论文发表在 IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS期刊上,其工程技术方向为SCI 2区,计算机方向为SCI 1区。
1 本文主要贡献
a. 提出了一个将Unet和SqueezeNet结合的网络结构,实现瞳孔虹膜的分割以及闭眼检测。
b. 将瞳孔虹膜的分割以及闭眼检测融合到一个3D视线检测的框架中,仅仅基于一个单目RGB摄像头就可以实现实时三维视线估计。
两个重要问题
(1) 这个3D视线检测框架是什么?
(2) 怎么将瞳孔虹膜的分割结果融合到这个框架中?
带着这两个问题,我们继续阅读论文。
2 整体pipeline
这个图把整个处理流程展示得还算清晰,我们要从一帧输入的视频中提取到三维的脸部重构模型、瞳孔虹膜分割结果、边缘检测的结果,然后根据这些输出眼睛的视线状态、3D头部姿态以及脸部的表情。细究下去,这个pipeline里面用到了不少其它论文里面的方法。
问题
(1) 2D Feature Detection 用的什么方法?具体检测了几个点?
答:从论文中看,2D Feature Detection是用的论文《Learning deep representation for face alignment with auxiliary attributes》中的方法(具体的还我没有读这篇论文)。
(2) Optical Flow Computing具体是如何实现的?如何实现三维人脸重构?
答:从论文中看,生成Optical Flow是用的论文《Fast optical flow
using dense inverse search》中的方法(具体的还我没有读这篇论文),可以明确的是,Optical Flow的作用是用来让三维脸部重构得更加精准。三维人脸重构作者是采用了一个所谓数据驱动的三维脸部重构技术,具体的还没看懂。
3 2D脸部对准与3D脸部重构
这一部分感觉极其复杂,运用了许多其它论文中的方法,不作为我阅读的重点,总之最后得到了效果比较好的3D脸部重构模型。
这里放几张后面的效果图,感觉挺惊悚的感觉,就是等于把人脸戴上个面具。

4 瞳孔和虹膜分割
眼睛的运动分为三种:注视、眼跳和平滑移动。在眼跳发生时,现有的视线追踪方法都会产生较大的错误率,将每一帧进行分割然后再进行视线追踪,可以很好地增加鲁棒性。
对于瞳孔的检测,之前被看作是一种回归问题,输入眼部图像,通过某种方法来回归出瞳孔的位置。然而瞳孔和虹膜经常会被眼睑遮挡,这回导致回归定位不准确。把瞳孔检测看成一个对每个像素进行分类的问题,会很好地增加瞳孔检测的鲁棒性。
4.1 眼部图像校准

图(a)是输入的测试图像,校准的目的就是生成图(c)这样的眼睛相对整幅图像比较正的一个图像,实现这个过程要依赖于(b)这个平均模板,从(a)到(b)做一个相似性变换就得到了(c),这个相似性变换具体怎么实现文中并未提及,感觉就是让(a)中的眼睑特征点尽可能的靠近(b)中特征点的分布,图像就被校准了。对于右眼图像,由于人眼的对称性,先对右眼进行镜像翻转,然后再对其进行校准。
整个的测试过程中,如果输入的是右眼的图像,图像会先被镜像 翻转然后 进行特征点配准,接着输入训练好的网络中,一方面生成瞳孔虹膜的分割结果,另一方面生成闭眼检测的结果。最后对其进行反变换将最后得到的结果进行配准的反变换变换的原来的图像空间中。
个人感觉这步对眼睛的配准没有啥作用,用U型网络的框架直接对原图进行分割和闭眼检测处理,应该也能得到比较好的结果。
4.2 瞳孔虹膜分割
进行分割的网络结构如下图所示:

这个网络输入的就是刚才进行校准的眼部图像,网络中间输出闭眼检测的结果,最后输出分割结果。实现了闭眼检测和分割两种功能。
其中为了能够更好地实现实时性,作者设计了一个Fire模块,通过将两种卷积核提取到的特征进行级联来作为最后提取的特征,这个模块简单到只有两层卷积,参数量很小,使得整体的参数量由原来Unet中的500k减小为50k,浮点运算也由132.53M减小为5.81M。Eye close仅仅是使用简单的全连接网络,具体用了几层似乎原文并未提及。在解码部分采用反卷积进行上采样,所有的层中都使用了ReLU激活函数。
在训练网络时,才用的损失函数包括两部分:闭眼检测损失和分割损失。这两种损失都可以看做二分类问题,所以作者采用的是交叉熵函数是以下面这个表达式来组合的。
总的损失=2*分割损失+50*闭眼检测损失
实际上,为了防止过拟合,作者还增加了L2正则项,正则项系数就位Weight decay 1e-7.
分割结果展示与对比:

5 三维视线追踪
在三维视线追踪方法上,本文借鉴了在2016年同样发表再这个期刊上的另一篇论文论文《Realtime 3d eye gaze animation using a single rgb camera》,整体的方法仅仅在分割损失项和自动标注上有所不同。
在获取头部姿态和分割结果之后,我们需要标定眼球中心的位置(根据头部姿态)以及虹膜的半径(根据分割结果)。
作者在最大后验概率框架下研究这个问题,并且采用基于搜索全局最优解的采样方法。(这句话不是很理解,什么是MAP?什么又是Sampling based algorithm to search for the global optimal solution of the problem?)
根据本文借鉴的那篇论文,本文使用V来表示眼睛视线的状态,V的表达式如下:
V = { P x , P y , P z , s , θ , ϕ } V=\{P_x,P_y,P_z,s,\theta,\phi\} V={
Px,Py,Pz,s,θ,ϕ}
其中, P x , P y , P z P_x,P_y,P_z Px,Py,Pz表示在脸部模型上人眼中心的三维坐标, s s s表示虹膜瞳孔区域的半径, θ , ϕ \theta,\phi θ,ϕ表示虹膜中心在眼球上的极坐标(以眼球为极坐标系的虹膜中心的坐标)。 θ , ϕ \theta,\phi θ,ϕ在同一个视频的每一帧都会更新,令我有点疑惑的是原文说 P x , P y , P z P_x,P_y,P_z Px,Py,Pz和 s s s同一个视频中不改变,不过实际场景下也就是如此,同一个人的虹膜半径以及眼睛在脸上的位置是固定的,变化的只有视线方向,虹膜中心与眼球中心相连接就可以代表视线方向,所以虹膜中心在眼球上的极坐标每帧都在发生变化。
5.1 自动眼球校准(标定)
在视线追踪开始前,我们需要标定 P x , P y , P z , s P_x, P_y,P_z,s Px,Py,Pz,s。在被测者进入相机视野中以后,我们就开始重构头部姿态和人脸,将被测者人脸正对相机的一帧选做标定帧。判断人脸正对相机需要获取两个向量:相机方向和人脸方向,在相机方向和人脸方向的夹角的余弦值大于0.98时,就判定为人脸正对相机,作为标定帧。对于闭眼的判断,需要依靠三个距离来判断:
d e y e l i d , d c o r n e r , d c e n t e r d_{eyelid},d_{corner},d_{center} deyelid,dcorner,dcenter
d e y e l i d d_{eyelid} deyelid表示上下眼睑的距离(根据特征点来计算), d c o r n e r d_{corner} dcorner表示左右眼角的距离(应该也是根据特征点来计算), d c e n t e r d_{center} dcenter最难理解,是表示分割结果的虹膜均值移位中心与眼睑上的二维特征点的距离,感觉这个大概就是一半上下眼睑的距离吧,判定规则为只要: d e y e l i d > α ∗ d c o r n e r , d c e n t e r > β ∗ d c o r n e r d_{eyelid}>\alpha*d_{corner},d_{center}>\beta*d_{corner} deyelid>α∗dcorner,dcenter>β∗dcorner
(其中 α = 0.22 , β = 0.1 \alpha=0.22, \beta=0.1 α=0.22,β=0.1)
就判定为没有闭眼,否则为闭眼.
在选定标定帧后,通过将2D分割结果的均值移位中心和边缘像素反向投影到3D模型中,通过头部姿态来获取到虹膜的中心和半径(具体怎么实现的实在没太想明白)。眼球中心坐标的获取首先依赖于一个假设的已知条件,就是成年人眼的眼球一半半径为12.5mm,所以只需要在虹膜中心坐标上加一个向量(0,0,-12.5)就可以得到眼球中心的坐标。
这部分非常迷,竟然我之前的分割网络在中间直接就能进行闭眼检测,为啥还要引入这三个东西来检测?就算是为了先在标定的时候不使用深度网络,但是按照原文来说, d c e n t e r d_{center} dcenter也用到了分割结果,所以实在想不通这里的意义是什么。
5.2 三维视线跟踪
获得了眼球中心和虹膜半径之后,利用虹膜瞳孔的分割结果和虹膜半径就可以实现对视线的追踪,前文中提到的人眼视线状态V中,有着虹膜中心在眼球上的极坐标,应该求出这个极坐标也就求出了视线的方向,但令我疑惑的是,4.1中是先获得虹膜中心,然后利用虹膜中心获得眼球中心,是怎么获得视线的方向的?后来我想明白了,在标定帧中,虹膜中心和眼球中心应该是平齐的(或者说是看成平齐的),所以在虹膜中心的x轴方向减去眼球的半径就能得到眼球中心的坐标。在不是标准帧的情况下,虹膜中心和眼球中心不是平齐的,此时成的角度就是视线的方向。
依靠每一帧都进行预测视线对视线的跟踪存在两个问题:在扫视的时候会出现很大的错误;每帧提取虹膜的中心虽然稳定但是缺少时间连续性。为了解决这两个问题,作者将虹膜特征和时间先验结合到一个MAP框架中,并采用基于算法的采样方法来解决求导复杂的问题,简单来说就是作者引入了一个概率模型,优化这个模型求导复杂,所以又引入了基于算法的采样方法。这个概率模型的优化可以由下面这个表达式来表示:
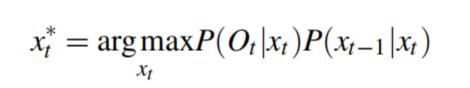
其中 x t 和 x t − 1 x_t和x_{t-1} xt和xt−1表示当前帧和下一帧的人眼状态, O t O_t Ot表示提取到的虹膜特征,我们的目标就是求是的后面两个条件概率表达式最大的 x t x_t xt, P ( O t ∣ x t ) P(O_t|x_t) P(Ot∣xt)表示 x t x_t xt 拟合提取到的虹膜特征拟合得有多好, P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt)表示 x t 和 x t − 1 x_t和x_{t-1} xt和xt−1满足的时间连续性有多好。 看到这又懵了,这两个P怎么求呢?第一个 P ( O t ∣ x t ) P(O_t|x_t) P(Ot∣xt)作者没有给出直接的表达式而是告诉我们它和这个东西成正比关系:
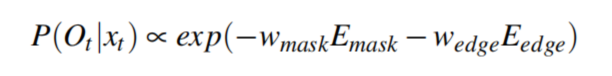
其中的两个 ω \omega ω分别取3和1,其中 E m a s k 和 E e d g e E_{mask}和E_{edge} Emask和Eedge分别表示瞳孔虹膜分割结果似然函数以及虹膜边缘似然函数。 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt)也是与一个表达式成正比,详见下面的动态似然函数内容。
简单介绍三种似然函数以及优化方法?
瞳孔虹膜掩膜似然函数
这个所谓的瞳孔虹膜掩膜似然函数前面所述的 E m a s k E_{mask} Emask,它度量了预测的mask与实际的mask的差异,这个求法很简单,就是用1减去IOU,如下:
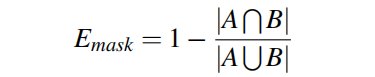
虹膜边缘似然函数
这个所谓的虹膜边缘似然函数前面所述的 E e d g e E_{edge} Eedge,它度量了预测虹膜的边缘和实际边缘的差异,利用Canny算子来提取原图的边缘,然后与预测的虹膜做一个所谓的trimmed chamfer distance,求完这个距离最后为了增加鲁棒性,还要再加一个K在后面,K=0.6*pixelnumber。这个所谓的trimmed chamfer distance到底怎么求?实在没看懂。
动态似然函数
这个所谓的动态似然函数前面所述的 P ( x t − 1 ∣ x t ) P(x_{t-1}|x_t) P(xt−1∣xt),它正比于下面的表达式:
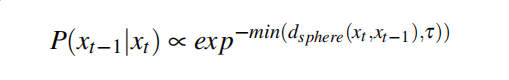
其中, d s p h e r e d_{sphere} dsphere两个人眼视线状态下极坐标的大圆距离(也就是眼球上这一状态下的虹膜中心到下一状态下的虹膜中心的距离)。这里有个阈值 τ \tau τ,它被设置为0.14rad(8度),由此可见,那个大圆距离也就是两次视线的角度差值,当每次视线变化的角度值小于8度时,就认为视线变化的是比较平坦的,也就是 x t 和 x t − 1 x_t和x_{t-1} xt和xt−1很好地满足的时间连续性。
至此,我们了解了三种似然函数,前面所述过的总的表达式如下:
对这个函数进行优化,就能求出最好的视线来,因为这个函数的导数非平凡的,所以我们才把每项用个正比的表达式来代替,就是我们前面讲的三种似然函数,也就是这种代替,好像就是作者所说的基于采样的算法。
6 评估和结果
在进行评估时,我们测试了从web摄像头获取得视频流和从互联网上下载下来的视频序列。在1080Ti上实现了实时处理,也在智能手机上进行了测试。在1080Ti上,3D人脸重建需要花费13ms,瞳孔虹膜分割需要2ms,视线估计需要3ms。
6.1 在真实数据上的测试
网络视频流的输入的图像尺寸时800x600,处理同时在结果上面直接显示瞳孔分割结果和闭眼的概率,不过从原文中给出的结果中并没有看出闭眼的概率的标记。
在IPhone8上也进行了测试,大概能达到14fps的速度,测试如下图所示:

6.2 与最好方法的比较
接着,作者和文献[1]以及文献[2]中的方法进行了比较,这些比较都是在下载好的视频序列上进行比较的。
与文献[1]比较
主要比较了三个方面:分割性能、参数量、视线追踪的准确度。
在分割性能上,本文提出的方法相比文献[1]中用到的随机森林方法,分割准确率更高,如下图所示:

(注:图中每个第一行是原图,第二行是本文的方法的分割结果,第三行是随机森林方法的分割结果。)
在参数量上,本文提出的方法由于使用了fire模块,整体的参数量仅有50k,而文献[1]中方法的整体参数量要达到百万级别。
在视线追踪的准确度上,为了方便比较,作者把瞳孔中心的三维坐标投影到二维平面上,为了获得ground truth,本文人工标注了标签数据的瞳孔中心,然后用下面的式子作为准确度:
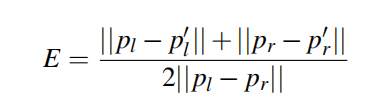
p l 和 p r p_l和p_r pl和pr表示左眼和右眼瞳孔中心的ground truth, p l ′ 和 p r ′ p_l ^{'}和p_r^{'} pl′和pr′表示瞳孔中心的预测值。说白了,这其实比较的就是瞳孔中心预测的准确率,比较结果如下图所示:

作者认为,之所以准确率高,还是因为使用DCNN分割的结果比随机森林的额分割结果要好。
与文献[2]比较
与文献[2]主要比较的就是算法的有效性,也就是视线追踪的准确性。为了得到三维视线标签,作者在一个数据集上人工标注了瞳孔中心,并且使用眼球的中心来重构出三维视线的方向。(关于这个眼球的中心究竟是如何获取得,我还是不太理解)比较的结果如下表:
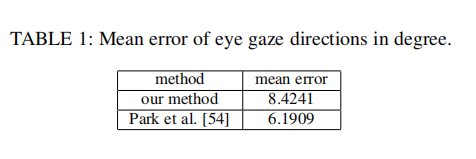
虽然本文的误差更大,不过作者说这在误差基本和方法[2]差不多的情况下还实现了实时性,所以要比它的方法强。
6.3 评估关键组成部分
评估三维人脸重构
在前述的人脸重构中,提到了一个Optical Flow Computing,整个重构人脸的方法不是本文的贡献,但是本文却增加了这个Optical Flow 的计算,通过增加这个,得到了重构性能的提高,评估结果如下表所示:

可见,增加了之后,重构的误差更小。
此外还展示了有无optical flow,translation在z轴上的分布比较(什么叫translation在z轴上的分布,我还不太明白),如下图所示:

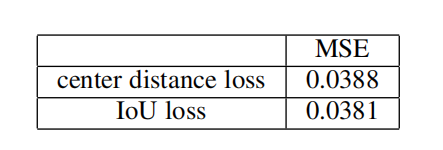
评估三维视线追踪
评估视线追踪性能时,其实评估的还是分割瞳孔和虹膜的准确率,因为分割结果对视线追踪结果十分重要。这里采用IOU和中心距离进行评估,评估结果如下表:
7 应用
这个可以直接应用在对人视线的捕捉,预测人眼注视屏幕上的位置。在实际应用时,要先用9个点进行校准,让人注视屏幕上9个点,同时追踪人的视线,最后采用最小二乘法来计算视线与注视点的线性关系,作者演示的图如下:

8 问题回顾与思考
至此,整篇论文读完了,让我们来回顾一下一开始我提出的两个问题,并来尝试解答一下这两个问题。
两个重要问题
(1) 这个3D视线检测框架是什么?
简单来说,这个框架就是首先进行人脸三维重构获得头部姿态,利用头部姿态来确定标定帧进行标定,然后通过DCNN获得瞳孔中心,最后转化为MAP问题,最终视线视线的追踪。
(2) 怎么将瞳孔虹膜的分割结果融合到这个框架中?
通过均值移位算法可以从瞳孔虹膜的分割结果中获得虹膜中心,然后利用虹膜中心和眼球中心以及虹膜的特征来对视线进行估计。总的来说分割只是为了获得瞳孔的中心,将瞳孔中心融合到这个框架中就可以进行视线追踪了。
思考与讨论
虽然有许多技术细节还是不能想明白,但是读完这篇论文还是有几点收获的:
(1)fire模块是否真的好用?能否用到我的项目中?
(2)能否获得分割结果之后,在不需要人脸重建的情况下直接获得视线方向?
9 参考文献
[1] C. Wang, S. Xia, and J. Chai, “Realtime 3d eye gaze animation using asingle rgb camera,” Acm Transactions on Graphics, vol. 35, no. 4, p. 118,2016.
[2]S. Park, A. Spurr, and O. Hilliges, “Deep pictorial gaze estimation,”european conference on computer vision, pp. 741–757, 2018.