上节我们学习了JDK安装,这节我们学习一下Hadoop的安装及环境配置
首先我们需要到Apache官网下载我们需要的Hadoop版本,Apache产品官网是:http://archive.apache.org/dist/如下图所示,我们可以看到有很多种产品,这里我们需要的是Hadoop因此我们点击hadoop。
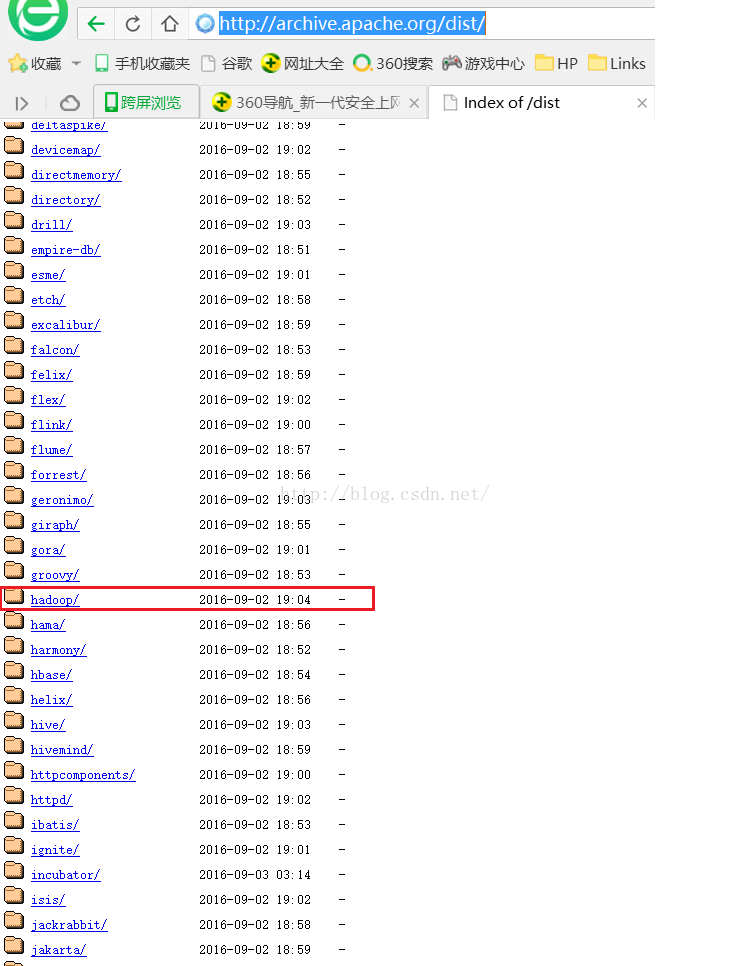
点击hadoop后会进入如下图所示的页面,我们点击core
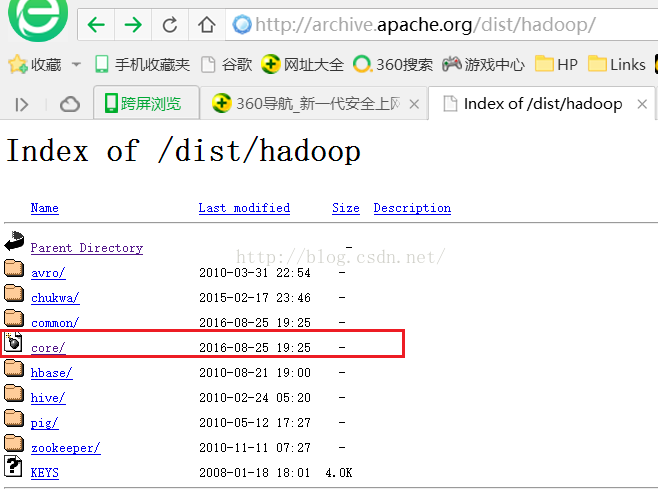
点击core后我们会进入如下图所示的界面,我学习用的是Hadoop2.2.0版本,当然大家也可以使用最新的稳定版本(点击stable)
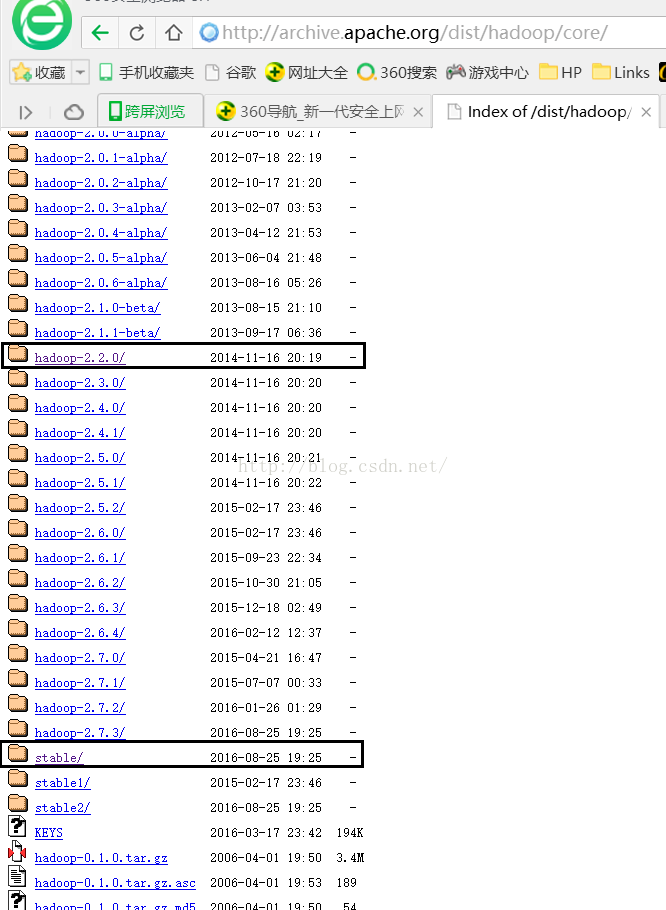
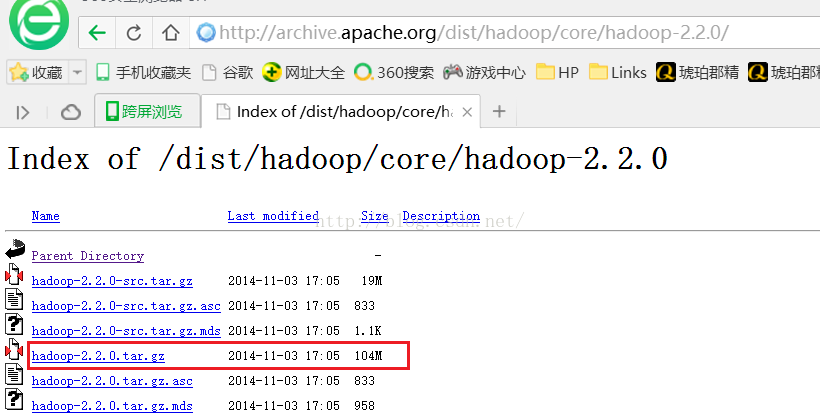
我们点击hadoop-2.2.0后会进入如下图所示的页面,我们点击hadoop-2.2.0.tar.gz进行下载。
下载完hadoop-2.2.0.tar.gz后,我们利用FileZilla工具将该安装包上传到root目录下(关于FileZilla的使用如果不会使用的话可以参考第二节课JDK的安装,网址是:http://blog.csdn.net/u012453843/article/details/52422736),如下图所示
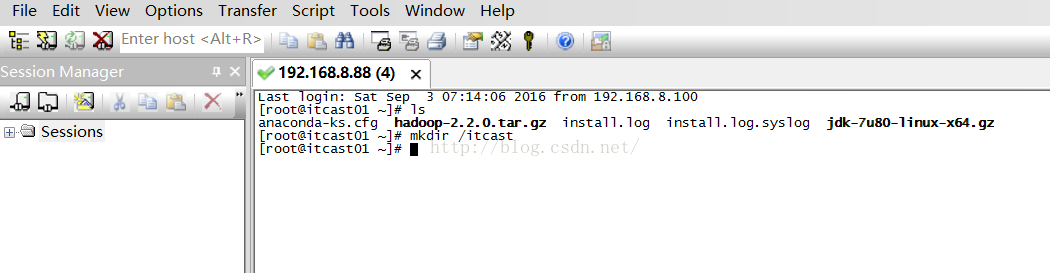
接下来我们在root目录下创建一个itcast目录,命令是mkdir /itcast,如下图所示
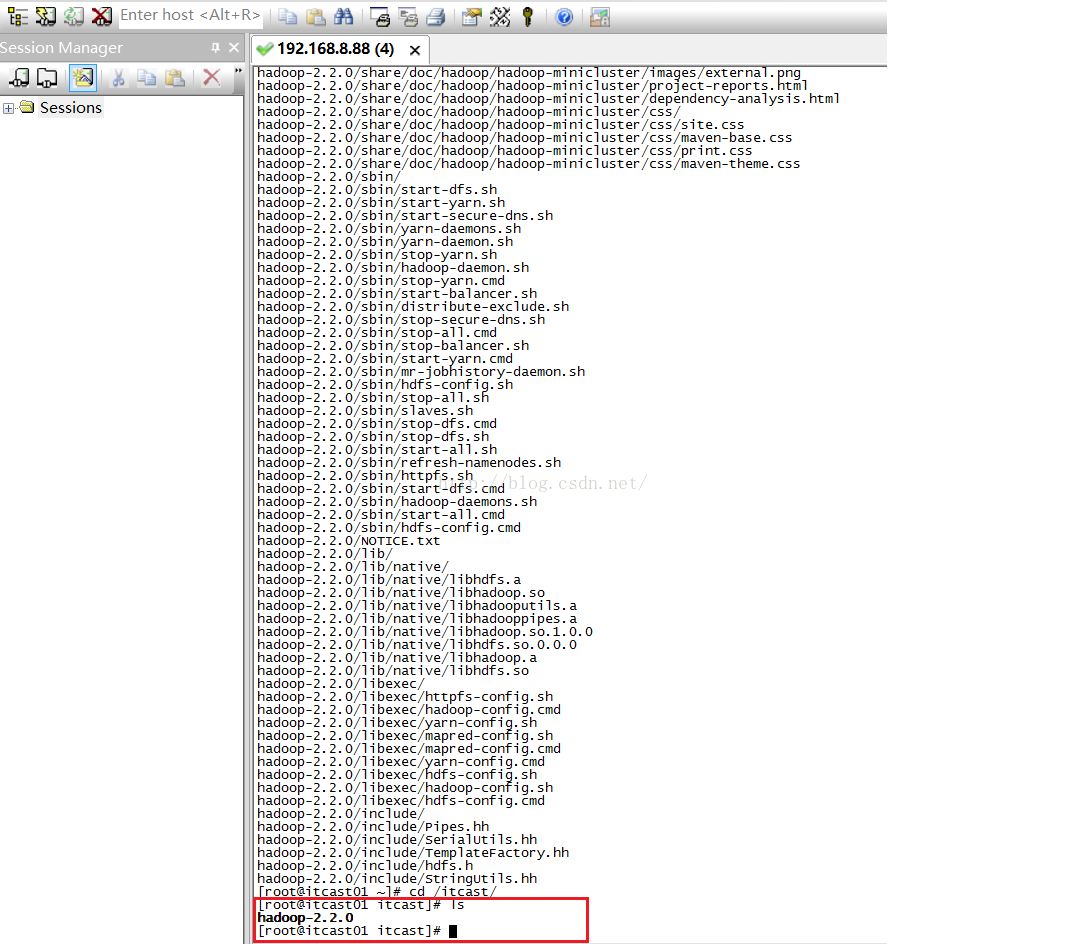
接下来我们解压hadoop-2.2.0.tar.gz,我们使用的命令是tar -zxvf hadoop-2.2.0.tar.gz -C /itcast/,这里我们说明一下这条命令的含义,tar的意思是打包和解包,-zxvf中的z是gzip类型的包,x是释放的意思(如果是c的话意思是创建),v代表解压过程的详情,f代表file的意思。解压完后我们进入itcast目录,命令:cd /itcast/ 按回车,然后我们输入ls命令查看目录下的文件,如下图所示,我们可以看到hadoop-2.2.0文件夹,说明加压成功。
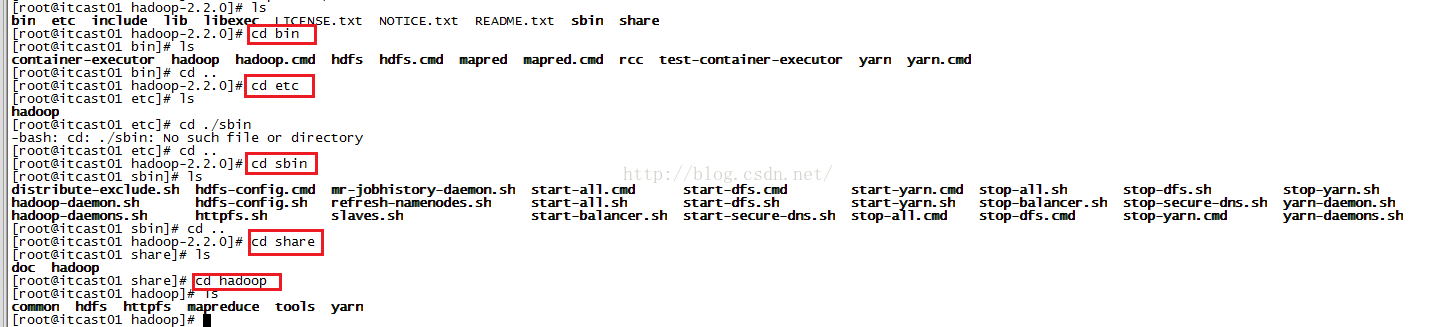
我们进入到hadoop-2.2.0文件夹,命令是:cd hadoop-2.2.0,按回车,接着我们用ls命令来查看hadoop-2.2.0下面有哪些文件夹,如下图所示,其中的bin文件夹中存放的是一些可执行的脚本(我们用到的比较多的是hadoop、hdfs、yarn),include存放的是本地库的一些头文件,sbin里面存放的是关于启动和停止相关的内容(如start-all.sh、start-dfs.sh、stop-all.sh、stop-dfs.sh等),etc存放的是hadoop的配置文件,这个etc跟linux根目录下的etc是不一样的,lib存放的是本地库的文件其所依赖的jar包在share目录下。
接下来我们开始修改5个配置文件了,首先我们进入hadoop的配置文件目录(如下图所示),我们可以看到有很多配置文件。

我们开始修改第一个配置文件hadoop-env.sh,我们输入命令vim hadoop-env.sh,按回车,我们可以看到该文件的内容,如下图所示,其中有一行是配置JAVA环境变量的,初始值默认是${JAVA_HOME},我们需要把它改成具体的jdk所在的目录。
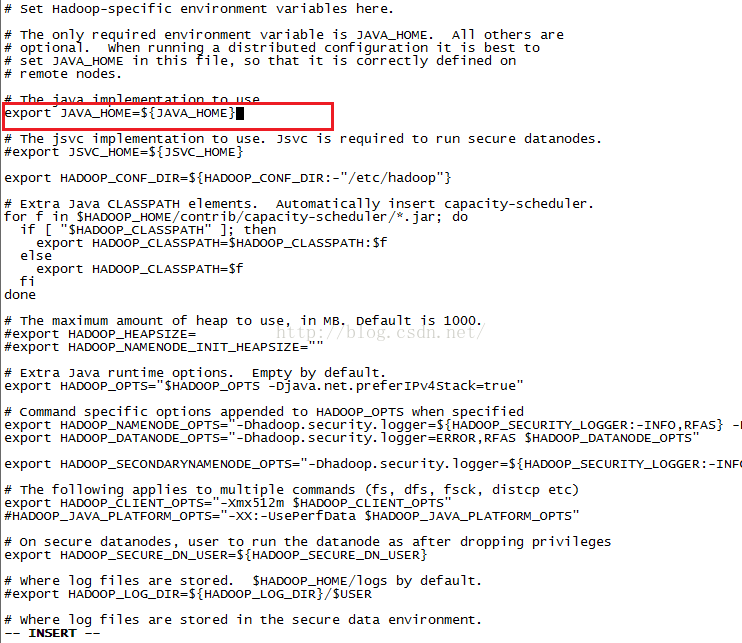
我们在修改文件的时候如果不知道Jdk文件的所在的位置,我们可以在当前页面进行查询(如果你当前不是出于INSERT状态,那么直接输入: echo $JAVA_HOME并按回车),如果当前出于INSERT状态,那么先按ESC键,然后输入: echo $JAVA_HOME并按回车,就会在页面底部出现Jdk所在的位置。
我们CTRL+C,复制一下内容。
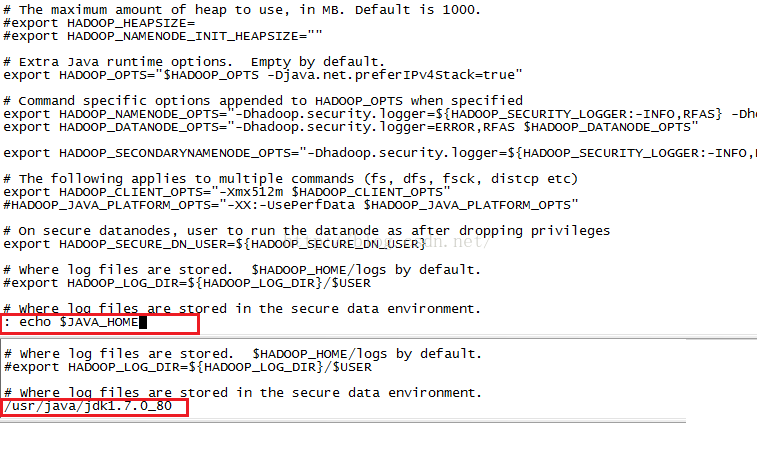
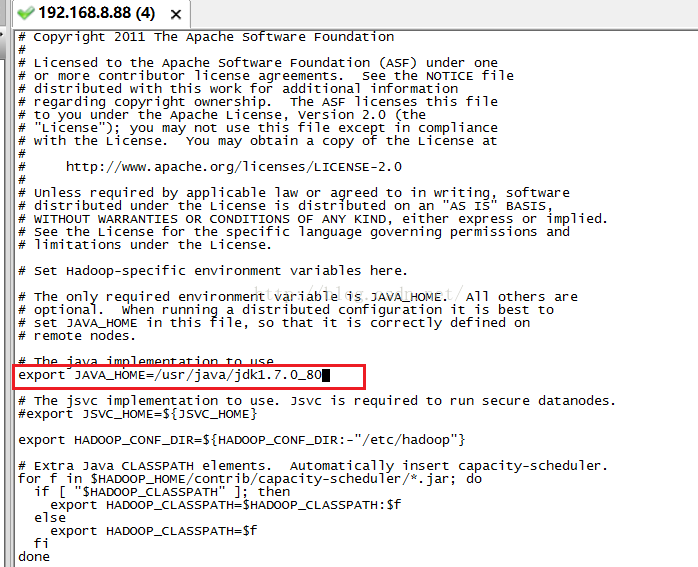
接下来我们按I键进入INSERT编辑模式,把刚才查询出的/usr/java/jdk1.7.0_80替换掉原来的${JAVA_HOME},如下图所示,接下来我们按ESC键退出编辑模式,然后输入:wq保存并退出编辑该文件。
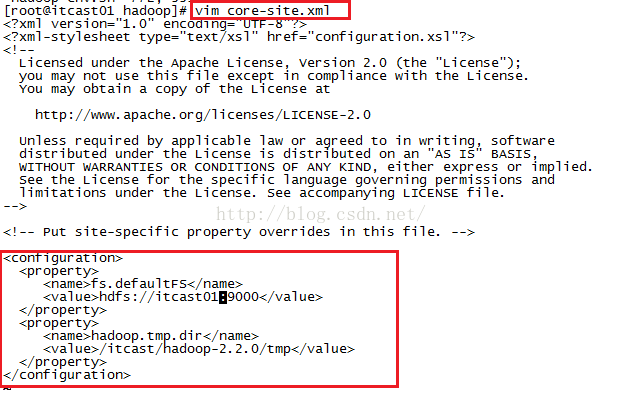
配置完了第一个文件,我们来配置第二个文件core-stie.xml,添加的内容在<configuration></configuration>当中,当我们输入目录时如果不太确定,依然可以采取如上面说的那样,在非编辑状态输入: cd /itcast/hadoop然后按tab键,会自动补全成/itcast/hadoop-2.2.0/,我们把这个目录粘到第二个property的value里面并增加一级目录tmp就是我们下图看到的/itcast/hadoop-2.2.0/tmp。需要说明的是,第一个property配置的是HDFS的NameNode的地址,第二个property配置的内容用来指定Hadoop运行时产生的文件的存放目录。添加完后按ESC键退出编辑模式,输入:wq保存并退出当前配置页面。
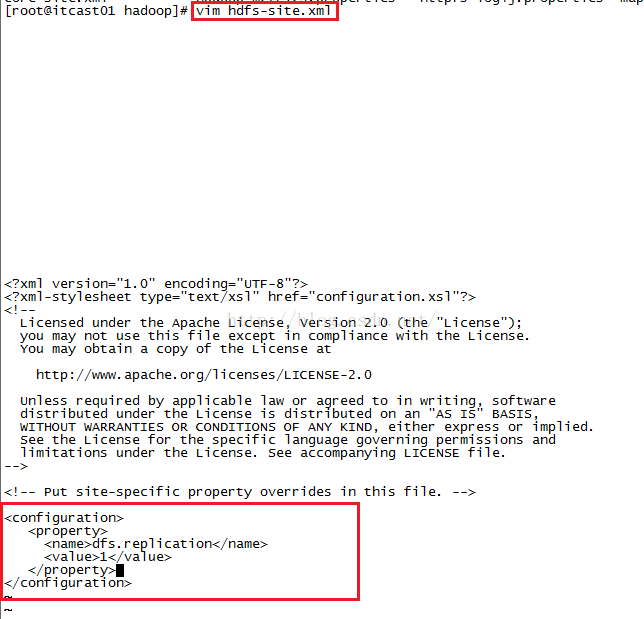
接下来我们配置第三个配置文件,该配置文件用来指定HDFS保存数据副本的数量(现在是伪分布式,所以数量是1,将来的集群副本数量默认是3)
输入完毕后按ESC键退出编辑模式,然后输入:wq保存并退出当前文件。
接下来我们配置第四个文件,即:mapred-site.xml,我们在hadoop目录下发现文件列表中只有mapred-site.xml.template而没有mapred-site.xml,因此我们需要先把mapred-site.xml.template的后缀.template去掉(即重命名)

重命名输入命令:mv mapred-site.xml.template mapred-site.xml并按回车即可完成修改,修改完后我们查看文件列表发现mapred-site.xml.template已经改成了mapred-site.xml。

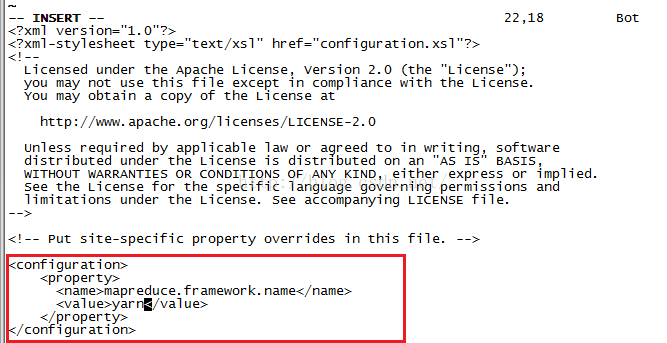
修改完文件名之后,我们开始修改mapred-site.xml,输入命令:vim mapred-site.xml并按回车会进入编辑页面,我们在<configuration></configuration>当中添加如下图所示的配置内容。该配置告诉Hadoop以后mapreduce(MR)运行在YARN上
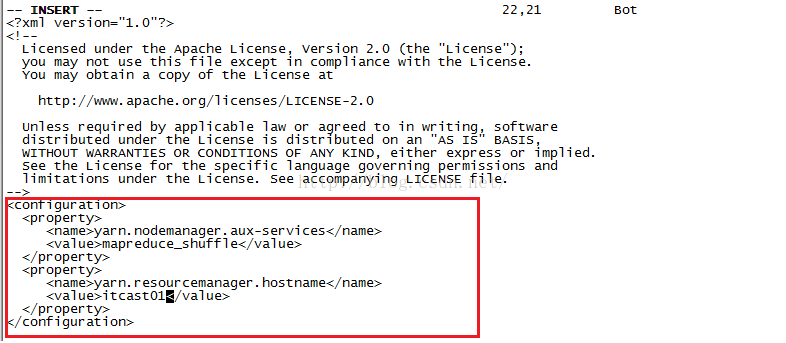
接下来我们来修改第5个配置文件 即:yarn-site.xml,输入命令vim yarn-site.xml并按回车进入该文件并按I键进入编辑模式,添加如下图所示的配置。需要说明的是,第一个property配置的内容是NodeManager获取数据的方式shuffle,第二个property配置的内容是指定YARN的ResourceManager的地址。编辑完后按回车键退出编辑模式,并输入:wq保存并退出该文件。
至此,我们终于修改完五个配置文件了。