORRALBA A.The role of context in object recognition[J].Trends in Cognitive Sciences,2007,11(12): 520-527. [百度学术]
- LI J,WEI Y,LIANG X,et al.Attentive contexts for object detection[J].IEEE Transactions on Multimedia,2016,19(5): 944-954. [百度学术]
- ZENG X,OUYANG W,YAN J,et al.Crafting gbd-net for object detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,40(9): 2109-2123. [百度学术]
- TANG X, DU D K, HE Z, et al. Pyramidbox: A context-assisted single shot face detector[C]// Proceedings of the European Conference on Computer Vision (ECCV). Cham: Springer, 2018: 797-813. [百度学术]
- ZHENG Chenbin,ZHANG Yong,HU Hang,et al.Object detection enhanced context model[J].Journal of Zhejiang University (Engineering Science),2020,54(3): 529-539. [百度学术]
- DIVVALA S K, HOIEM D, HAYS J H, et al. An empirical study of context in object detection[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2009: 1271-1278. [百度学术]
- TORRALBA A, SINHA P. Statistical context priming for object detection[C]// Proceedings of the Eighth IEEE International Conference on Computer Vision. New York: IEEE, 2001: 763-770. [百度学术]
- FELZENSZWALB P F,GIRSHICK R B,MCALLESTER D,et al.Object detection with discriminatively trained part-based models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,32(9): 1627-1645. [百度学术]
- OUYANG W, WANG X, ZENG X, et al. Deepid-net: Deformable deep convolutional neural networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2015: 2403-2412. [百度学术]
- CHEN Z, HUANG S, TAO D. Context refinement for object detection[C]// Proceedings of the European Conference on Computer Vision (ECCV). Cham: Springer, 2018: 71-86. [百度学术]
- BARNEA E, BEN-SHAHAR O. Exploring the bounds of the utility of context for object detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 7412-7420. [百度学术]
- CHEN Z M, JIN X, ZHAO B, et al. Hierarchical context embedding for region-based object detection[C]//Proceedings of European Conference on Computer Vision. Cham: Springer, 2020: 633-648. [百度学术]
- ZHANG Ruiyan,JIANG Xiujie,AN Junshe, et al.Design of global-contextual detection model for optical remote sensing targets[J].Chinese Optics,2020,13(73): 138-149. [百度学术]
- HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 2961-2969. [百度学术]
- ZHAO X, LIANG S, WEI Y. Pseudo mask augmented object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 4061-4070. [百度学术]
- ZHANG Z, QIAO S, XIE C, et al. Single-shot object detection with enriched semantics[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 5813-5821. [百度学术]
- CHEN Q,SONG Z,DONG J,et al.Contextualizing object detection and classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,37(1): 13-27. [百度学术]
- GUPTA S,HARIHARAN B,MALIK J.Exploring person context and local scene context for object detection[EB/OL].(2015-11-25)[2015-11-25].https://arxiv.org/abs/1511.08177. [百度学术]
- LIU Y, WANG R, SHAN S, et al. Structure inference net: Object detection using scene-level context and instance-level relationships[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 6985-6994. [百度学术]
- XU H, JIANG C H, LIANG X, et al. Reasoning-RCNN: Unifying adaptive global reasoning into large-scale object detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 6419-6428. [百度学术]
- CHEN X, GUPTA A. Spatial memory for context reasoning in object detection[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 4086-4096. [百度学术]
- HU H, GU J, ZHANG Z, et al. Relation networks for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 3588-3597. [百度学术]
- LIM J S,ASTRID M,Yoon H J,et al.Small object detection using context and attention[EB/OL].(2019-12-13)[2019-12-16].https://arxiv.org/abs/1912.06319. [百度学术]
- SHEN W, QIN P, ZENG J. An indoor crowd detection network framework based on feature aggregation module and hybrid attention selection module[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. Los Alamitos:IEEE, 2019: 82-90. [百度学术]
- FU K,LI J,MA L,et al.Intrinsic relationship reasoning for small object detection[EB/OL].(2020-09-02)[2020-09-02].https://arxiv.org/abs/2009.00833. [百度学术]
- PATO L V, NEGRINHO R, AGUIAR P M Q. Seeing without looking: Contextual rescoring of object detections for ap maximization[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 14610-14618. [百度学术]
- HARIS M,SHAKHNAROVICH G,UKITA N.Task-driven super resolution: Object detection in low-resolution images[EB/OL].(2018-03-30)[2018-03-30].https://arxiv.org/abs/1803.11316. [百度学术]
- GOODFELLOW I J,POUGET-ABADIE J,MIRZA M,et al.Generative adversarial networks[EB/OL].(2014-06-10)[2014-06-10].https://arxiv.org/abs/1406.2661. [百度学术]
- RADFORD A,METZ L,CHINTALA S.Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL].(2015-11-19)[2016-01-07].https://arxiv.org/abs/1511.06434. [百度学术]
- SIXT L,WILD B,LANDGRAF T.Rendergan: Generating realistic labeled data[J].Frontiers in Robotics and AI,2018,5: 66. [百度学术]
- WANG X, SHRIVASTAVA A, GUPTA A. A-fast-RCNN: Hard positive generation via adversary for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 2606-2615. [百度学术]
- LI J, LIANG X, WEI Y, et al. Perceptual generative adversarial networks for small object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 1222-1230. [百度学术]
- BAI Y, ZHANG Y, DING M, et al. SOD-MTGAN: Small object detection via multi-task generative adversarial network[C]// Proceedings of the European Conference on Computer Vision (ECCV). Cham: Springer, 2018: 206-221. [百度学术]
- NOH J, BAE W, LEE W, et al. Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 9725-9734. [百度学术]
- TYCHSEN-SMITH L, PETERSSON L. Denet: Scalable real-time object detection with directed sparse sampling[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 428-436. [百度学术]
- WANG X,CHEN K,HUANG Z, et al.Point linking network for object detection[EB/OL].(2017-06-12)[2017-06-13].https://arxiv.org/abs/1706.03646. [百度学术]
- LAW H, DENG J. Cornernet: Detecting objects as paired keypoints[C]// Proceedings of the European Conference on Computer Vision (ECCV). Cham: Springer, 2018: 734-750. [百度学术]
- LAW H,TENG Y,RUSSAKOVSKY O, et al.Cornernet-lite: Efficient keypoint based object detection[EB/OL].(2017-06-12)[2017-06-13].https://arxiv.org/abs/1706.03646. [百度学术]
- DUAN K, BAI S, XIE L, et al. Centernet: Keypoint triplets for object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 6569-6578. [百度学术]
- ZHOU X, ZHUO J, KRAHENBUHL P. Bottom-up object detection by grouping extreme and center points[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 850-859. [百度学术]
- ZHOU X,WANG D,KRÄHENBÜHL P.Objects as points[EB/OL].(2019-04-16)[2019-04-25].https://arxiv.org/abs/1904.07850. [百度学术]
- YANG Z, LIU S, HU H, et al. Reppoints: Point set representation for object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 9657-9666. [百度学术]
- KONG T,SUN F,LIU H,et al.Foveabox: Beyound anchor-based object detection[J].IEEE Transactions on Image Processing,2020,29: 7389-7398. [百度学术]
- TIAN Z, SHEN C, CHEN H, et al. Fcos: Fully convolutional one-stage object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 9627-9636. [百度学术]
- ZHU C, HE Y, SAVVIDES M. Feature selective anchor-free module for single-shot object detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 840-849. [百度学术]
- ZHANG S, CHI C, YAO Y, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2020: 9759-9768. [百度学术]
- FU J,SUN X,WANG Z,et al.An anchor-free method based on feature balancing and refinement network for multiscale ship detection in SAR images[J].IEEE Transactions on Geoscience and Remote Sensing,2020, 59(2): 1331-1344. [百度学术]
- YAN J, ZHAO L, DIAO W, et al.AF-EMS detector: Improve the multi-scale detection performance of the anchor-free detector[J].Remote Sensing,2021,13(2): 160. [百度学术]
- ZHANG S, ZHU X, LEI Z, et al. Faceboxes: A CPU real-time face detector with high accuracy[C]//Proceedings of 2017 IEEE International Joint Conference on Biometrics (IJCB). New York: IEEE, 2017: 1-9. [百度学术]
- ZHANG S, ZHU X, LEI Z, et al. S3FD: Single shot scale-invariant face detector[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 192-201. [百度学术]
- EGGERT C, ZECHA D, BREHM S, et al. Improving small object proposals for company logo detection[C]// Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval. New York: Assoc Computing Machinery, 2017: 167-174. [百度学术]
- WANG J, CHEN K, YANG S, et al. Region proposal by guided anchoring[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 2965-2974. [百度学术]
- VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[C]// Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001. New York: IEEE, 2001: 1-9. [百度学术]
- LI A,YANG X,ZHANG C.Rethinking classification and localization for cascade R-CNN[EB/OL].(2019-07-27)[2019-07-27].https://arxiv.org/abs/1907.11914. [百度学术]
- LIU W, LIAO S, HU W, et al. Learning efficient single-stage pedestrian detectors by asymptotic localization fitting[C]// Proceedings of the European Conference on Computer Vision (ECCV). Cham: Springer, 2018: 618-634. [百度学术]
- YANG B, YAN J, LEI Z, et al. Craft objects from images[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 6043-6051. [百度学术]
- YANG F, CHOI W, LIN Y. Exploit all the layers: Fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers[C]// Proceedings of the IEEE conference on computer vision and pattern recognition. New York: IEEE, 2016: 2129-2137. [百度学术]
- GAO M, YU R, LI A, et al. Dynamic zoom-in network for fast object detection in large images[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 6926-6935. [百度学术]
- CHEN S,LI J,YAO C,et al.DuBox: No-prior box objection detection via residual dual scale detectors[EB/OL].(2019-04-15)[2019-04-16].https://arxiv.org/abs/1904.06883. [百度学术]
- DRENKOW N,BURLINA P,FENDLEY N,et al.Objectness-guided open set visual search and closed set detection[EB/OL].(2020-12-11)[2021-04-14].https://arxiv.org/abs/2012.06509. [百度学术]
- YANG F, FAN H, CHU P, et al. Clustered object detection in aerial images[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE, 2019: 8311-8320. [百度学术]
- ZHANG J, HUANG J, CHEN X, et al. How to fully exploit the abilities of aerial image detectors[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. Los Alamitos:IEEE, 2019: 1-8. [百度学术]
- LI C, YANG T, ZHU S, et al. Density map guided object detection in aerial images[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Los Alamitos:IEEE, 2020: 190-191. [百度学术]
- LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the IEEE International Conference on Computer Vision. New York: IEEE, 2017: 2980-2988. [百度学术]
- ZHANG H,CHANG H,MA B,et al.Cascade retinanet: Maintaining consistency for single-stage object detection[EB/OL].(2019-07-16)[2019-07-16].https://arxiv.org/abs/1907.06881. [百度学术]
- SUN S,YIN Y,WANG X,et al.Multiple receptive fields and small-object-focusing weakly-supervised segmentation network for fast object detection[EB/OL].(2019-04-19)[2019-05-22].https://arxiv.org/abs/1904.12619. [百度学术]
- YOO J,LEE H,CHUNG I,et al.Density-based object detection: Learning bounding boxes without ground truth assignment[EB/OL].(2019-11-28)[2020-10-04].https://arxiv.org/abs/1911.12721. [百度学术]