梯度下降
最简单的梯度下降格式
x+=−learning_rate∗dx 动量(Momentum)更新
在普通版本中,梯度直接影响位置。而在这个版本的更新中,物理观点建议梯度只是影响速度,然后速度再影响位置:
动量更新
v=mu∗v−learning_rate∗dx x+=v Nesterov动量与普通动量有些许不同,最近变得比较流行。在理论上对于凸函数它能得到更好的收敛,在实践中也确实比标准动量表现更好一些.
v_prev=v #备份速度v=mu∗v−learning_rate∗dx x+=−mu∗v_prev+(1+mu)∗v
Adagrad是一个由Duchi等提出的适应性学习率算法
#假设有梯度和参数变量x
cache+=dx∗∗2 x+=−learning_rate∗da/(np.sqrt(cacahe)+eps) Adagrad的一个缺点是,在深度学习中单调的学习率被证明通常过于激进且过早停止学习。
RMSprop。是一个非常高效,但没有公开发表的适应性学习率方法。有趣的是,每个使用这个方法的人在他们的论文中都引用自Geoff Hinton的Coursera课程的第六课的第29页PPT。这个方法用一种很简单的方式修改了Adagrad方法,让它不那么激进,单调地降低了学习率。具体说来,就是它使用了一个梯度平方的滑动平均:
cache=decay_rate∗cache+(1−decay_rate)∗dx∗∗2 x+=−learning_rate∗dx/(np.sqrt(cache)+eps) RMSProp仍然是基于梯度的大小来对每个权重的学习率进行修改,这同样效果不错。但是和Adagrad不同,其更新不会让学习率单调变小。
Adam。[Adam]是最近才提出的一种更新方法,它看起来像是RMSProp的动量版。简化的代码是下面这样:
m=beta1∗m+(1−beta1)∗dx v=beta2∗v+(1−beta2)∗(dx∗∗2) x+=−learning_rate∗m/(np.sqrt(v)+eps) 注意这个更新方法看起来真的和RMSProp很像,除了使用的是平滑版的梯度m,而不是用的原始梯度向量dx。论文中推荐的参数值eps=1e-8, beta1=0.9, beta2=0.999。在实际操作中,我们推荐Adam作为默认的算法,一般而言跑起来比RMSProp要好一点。但是也可以试试SGD+Nesterov动量。完整的Adam更新算法也包含了一个偏置(bias)矫正机制,因为m,v两个矩阵初始为0,在没有完全热身之前存在偏差,需要采取一些补偿措施。
批标准化
批标准化(Batch Normalization,BN)和之前对数据集的标准化类似,是将分散的数据进行统一的一种做法。具有统一规格的数据,能让机器更容易学习到数据中的规律。
对于含有m个节点的某一层神经网络,对z进行BN操作的步骤为:
μ=1m∑mi=1z(i) σ2=1m∑mi=1(z(i)−μ)2 z(i)norm=z(i)−μσ2+ϵ√ z¯inorm=γ∗z(i)norm+β 其中的
γ 、β 不是超参数,而是两个需要学习的参数,神经网络自己去学着使用和修改这个扩展参数。这样神经网络就能自己慢慢琢磨出前面的标准化操作到底有没有起到优化的作用, 如果没有起到作用, 就使用 γγ和ββ来抵消一些之前进行过的标准化的操作。例如当γ=σ2+ϵ−−−−−√ ,β=μ ,就抵消掉了之前的正则化操作。当前的获得的经验无法适应新样本、新环境时,便会发生”Covariate Shift”现象。对于一个神经网络,前面权重值的不断变化就会带来后面权重值的不断变化,BN算法减缓了隐藏层权重分布变化的程度。采用批标准化之后,尽管每一层的z还是在不断变化,但是它们的均值和方差将基本保持不变,这就使得后面的数据更加稳定,数据分布更加稳定,这就减少前面层与后面层的耦合,使得每一层不过多依赖前面的网络层,最终加快整个神经网络的训练。
BN还有附带的有正则化的效果。当使用小批量梯度下降时,对每个小批量进行批标准化时,会给这个小批量中最后求得的z带来一些噪音,类似与DropOut的正则化效果,但效果不是很显著。当这个小批量的数量越大时,正则化的效果越弱。需要注意的是,BN并不是正则化的手段,正则化效果只是其顺带的小副作用。
另外,在训练时用到了BN,则在测试时也要用到BN才行。训练时,输入的小批量的训练样本,而测试时,测试样本是一个一个输入的。这里就又要用到指数加权平均,在训练过程中,求得每个小批量的均值和方差的数加权平均值,之后将最终的结果保存并应用到测试过程中。
(补充)进行归一化以后会改变原始数据的分布,这样的话网络每层的输出会不能得到很好的表达,引入两个参数进行调整,而且这两个参数是网络自己训练学习.
优点:
最主要的减少梯度消失,加快收敛速度。
然后允许更大的学习率、不需要dropout、减少L2正则、减少扭转图像(其实都是第一个好处带来的)。
误差分析
如果试图让学习算法完成通常由人类所做的任务,但它并没达到人类水平的话,就需要人工检查一下学习算法所犯的错误,这有助于了解接下来需要去做什么,这个过程被称为误差分析。
进行误差分析首先应该找一组错误例子,这些错误例子可能在开发集或者测试集里。然后观察这些错误标记的例子,察看它们的假阳性和假阴性,统计属于不同错误类型的错误数量。在这个过程中,有时可能会得到启发,归纳出新的误差类型,例如视频中所提的 lnstagram 的滤镜问题。那么,针对这一新类型可以在表格中新建一个错误类型,将其纳入误差分析中。总之,通过统计不同错误标记类型占总数的百分比将有助于发现哪些问题需要优先解决,或者能够提供构思新优化方向的灵感。

### 迁移学习
深度学习中最强大的理念之一就是有时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个的任务中。例如已经训练好了一个能够识别猫的神经网络,但当将其使用在阅读 X 射线扫描图时,它依旧可以用那些知识或者部分习得的知识去帮助阅读 X射线扫描图。这就是所谓的迁移学习。
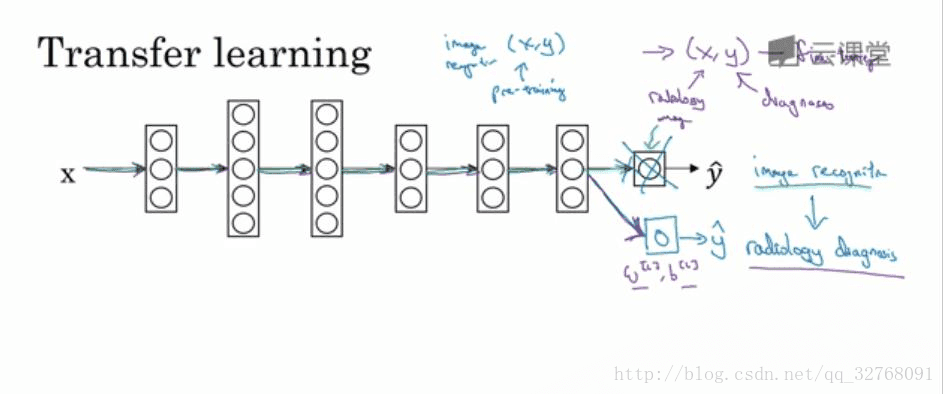
假设已经训练好了如下图所示的一个图像识别神经网络,那么如果想要将这个神经网络应用在放射科诊断中,就需要将神经网络的最后的输出层和进入到最后一层的权重删除,然后为最后一层重新赋予随机权重,最后让它在发射诊断数据上训练
具体来说,在第一阶段的训练过程中,当进行图像识别任务训练时,就如同平常训练深度神经网络时一样的流程训练所有常用参数、所有的权重和所有的层,然后就可以得到一个能够做图像识别预测的网络。在训练好这个神经网络后,要实现迁移学习,就需要将训练集换成新的(x,y)对,其中 x 是放射科图像,y 是想要预测诊断。另外要做的是初始化最后一层的权重——随机初始化
x[l] 和c[l] ,然后使用这个新数据集来重新训练网络。在新的放射科数据集上重新训练网络有两种做法:一是如果放射科数据集很小,那么只需要重新训练最后一层的权重——x[l] 和c[l] ,并保持其他参数不变;二是如果有足够多的数据,可以重新训练神经网络中剩下的所有层。如果要重新训练神经网络中的所有参数,那么这个在图像识别数据的初期训练阶段有时被称为预训练,而在发射科数据上重新更新所有权重的过程有时则被称为微调。
迁移学习起作用的原因
因为有很多低层次特征,比如边缘检测、曲线检测和阳性对象检测等,可以从非常大的图像识别数据库中学习得到,这就可能有助于学习算法在放射科诊断中做得更好。算法学到了很多结构信息和图像形状的信息,其中的一些知识可能会很有用,所以网络学会了图像识别之后就有足够多的信息来了解不同图像的组成部分是怎么样的,而这些知识都有可能有助于放射科诊断网络学习得更快一些或者只需要更少的学习数据。
迁移学习的意义或者说起作用的范围
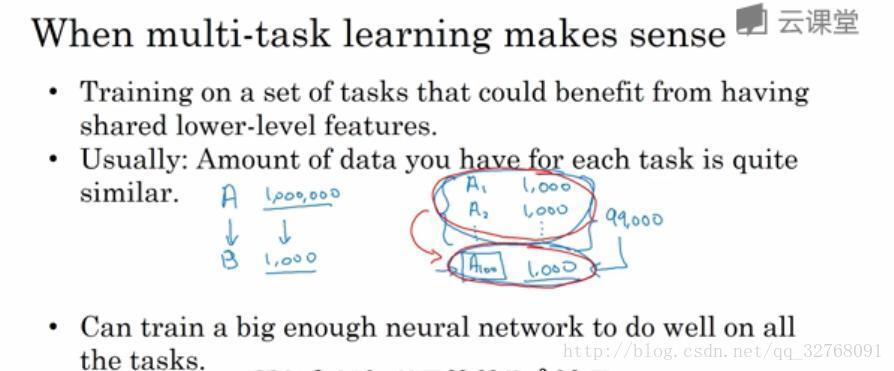
迁移学习起作用的场合是迁移来源有很多某个问题的数据,但迁移目标问题却没有那么多数据。假如图像识别任务中有 1 百万个样本,这就有足够的数据帮助神经网络学习低层次特征。如果放射科任务只有一百个样本,那么就意味着放射科诊断问题的数据很少,这时,将从图像识别训练中学习到的很多知识迁移到放射科诊断问题就是合理的。
多任务学习(Multi-task learning)
迁移学习是个串行任务学习,从任务 A 中学到知识,然后迁移到任务 B。但在多任务学习中,却是同时开始学习的,它试图让单个神经网络同时做几个任务,然后希望每个任务都能帮到其他所有任务。
下图是一个关于无人驾驶车的例子,它需要同时检测不同的物体,比如检测行人、车辆、停车标志和交通等。例如下图左侧的图片中有一个停车标志和一辆车,但没有行人和交通灯。如果这张图片就是输入

现在需要训练一个神经网络来预测上图中的 y 值,例如使用下图中的神经网络。为了去训练这个神经网络,就需要定义神经网络的损失函数:
端到端的学习
简而言之,以前有一些数据处理系统或者学习系统,它们通常需要分多个步骤来处理,那么端到端深度学习就是略所有这些不同的阶段,用单个神经网代替它。以语音识别为例,输入 x 是音频,然后把它映射到一个输出 y,也就是一段音频的听写文本。传统的语音识别需要多个步骤来处理,首先需要利用如 MFCC 之类的方法提取一些手工设计的音频特征,然后可以应用机器学习算法在音频片段中找到音位(声音的基本单位),接着将音位串在一起构成独立的词,最后再将词串起来构成音频片段的听写文本。而端到端深度学习做的是训练一个巨大的神经网络,输入是一段音频,输出直接是听写文本。很多事实证明,端到端深度学习的挑战之一是可能需要大量数据才能让系统表现得良好。例如如果只有 3000 小时的数据去训练这个语音识别系统,那么传统的流水线上得到的效果会好于端到端深度学习。但当拥有非常大的数据集时,比如 10000 小时或 100000 小时的数据,那么端到端深度学习的效果就会很好。如果数据量属于中等的话,可以混合着使用中间步骤和神经网络。
端到端的深度学习方法的优点有:端对端学习真的是让数据说话,所以如果有足够多的(x,y)数据,那么不管从x 到 y 最适合的函数映射是什么,都可以搭建一个大的神经网络让它自己学习最适合的函数映射。并且使用这种方法,可能更能够捕获数据中的所有统计信息,而不是被迫引入人类的成见。例如在语音识别领域,早期的识别系统有音位这个概念。端对端深度学习的第二个好处就是所需手工设计的组件更少,所以这也许能够简化整个设计工作流程。端对端深度学习的缺点有:端对端深度学习可能需要大量的数据来学习 x 到 y 的映射。另一个缺点是端到端的深度学习排除了可能有用的手工设计组件。在数据量很小的情况下,手工设计组件把人类知识直接注入算法,并总不是一件坏事。