1.浅谈Hadoop原理
HDFS的NameNode是管理者,DataNode是被管理者。
举个例子:假如我们想向HDFS分布式系统上传一个大小为200M的日志文件,那么HDFS系统是如何工作的呢?在这里为了能够把原理说的更加清楚明了,我们就举例来说明,Client(客户端)相当于一个送货人,现在它要把货物(a.log)送到仓库里,那么首先送货人要跟仓库管理员联系,那么NameNode就充当着仓库管理员的角色,送货人告诉仓库管理员说有一个200M的货物需要放到仓库,然后NameNode就查看仓库信息,看看哪些仓库现在还有空间,找到有空闲空间的仓库后把仓库号告诉送货人(Client),然后送货人就按着仓库号去仓库找到对应的仓库号把货物放到仓库里。
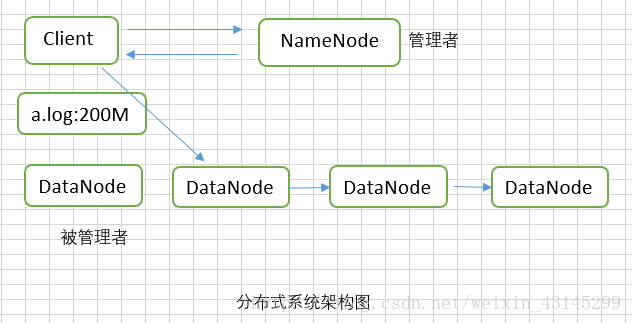
当然,上面举得例子只是为了方便大家理解,比较专业的说法是:客户端Client通过使用RPC向NameNode发送写文件的请求,NameNode会查看哪个DataNode空闲,比如上图中第二个DataNode,NameNode把空闲的DataNode信息返回给Client,Client接收到返回信息后,便开始向第二个DataNode里面写数据,写数据的过程是这样的,第二个DataNode先向NameNode申请一个区块的地址(Hadoop2.0区块的默认大小128M,而Hadoop1.0区块的大小默认是64M,如今我们要写的文件大小是200M,因此每个DataNode需要申请两个区块),NameNode批准后Client便开始向第一个区块里面写数据,当写满第一个区块后,第二个DataNode查看一下是否满足了NameNode设置的副本的数量,如果还没有达到,那么便向NameNode申请一个相邻DataNode的区块地址(本例中是第三个),申请成功后,第二个DataNode便开始向第三个DataNode水平传递数据,当写满为第三个DataNode申请的第一个区块后,轮到第三个DataNode查看是否满足NameNode设置的副本数量了,如果还不满足,那么就由第三个DataNode来向NameNode申请相邻DataNode的一个区块地址,申请成功后便由第三个DataNode将数据传递到第四个DataNode的一个区块上,如此直到保存的副本的数量与NameNode设置的副本数量一致时就不用再向新的DataNode传递数据了。当第四个DataNode写完第一个区块的内容后会将写的结果反馈给第三个DataNode,第三个DataNode把自己和第四个DataNode的写入结果返回给第二个DataNode,第二个DataNode发现后面的两个DataNode都写成功了便开始向NameNode申请自己这个节点的第二个区块的地址,然后Client便向第二个DataNode的第二个区块内写入剩下的内容,写完后同上向NameNode申请相邻DataNode的区块地址并按流水线的方式传递数据,直到所有的内容都写入完毕。NameNode会记录下来都是哪些DataNode上的哪些区块存储了上传的数据,这样后面如果Client向NameNode申请读取a.log文件时,NameNode便可以告诉Client去哪些DataNode上的哪些区块上去读。
2.为何引用区块概念?
对于上面说到了区块的概念,很多人可能不太理解为什么向DataNode写数据需要引入区块的概念呢?
我们举个例子,假如现在有个1G的文件,按照分区块的思想,我们会把这个文件分成8个区块存储,而且存储的顺序必须是先存完第一个区块才能接着存第二个区块,当我们存储到第8个区块的时候出现了问题,这时HDFS系统会记住常出现问题的区块数以及偏移量(即数据从多少到多少之间存储发生了错误),那么这时HDFS系统只需要重新存一下第8个区块的内容,而不需要从头再来重新全部存储一遍,这样明显可以提高容错能力及写入性能。
3.分布式文件系统优势
- 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
- 是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
- 通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 分布式文件管理系统很多,HDFS只是其中一种。适用于一次写入多次查询的情况,不支持并发写的情况,小文件不合适。
每一款工具或技术都有它自己所专长的特点,我们尽量利用它的长处就好了。