TSegNet:一种高效、准确的三维牙齿模型牙齿分割网络 TSegNet: An efficient and accurate tooth segmentation network on 3D dental model
摘要
牙模型的自动准确分割是计算机辅助牙科研究的基本任务。现有方法对正常牙模型的分割效果满意;然而,他们未能强有力地处理具有挑战性的临床病例,如牙齿模型缺失,拥挤,或牙齿错位前正畸治疗。在本文中,我们提出了一种新的基于端到端学习的方法,称为TSegNet,用于对牙齿模型的三维扫描点云数据进行鲁棒和高效的牙齿分割。我们的算法在第一阶段采用距离感知的牙齿质心投票方案来检测所有的牙齿,保证了即使在异常牙齿模型上位置不规则的牙齿物体也能准确定位。然后,设计第二阶段的置信度级联分割模块,对每个牙齿进行分割,并解决上述挑战性案例造成的歧义。我们在一个由正畸治疗前后扫描的牙齿模型组成的大规模真实数据集上评估了我们的方法。广泛的评估,消融研究和比较表明,我们的方法可以在各种具有挑战性的情况下稳健地生成准确的牙齿标签,并且在准确性方面显著优于最先进的方法,Dice系数为6.5%,F1分数为3.0%,同时计算时间提速了20倍。
端到端学习:。。。
Dice系数:。。。
F1 Score:。。。
介绍
计算机辅助设计(CAD)已广泛应用于口腔正畸的诊断、修复和治疗计划。牙科CAD系统需要牙科模型作为输入,以协助牙医在治疗过程中删除、拔出或重新排列牙齿。在这方面,分割不同图像模式的三维牙齿模型,如CBCT图像和牙齿模型,这是非常重要的。由于牙科模型扫描仪不受x射线辐射,与使用三维体积表示的CBCT相比,它们被广泛用于获得表面表示的牙冠形状的高精度牙科模型。由于人工从牙齿模型中标记牙齿非常费力,因此开发自动准确的牙齿模型三维分割方法引起了人们的极大关注。
以下原因可能导致齿形变化,使分割容易出错
- 一些患者会出现牙齿拥挤、缺失和错位等复杂的异常问题。相邻的牙齿通常是不规则的,很难分开。
- 牙齿和牙龈之间的边界没有明显的形状变化,这给基于几何特征的分割方法带来了困难
- 牙科模型可能有模型制作过程中的人工制品或患者佩戴的牙套
为了解决这些问题之前的人做的工作有:
- 利用手工制作的几何特征进行牙齿模型分割(表面曲率,测地信息和谐波场)。这些方法通常依赖于特定领域的知识,缺乏表示复杂齿形外观所需的鲁棒性
- 采用CNN或者基于网格的图神经网络。这些方法大多有很强的限制性假设,即牙齿模型是由一套完整的天然牙齿组成的,这很难得到满足,鲁棒性差。Mask-MCNet将牙齿模型转换为点云数据,并使用基于体积锚定的区域建议网络进行牙齿检测和分割。但是,提案生成模块会导致解析扣除,并且需要大量的内存资源。
- 另一种深度学习方法,包括PointNet、PointNet++和PointCNN,直接以三维点云数据(如网格顶点)为输入,学习深度几何特征,对一般几何处理任务进行分类和分割。当这些方法应用于我们的牙齿分割任务时,一个主要的限制是很难准确地分离具有相似形状外观的相邻牙齿,如门牙、前磨牙和磨牙,特别是在缺牙的牙齿模型上分辨能力更差。
表面曲率、测地信息、和谐波场:。。。?
点云数据:点云是某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等,不一一列举。在我看来点云可以将现实世界原子化,通过高精度的点云数据可以还原现实世界。
门牙、前磨牙、磨牙:。。。
本文总结前人的经验教训后,提出了一个新的方法:一种基于端到端学习的3D牙齿模型自动分割方法,这种方法的核心是两阶段的神经网络
-
检测所有牙齿。不同于传统的利用边界框裁剪对象的方法,我们利用牙齿的质心(即质量中心)来识别每个牙齿对象,这是基于我们的观察,无论牙齿形状、位置和方向如何,质心点都是牙齿形状内部的稳定特征点。因此,它是一个比边界框(bounding box)更可靠的信号,特别是当牙齿相对较小且排列紧密时。这样,牙齿检测问题自然转化为牙齿质心预测问题。为了可靠地预测所有牙齿质心,我们设计了一种距离感知投票方案(distance-aware voting scheme 这个翻译感觉怪怪的),该方案通过可靠的学习局部上下文从下采样点生成牙齿质心。
-
对每个检测到的牙齿进行精准分割。我们首先在预测的牙齿质心的指导下裁剪出相应的点和特征,并将它们合并为一个牙齿建议。随后,所有的牙齿建议被发送到分割模块,以生成单个牙齿标签。此外,为了提高分割精度,特别是对于具有模糊信号的牙齿边界,我们引入了基于级联网络的逐点置信度图,通过注意机制增强标签学习。新提出的新成分和损失函数有效地产生了准确的牙齿分割,并提高了我们的算法在实际临床场景中的可用性
边界框bounding box:。。。
本文的主要贡献
- 我们提出了一种新的管道,将牙齿模型分割作为两个子问题:鲁棒的牙齿质心预测和准确的单个牙齿在点云数据上的分割。
- 我们设计了一种距离感知投票方案,以有效地预测所有牙齿质心。此外,引入了自信感知注意机制,提高了噪声区域的分割效果。
- 对从牙科诊所收集的数据集进行了广泛的评估和消融研究。与最先进的方法相比,所提出的框架在定性和定量上都取得了显著的优势。
相关工作
牙模型分割
- 许多传统的方法都是基于手工制作的几何特征来分割牙齿三维模型。这些方法大致可分为三类:基于曲面曲率的方法、基于曲面等高线(轮廓线)的方法和基于谐波场的方法。但是要么预处理太复杂要么过程太复杂,总之不太行
- 另一组旨在有效分割3D牙齿模型的方法是基于2D图像的。不幸的是,当牙模型有严重的错牙合时,这些方法往往失败。
- 近年来,随着深度学习技术的发展,许多研究利用二维图像、网格和点云上的神经网络从牙齿模型中提取牙齿。然而,由于这些方法通常将点或面部分组到预定义的集群中,因此它们通常无法处理缺失牙齿的数据,这在现实世界的临床场景中很常见。
三维点云学习
三维理解是计算机视觉中的一项重要任务。目前最先进的方法是将各种三维数据作为输入来执行三维形状分割、检测和分类等任务。在输入数据中,三维点云表示由于其灵活性和存储效率而越来越受欢迎。
方法
我们提出了一种新的基于三维牙齿模型的牙齿分割框架(见下图)。我们的方法将从输入牙齿模型中提取的三维点云作为输入,目的是为每个点分配一个唯一的标签。具体来说,我们首先介绍了距离感知齿形质心预测模块,该模块为齿形质心生成一组候选点(第一部分)。然后,我们提出了一种置信度感知的注意机制,通过预测的牙齿质心来分割每个牙齿(第二部分)。在测试阶段,我们利用牙齿质心聚类算法来加快分割速度,并直接将点云标签传输回牙齿模型(第三部分)。
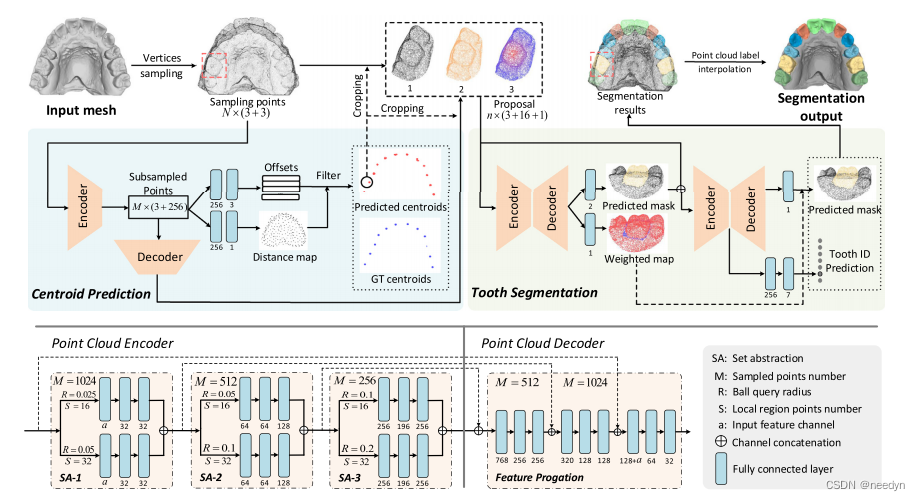
Distance-aware tooth centroid prediction(距离感知齿心预测)
为了正确识别牙齿目标,给定一个输入牙齿模型,首先提取网格顶点并均匀的下采样以获得维度为N×6的输入点云P(其中N是16000为采样的输入点的数量;每个点由6维向量描述,除了三维坐标外,还从牙齿网络中获取每个点的法向量作为附加特征来提供辅助信息)
有了输入点云P后,首先在一个单位球内对其进行归一化,并利用PointNet++作为骨干编码器提取几何特征(编码器包括三个多次感知器MLP块、一个批处理归一化层和一个ReLU非线性层)。骨干编码器的输出是一组下采样点F,其维数为M×(3+256)(其中M=256为下采样点的个数)对于每一个点,除了3D坐标外,还有一个256-D特征编码其周围的本地上下文信息。
对于上颌或下颌牙齿模型,有真实的牙齿质心集C={c1,c2,…,ck},为了能够使用学习到的局部特征从下采样点F预测所有的牙齿质心。设计了一个位移函数来学习每个下采样点和其对应的质心ci的偏移量,具体来说就是MLP将学习到的局部特征的下采样点F作为输入,输出一组M位移向量▲C={(▲xi,▲yi,▲zi)},最后生成回归的质心点集合C={(xi+▲xi,yi+▲yi,zi+▲zi)}(i∈[1,M])来近似ground truth C(其中(xi,yi,zi)表示第i次抽样点Fi的三维坐标)。
如果一个下采样点出现在牙齿附近,捕获牙齿形状的编码特征有能力预测附近牙齿的质心,但是由于下采样点F是通过最远采样操作从输入点云中均匀采样的,因此我们观察到的一些下采样点可能远离任何牙齿,这些点能反映的信息很少,无法预测可靠的牙齿之心。为了自动过滤这些点,我们用另一个距离估计分支来回归每个子采样点的距离值,测量点与其最近的ground truth质心的接近程度。首先测量每个下采样点与其最近的牙齿质心之间的距离,并将其设置为距离估计的基础真值。然后利用平滑L1损失计算回归误差,距离估计的损失函数定义为:

其中
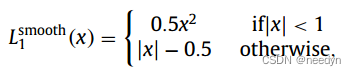
其中f(3)表示下采样点F的三维坐标,di为下采样点Fi到最近的齿质心的预测距离值,使用距离估计模块,在训练和测试阶段过滤具有相对较大预测距离的子采样点。将归一化点集的阈值α设置为0.2,与编码器中最后一个集合抽象层的接受域一致。
在质心预测分支中,通过最小化回归质心集ˆC与ground truth集C之间的距离来训练网络,考虑以下两个因素:
- C中每个质心至少对应于ˆC中的一个回归质心(抛射函数)
- 每个ˆC质心应与C中的一个质心精确对应
这是一种双向距离最小化方法,我们使用倒角距离来监督质心的预测,两组质心的损失函数表示为(距离估计项α=0.2)
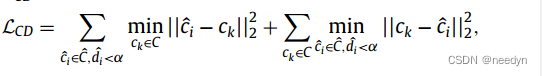
基于距离估计和倒角距离监督的质心预测方法已经取得了不错的效果,但是仍观察到一些预测的质心位于相邻的两颗牙齿之间的边界附近,特别是下颌门牙,相对较小且排列紧密。这是因为这些模糊的质心很少受到倒角距离损失的惩罚,为了解决这个问题,我们添加了一个分离损失如下(▲d1、▲d2分别表示预测的牙齿质心到C中第一个和第二个最近的质心的距离),这一项鼓励每个预测的质心尽可能接近C中正确对应的齿形质心。

最后将三个损失项组合得到鲁棒质心点预测的训练损失函数如下(β为平衡权值,所有实验均设为0.1)
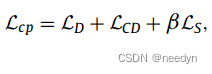
PointNet++:。。。。。
gound truth(简单来说就是真实数据):它是指相对于新的测量方式得到的测量值,作为基准的,由已有的、可靠的测量方式得到的测量值(即经验证据)。人们往往会利用基准真相,对新的测量方式进行校准,以降低新测量方式的误差和提高新测量方式的准确性。机器学习领域借用了这一概念。使用训练所得模型对样本进行推理的过程,可以当做是一种广义上的测量行为。因此,在有监督学习中,ground truth 通常指代样本集中的标签。
倒角距离:
Confidence-aware tooth segmentation(置信度感知牙齿分割)
接下来使用准确预测的质心作为指导信息进行单个牙齿分割。
因为每个牙齿至少有一个预测的质心,我们首先根据预测的质心生成牙齿建议。我们没有使用边界框来裁剪牙齿对象,而是基于到预测牙齿质心的欧几里得距离来裁剪输入点云数据中最近的n=4096个点,这大约是输入牙齿模型16000个点的四分之一,并且确保在建议中包含完整的牙齿。如上面的模型图中最上面一行红色虚线框所示,牙齿建议(tooth proposal)由三个组成部分表示:
- 裁剪点坐标(3-Dims)
- 裁剪点传播特征(32-Dims)
- 密集距离场df(i)(1-Dims)
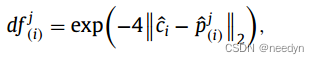
其中ˆci为方案i的预测质心,ˆpj(i)为裁剪点中点j的三维坐标。通过提出距离场,预测质心对应的前景齿相对于裁剪点中的其他齿具有更高的值,作为分割子网络的引导图。
最后直接将三个单独的特征拼接到分割网络中进行前景齿形的分割。置信度感知级联分割基于PointNet++构建的分割网络,以n×(3+32+1)维的级联特征作为输入,输出属于齿形或背景的每个点的二值标记。
尽管PointNet++在点云分割方面表现出色,但由于牙齿边界附近的几何信号模糊以及牙齿形状变化较大,很难将牙齿形状与周围牙龈清晰地分离。因此,我们首先使用级联分割方案设计网络,其中包含两个分割子网络S1和S2。S2的级联方案将提议特征和S1的一维分割结果同时作为输入。此外,为了进一步提高复杂齿形边界附近的分割精度,我们提出了一种新的置信度感知的牙齿分割注意机制,具体如下: - 在S1中,除了预测建议的分割结果外,还引入另一个分支来估计点向置信值λ(point-wise confidence value),测量分割的精度。

其中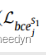 表示预测的点标签和基本真值标签之间的点向二进制交叉熵损失(BCE),λ以无监督的方式进行训练,以测量预测标签的模糊性。也就是说,该值越高,预测结果越准确。图2(权重图)给出了逐点置信度图的可视化说明。显然,几何信号模糊的边界区域往往具有较低的置信值。
表示预测的点标签和基本真值标签之间的点向二进制交叉熵损失(BCE),λ以无监督的方式进行训练,以测量预测标签的模糊性。也就是说,该值越高,预测结果越准确。图2(权重图)给出了逐点置信度图的可视化说明。显然,几何信号模糊的边界区域往往具有较低的置信值。 - 在第二个分割子网络S2中,我们将置信图转换为归一化权值图,强调分割S2中λ较低的区域,如边界区域。训练损失如下
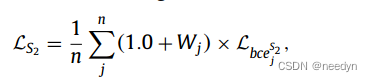
其中Wj=1.0-λj为加权图上逐点的值, 为S2中逐点的BCE损失。
为S2中逐点的BCE损失。
此外,为了识别每个提案中的前景齿ID,我们利用S2中提取的全局特征进行分类,并计算交叉熵损失LID来监督任务。最后,我们使用损失函数训练级联分割网络
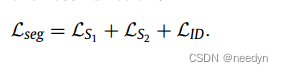
欧几里得距离:http://t.csdnimg.cn/j9KeB
距离场:。。。。
前景齿形:。。。。
向量范数:http://t.csdnimg.cn/4ONdd
交叉熵损失:。。。。。。
级联分割:。。。

Centroid clustering and label prediction(质心聚类和标签预测)
在上一步中,预测的牙齿质心呈现出如图4、5、8所示的聚类趋势。为了去除冗余的齿形质心,加快处理速度,在训练和测试阶段,我们首先对所有由距离阈值l控制的预测质心应用DBSCAN聚类算法,这里经验地将l设置为0.015,与归一化点云数据中的齿形尺寸相比,这个值相对较小。对于每个聚类,我们计算出具有代表性的平均质心点,并给出相应的分割建议。
在测试阶段,在对生成的建议进行单个牙齿提取之后,下一步是为输入的点云数据生成标签。为此,我们首先计算两种方案的前景点重叠。如果IoU (Intersection / Union)大于阈值0.35,则认为两个提案包含相同的牙齿。在这种情况下,我们平均逐点标记概率来融合重叠点。
最后,通过三线性插值将点云标记直接传递回牙体表面。
在实现中,我们先训练500个epoch的质心预测网络,然后连接单齿分割网络,共同训练100个epoch的框架。我们使用Adam,固定学习率为1 × 10−3。一般使用一块Nvidia GeForce 1080Ti GPU,质心预测网络训练时间约为4小时,联合训练时间约为18小时。
三线性差值:。。。
前景点重叠:。。。
实验与结果
我们在从现实世界诊所收集的数据集上评估我们的算法,包括上颌和下颚。牙齿识别基于牙齿符号系统(ISO3950) (Grace, 2000),这与我们分割结果的颜色编码是一致的。本节中用于评估的牙齿子群,即门牙、犬牙、前磨牙、磨牙,也按照下图中标注的类型进行设置。所有实验均在Intel® Xeon® V4 1.9 GHz CPU、1080Ti GPU和32gb RAM的计算机上进行。
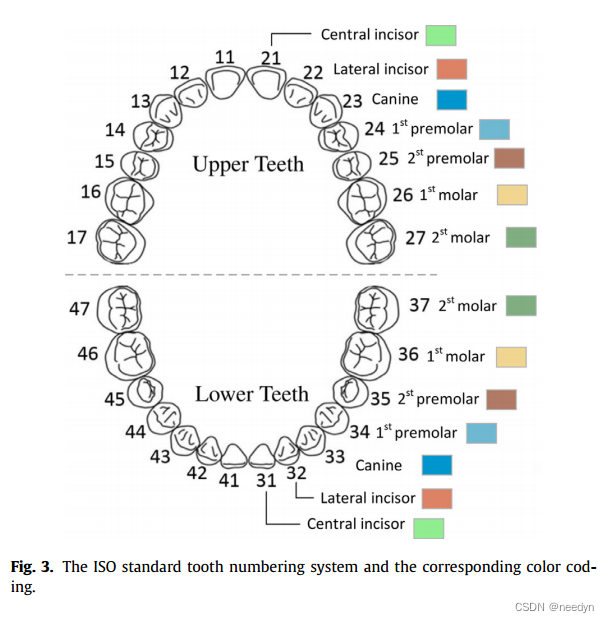
牙齿符号系统(ISO3950) :…
牙齿的名称:

DSC(Dice。。。。):
数据集和评估指标
为了训练网络,我们收集了一些患者在正畸治疗前后的牙齿模型,其中包括许多牙齿形状异常的病例,如牙齿拥挤,牙齿缺失和额外的牙套。该数据集共包含2000个牙齿模型(1000个上颌骨和1000个下颌骨),其中每个牙齿表面包含大约150,000个面和80,000个顶点。
为了训练网络,我们将其随机分成三个子集,1500个模型用于训练,100个模型用于验证,400个模型用于测试。为了获得ground truth,我们手动标注了牙齿级别的标签,并根据标记的掩模计算每个牙齿的质心。为了定量评价我们的方法的性能,我们使用平均距离(MeanD)和最大距离(MaxD)度量来验证齿心预测的性能,定义为
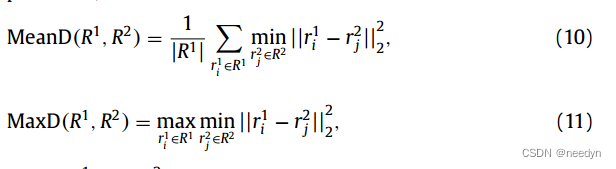
其中R1和R2代表两个点集。这两个度量分别由预测的牙齿质心集和ground truth的牙齿质心集双向计算。对于分割任务,我们使用DSC度量分别在点云和牙齿表面上进行验证,其计算为
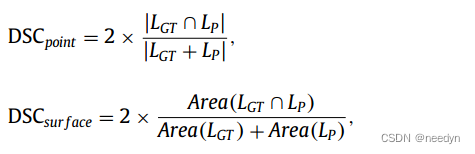
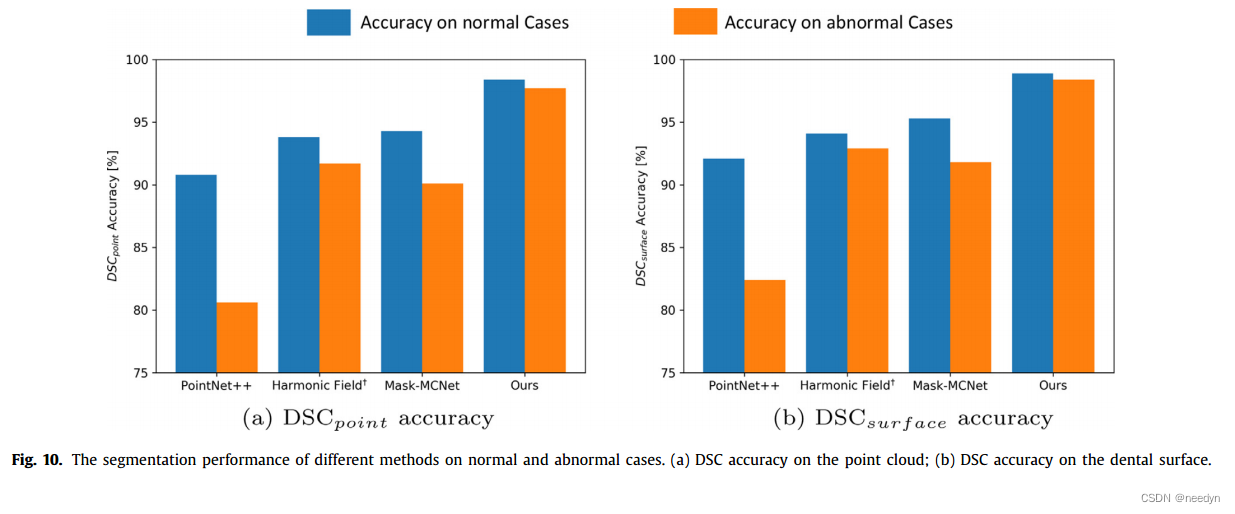
其中LGT和LP分别表示groundTruth标签,以及对应的预测标签。请注意,牙齿表面的DSC是以面面积加权的方式计算的。此外,使用宏观F1-score (F1)来衡量牙齿识别精度。在接下来的定量结果中,除了下图,我们报告了在测试子集上计算的平均值
关键部分的消融实验
为了证明我们的网络组件和损失函数的有效性,为牙齿质心预测和单个牙齿分割任务构建基线网络,分别记作bNetcp和bNetseg。对于bNetcp直接监督所有下采样点平移到最近的齿形质心;而bNetseg是单一的PointNet++分割模块,没有置信度感知级联机制。最后得到结论(见下表),我们的模型中质心预测部分没有一个冗余部分,全都有用
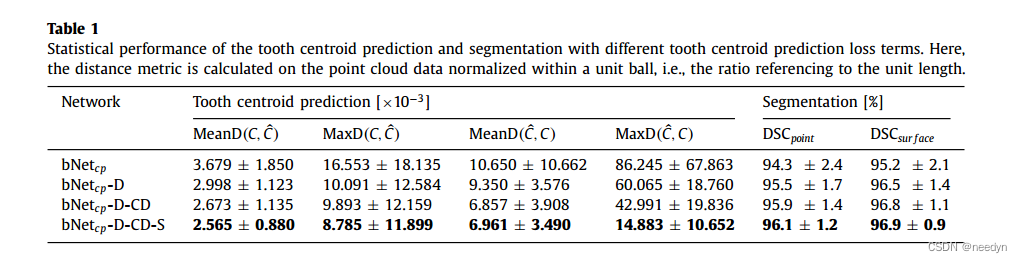
其中三四行的意思分别是:为了监督牙齿质心的预测,我们利用倒角距离来计算双向距离(bNetcp-D-CD);为了验证分离损失在准确牙形预测中的有效性,特别是对于拥挤和堆积在一起的门牙,我们探索了通过增加bNetcp-D-CD和分离损失的替代损失组合,表示为bNetcp-D-CD-s
然后检验牙齿分割部分有无冗余。最后得到结论(见下表),没有一点多余的。
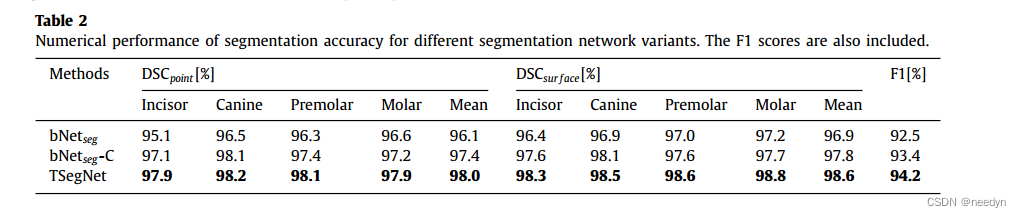
本部分实验使用bNetcp-C-CD-S作为齿心预测网络,并使用另一子模块增强基本分割网络(bNetseg)来完善初步结果(表示为bNetseg-C)。为了验证置信度感知级联机制的有效性,我们进一步用置信度图作为最终网络(TSegNet)对bNetseg-C进行增强。
最终得出定性结果,TSegNet能够产生更可靠的无伪影分割结果。
与最先进的方法比较
与PointNet+、Harmonic Field†、Mask-MCNet相比,我们的方法鲁棒性强,精度高,速度快,端到端无需人为操作。
讨论
讲了一些参数和方法的选择过程;讲到算法存在的局限性:有时候会产生不完整的牙齿分割结果,具体来说主要有这两种情况:(a)智齿形状异常,未能检出。(b)初生牙牙冠面积小,难以准确分割。导致这个结果的一个可能的原因是情况相对罕见,在训练阶段很少被网络看到。具体来说,智齿是人类的一个特例,因为它有很大的变化。
结论
在这项工作中,我们开发了一种新的全自动算法,以牙齿质心信息为指导,在三维牙齿模型上分割牙齿。该算法建立在一个两阶段神经网络的基础上,该网络包含一个鲁棒的牙齿质心预测子网络和一个单一的牙齿分割子网络,并具有新颖的分量和损失函数。我们对我们的算法进行了定性和定量的评估,并将其与最先进的基于学习和非学习的方法进行了比较,其中我们的方法产生了更好的结果,并且明显优于其他方法。