文章目录
1. Precise Temporal Action Localization by Evolving Temporal Proposals
论文目的——拟解决问题
- 现有的动作定位方法在精确定位动作的开始和结束方面的表现不能令人满意
- 因为连续视频帧的变化是微小的。这可能会导致不稳定甚至不正确的边界回归,特别是在帧级粒度下。
- 从背景中判断一个动作的完整性是非常主观的。动作通常是复杂多样的,这使得我们很难从背景中分辨出动作片断。
贡献——创新
- 提出三阶段候选框生成网络ETP(Evolving Temporal Proposals),基于不同粒度的特征(unit-based feature和non-local pyramid feature),进行多阶段候选框回归,得到的动作边界较为精准。
- 利用unit-based的时空坐标回归到预选框的边界,来精确定位动作。
- 我们使用non-local pyramid feature对行动进行有效建模,这能够区分预选框的完整性和不完整性。
实现流程
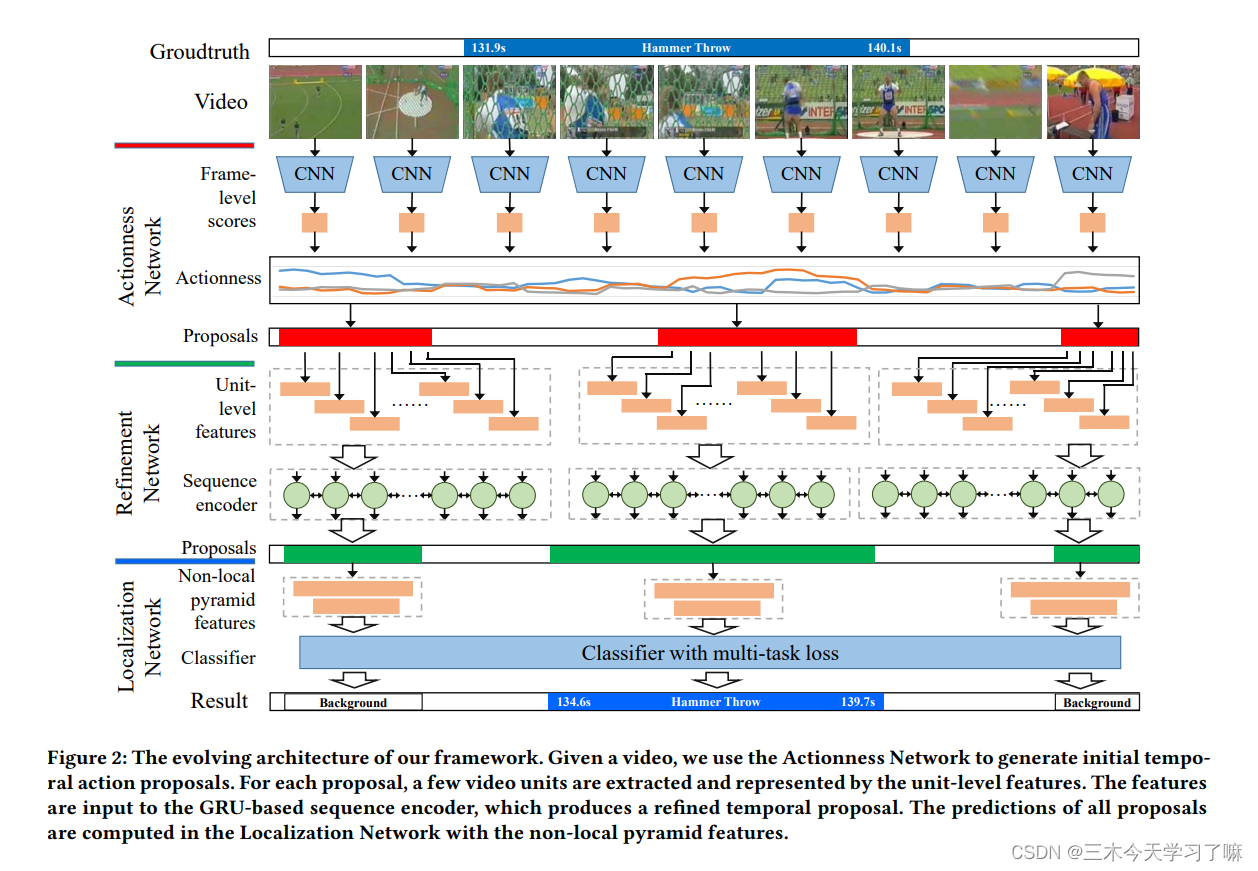
- 一阶段的Actionness Network通过帧级特征(frame-level feature)的得分生成初始候选框;
- 二阶段的Refinement Network在候选框内裁取unit,并用unit-level features来表示。这些特征被输入到基于GRU的序列编码器中,产生一个精确的候选框。
- 三阶段的Localization Network对二阶段候选框提取non-local特征,输出最终候选框及相应得分。
详细方法
-
Actionness Network: 得到当前帧包含动作的概率值frame-level class-specific actionness
先将视频的每一帧输入AN网络以计算frame-level score,得分用来生成初始的候选框。输入时长为T的视频,输出每帧图像在k类动作下分别的得分,共T*K个。

基本假设是,一个包含动作的片段应该由动作性得分高于阈值的帧组成。同时,动作片段的持续时间通常是有限的,因此使用了最小和最大的帧长度。考虑到这些分数,设计了一个连接组件方案来合并具有高分数的相邻区域(第14-32行)。在得到了每一帧的score后,通过聚类的方法,将离散的score组合,得到proposal,然后用非极大值抑制(NMS)剔除多余proposal(3-13行)。 -
Refinement Network: 基于RNN方法( Bi-GRU),利用上下文信息(context)对AN输出的候选框进行校正。
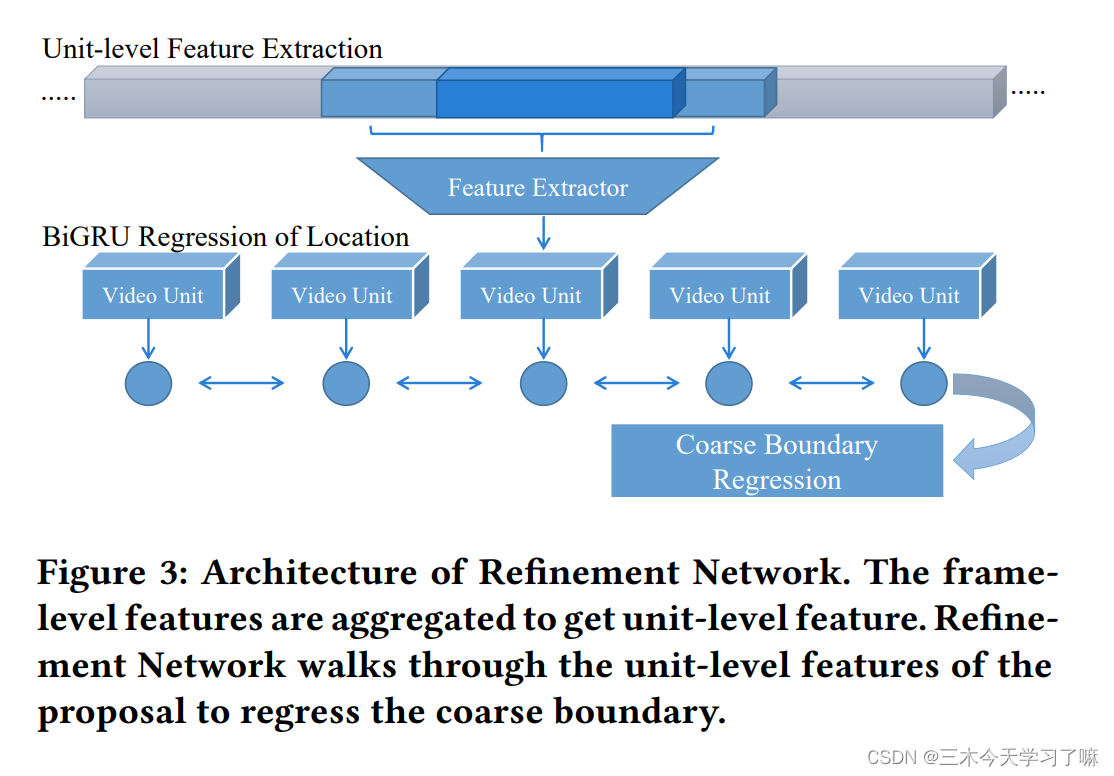
对每一个候选框(s, s+d),先扩展到(s-d/2, s+3*d/2),再对扩展后的框依固定的步长(stride)和时长裁剪出许多视频单元(unit),借鉴"Non-local neural networks"的思路,在提取每个unit特征时得到unit-level的non-local pyramid feature,再将各个unit的特征输入BiGRU网络中(GRU作为RNN的一个变种,可以将任意长度的输入编码成特定长度的输出。BiGRU作为GRU的一种,可以接收任意个unit的特征,处理完最后一个unit后BiGRU的状态即为输出),随后采用全连接层处理BiGRU输出的特征,得到对候选框的中心和持续时长的offset,即对AN网络结果的进一步回归。
Refinement Network采用的loss函数为:
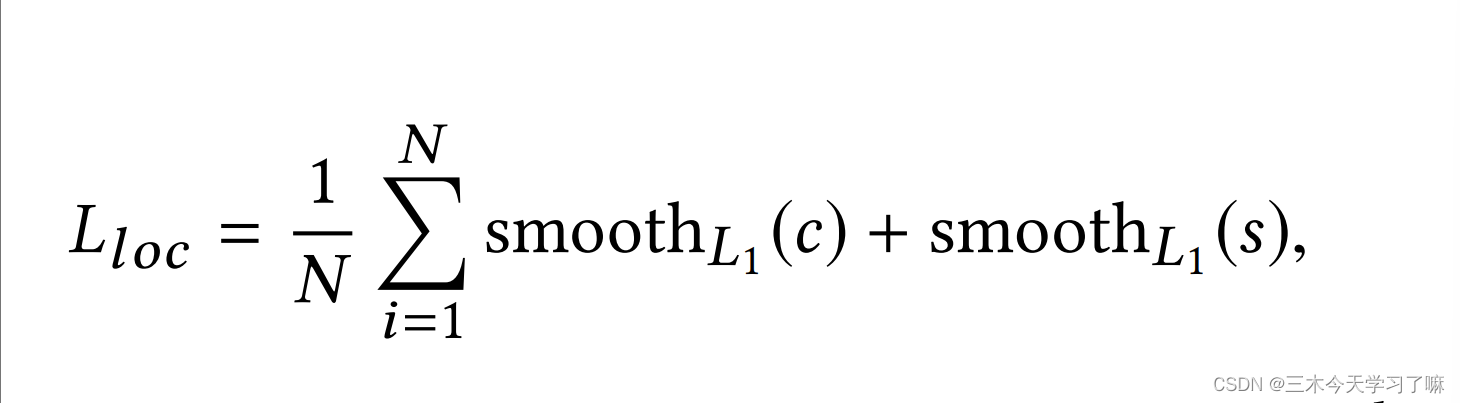
c代表proposal的中心坐标,s代表proposal的长度。N包含positive和incomplete的proposal。 -
Localization Network: LN网络采取SSN网络作为backbone,并在网络最后一层前加了non-local层。LN网络输入RN的候选框,由分类器输出最终的候选框和对应得分。
-
分类器由三种损失函数构成: (正样本:IoU大于0.7;负样本:IoU小于0.1;不完全样本:IoU介于0.3和0.7之间)。
分类损失: 利用正负样本和交叉熵损失函数判定动作种类(K动作+1背景),利用正样本和不完全样本二分类判断动作是前景还是背景(non-local特征在此方面表现卓越),利用正样本训练回归模型。
完整性损失: 只有少数提案会与groundtruth实例相匹配。使用在线硬例挖掘策略来克服数据集的不平衡性,并提高分类器的性能。
定位损失: 同上面的公式:L_loc

2. CTAP: Complementary Temporal Action Proposal Generation
论文目的——拟解决问题
- sliding window ranking方法和actionness score grouping方法各有各的优缺点。

sliding window + proposal ranking + boundary adjustment方法边界不够准确,高召回率也是建立在大量检出proposal基础上的,如图中SW+R&A所示;
unit-level actionness方法边界相对准确,但对actionness score精度要求极高 (精度不高时会生成错误候选框、忽略正确框),这也限制了其AR值的上限,如图中TAG所示;
一种融合方式是在unit-level actionness based方法后接一个window-level的分类器以进行候选框排序、边界回归,可以有效减少错误候选框的生成,但无法解决忽略正确框的问题,如图中TAG+R&A所示。
本论文的主要思路是,在滑窗得到的proposal中收集于actionness方法中可能被忽略的正确框,并将其补加回来。
贡献——创新
- 提出新的互补融合(actionness proposals + sliding windows)方法CTAP,以生成高质量候选框。
- 基于时空卷积,设计新的边界调整(boundary adjustment)和候选框排名(proposal ranking)网络TAR,该网络具有时间卷积功能,可以高效存储候选框边界的序列信息。
实现流程
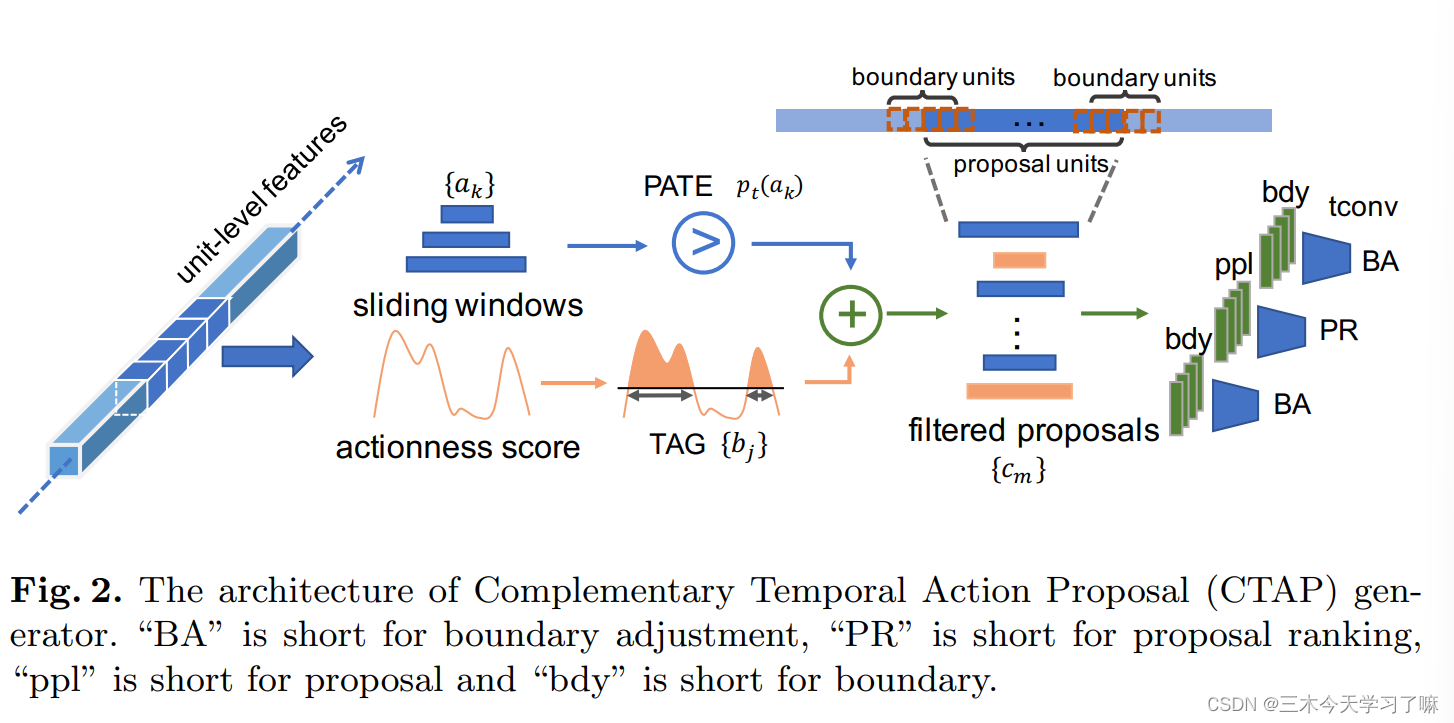
- 第一阶段是生成初始建议generate initial proposals,这些建议来自两个来源,一个是actionness score 和TAG,另一个是滑动窗口。
- 第二阶段是互补滤波complementary filtering。当动作性评分的质量较低时(即动作段的动作性评分较低),TAG会遗漏一些正确的建议,但滑动窗口会统一覆盖视频中的所有片段。
因此,互补滤波complementary filtering从滑动窗口收集高质量的补充候选框,以填补被遗漏的动作性建议。 - 第三阶段是边界调整和建议排名,它由一个时间卷积神经网络组成。
详细方法
-
Initial Proposal Generation:
在生成候选框阶段,先将视频切成无数等长片段snippet,使用双流CNN提取unit-level feature,基于交叉熵训练二分类器,对片段属于动作的概率进行判断,随后采用TAG(分水岭)算法+NMS的方式生成基于特征的候选框bj;再加上滑窗得到的候选框ak组成全体候选框集合。 -
Proposal Complementary Filtering:
利用滑窗方法滑动搜索的特性,将在actionness方法中可能被忽略的正确框补加回来。
PATE(Proposal-level Actionness Trustworthiness Estimator):核心思路为训练一个二分类器,输入proposal对应的unit-level feature,输出是表明该候选框proposal是否能被unit-level actionness scores 和 TAG正确检测的概率。
二分类器训练方法:将GT中有bj框对应的置为正样本,没有bj框对应的置为负样本,采用交叉熵损失函数进行训练。
二分类器测试方法:将ak内所有框的特征输入网络,如果输出的概率低于阈值(这个框可能被TAG网络忽略),则将这个框收集起来,最后收集得到ak的候选框子集pt(ak),将pt(ak)和bj集合取并集得到最终的候选框集合cm。 -
Proposal Ranking and Boundary Adjustment:
对proposal进行排序,并调整时间边界。(TURN也是这样做的,但是它使用均值池来聚合时间特征,这就失去了时间排序信息)Temporal convolutional Adjustment and Ranking (TAR) 网络使用时间卷积层来聚合unit-level features。
对于cm内的候选框,将一个候选框单元(proposal units)和两个边界单元(boundary units)分别输入三个独立的子网络,proposal对应的子网络输出动作的概率,边界修正子网络输出边界回归的offset。
训练TAR网络时,对于滑窗得到的候选框ak,将与GT的tIOU大于0.5的框/与某一GT框tIoU最大的框视作正样本。采用Softmax交叉熵训练proposal子网络,采用L1 loss训练边界回归子网络。
3. BSN: Boundary Sensitive Network for Temporal Action Proposal Generation
论文目的——拟解决问题
- 现实世界中的视频的时长长短不一,而且视频本身中的与动作不相关的时长也占了视频时长的大部分。
- 高质量的预选框的要求: proposal generation 应该生成具有灵活时间长度和精确时间边界的预选框,然后以可靠的置信度分数检索预选框,表明预选框包含动作实例的概率。
贡献——创新
- 提出了 "从局部到全局 "的新架构(BSN)来生成高质量的时序动作候选框。
- 该方法可以整合到现有的检测框架中,并大幅提高在时序动作定位中的性能。
实现流程
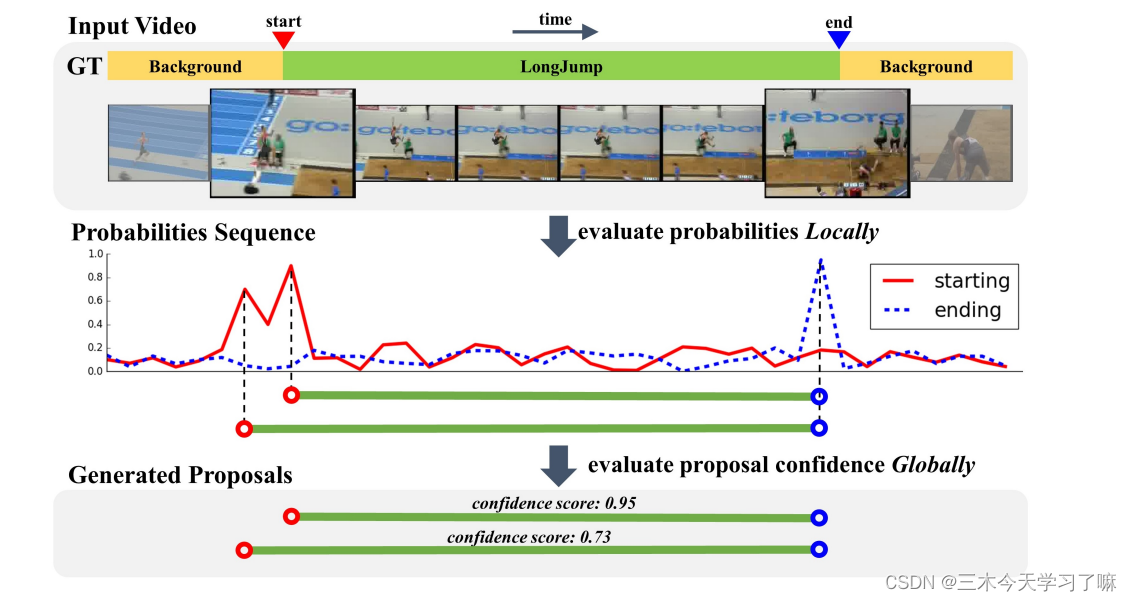
- BSN评估视频中每个时间位置是开始、结束(红实线和蓝虚线)的概率以及是否含动作概率序列作为本地信息。
- BSN直接结合具有高起点和高终点概率的时间位置分别生成预选框。利用自下而上的方式,BSN可以生成具有灵活持续时间和精确边界的预选框。
- 利用由预选框内部和周围的行动性分数组成的特征,BSN通过评估一个预选框是否包含动作的置信度来检索预选框。这些预选框级别的特征proposal-level features为更好地评估提供了全局信息。
详细方法
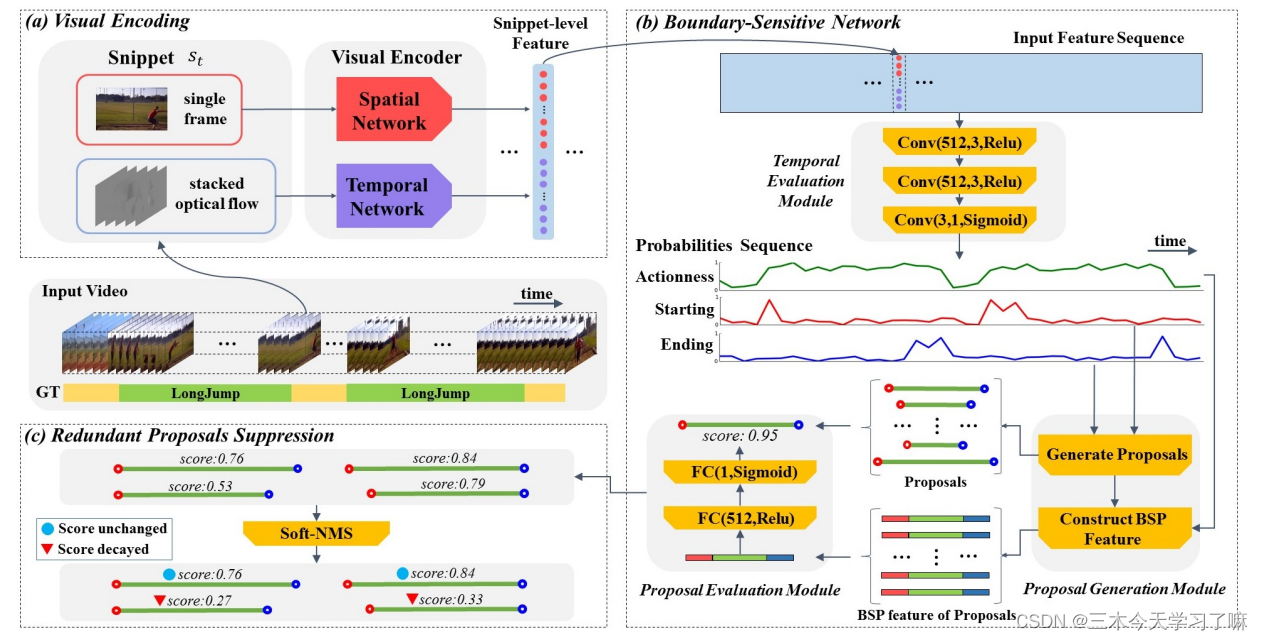
Video Features Encoding:
使用双流网络来对视频中的特征进行特征编码。

Boundary-Sensitive Network:
-
网络结构:包括三个模块,temporal evaluation(时序评估), proposal generation(候选框产生) and proposal evaluation(候选框评估)。
-
temporal evaluation(时序评估): 时空评估模块是一个三层的时空卷积神经网络,它以双流特征序列为输入,评估视频中每个时空位置的开始、结束动作性概率。
-
proposal generation(候选框产生): 将概率较高的起点和终点作为候选框的时空位置,然后根据行动性概率序列为每个候选提案构建边界敏感提案(BSP)特征。
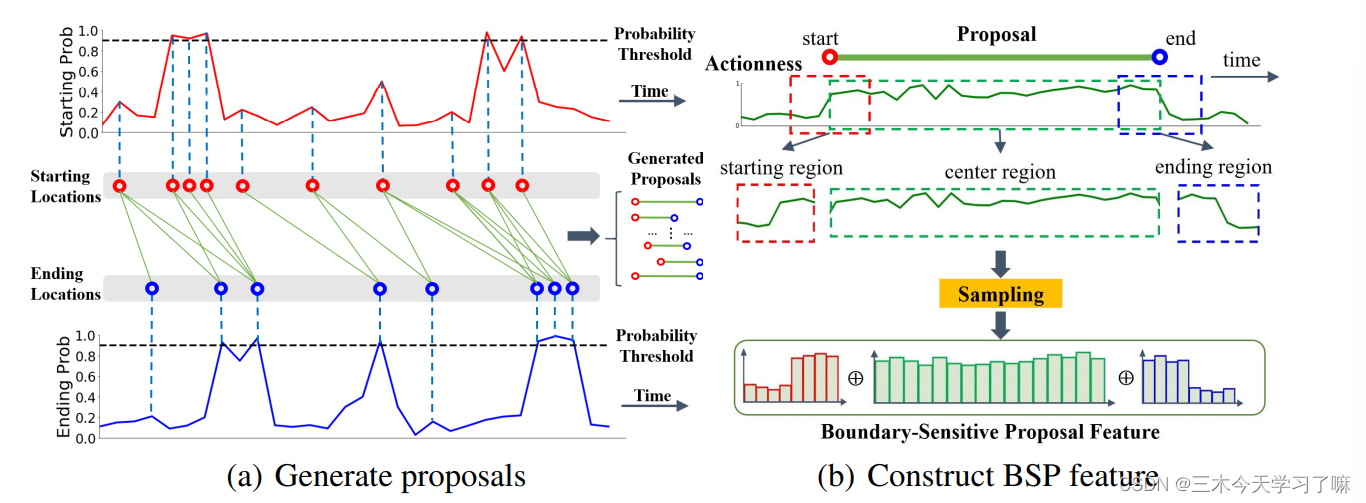
(a) 生成候选框。首先,为了生成候选边界位置,我们选择具有高边界概率或作为概率峰值的时空位置。然后,当它们的持续时间满足条件时,我们将候选的开始和结束位置合并为提案。(b) 构建BSP特征。给定一个提案和动作性概率序列,我们可以在提案的起始、中心和结束区域对动作性序列进行抽样,以构建BSP特征。 -
proposal evaluation(候选框评估): 具有一个隐藏层的多层感知器模型,根据BSP特征评估每个候选提案的信心分数。每个提案的置信度分数和边界概率被融合为最终的置信度分数,用于检索
-
Soft-NMS(结果后处理): 最后,需要对结果进行非极大化抑制,去除重叠的结果。采用了soft-nms算法来通过降低分数的方式来抑制重叠的结果。处理后的结果即为BSN算法最终生成的时序动作提名。
4. Rethinking the Faster R-CNN Architecture for Temporal Action Localization
论文目的——拟解决问题
- 动作持续时间长短不一该如何处理
- 如何利用时域上下文信息
- 如何最好地融合多流特征
贡献——创新
- 提出利用空洞卷积使anchor的持续时长与感受野对齐,从而应用多尺度的anchor来适应动作片段多样化的持续时长。
- 扩展感受野,利用时间上下文信息更好地判断动作种类和确定候选框边界。
- 证明光流和RGB信息晚融合的优越性。
实现流程
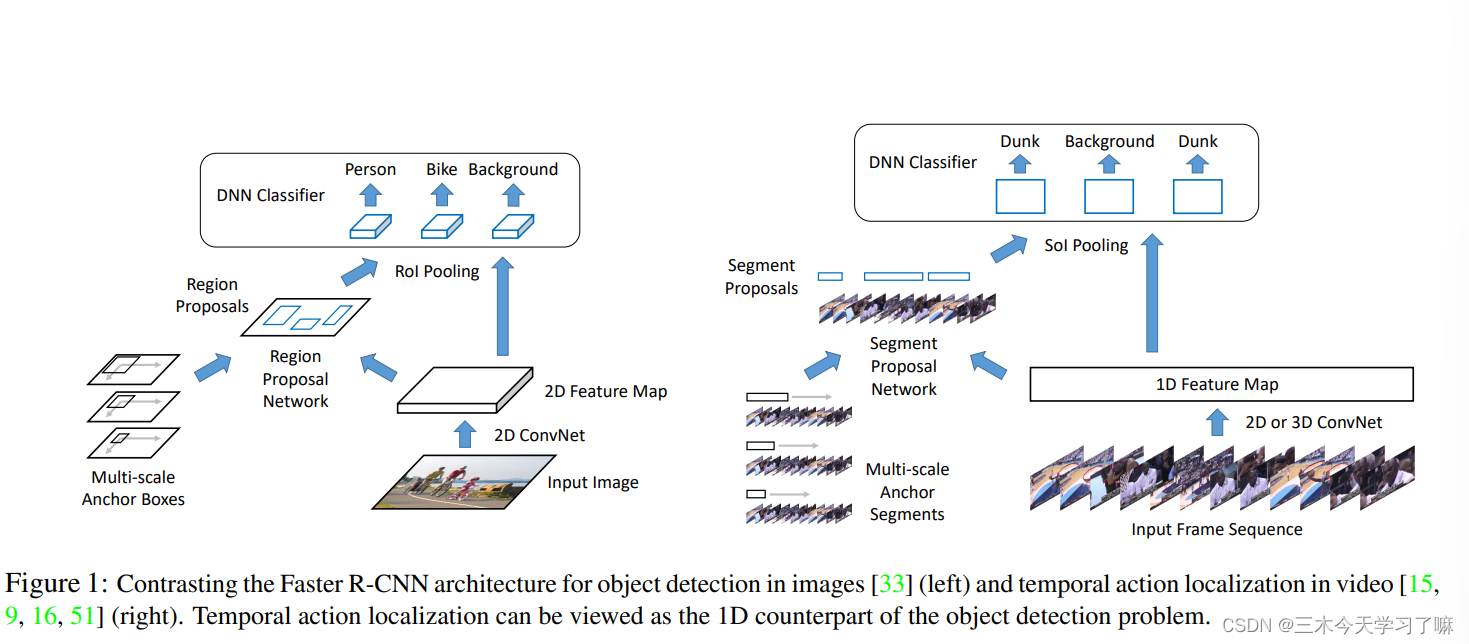
动作候选框可视为一维时间轴上的线段,故均在一维特征上操作。
详细方法
-
Receptive Field Alignment:
在Faster R-CNN中,在每个位置生成的anchor共享相同的receptive field。这一假设对于2D情况是合理的,但不适用于3D情况,因为时间长度的变化可能非常大。为了确保高召回率,应用的锚段因此需要有广泛的尺度。然而,如果感受野设置得太小(即时间短),在对大的(即时间长的)锚进行分类时,提取的特征可能不包含足够的信息。而如果它设置得过大,在对小锚进行分类时,提取的特征可能会被不相关的信息所支配。(详细内容可以参读原论文)
本论文使用多级塔型结构(a multi-tower network)和时域空洞卷积(dilated temporal convolutions) 使任一anchor的感受野与其持续时长对应。同时,与RPN类似,也使用了并行的两个11卷积层以完成anchor包含目标的判断和bbox回归。
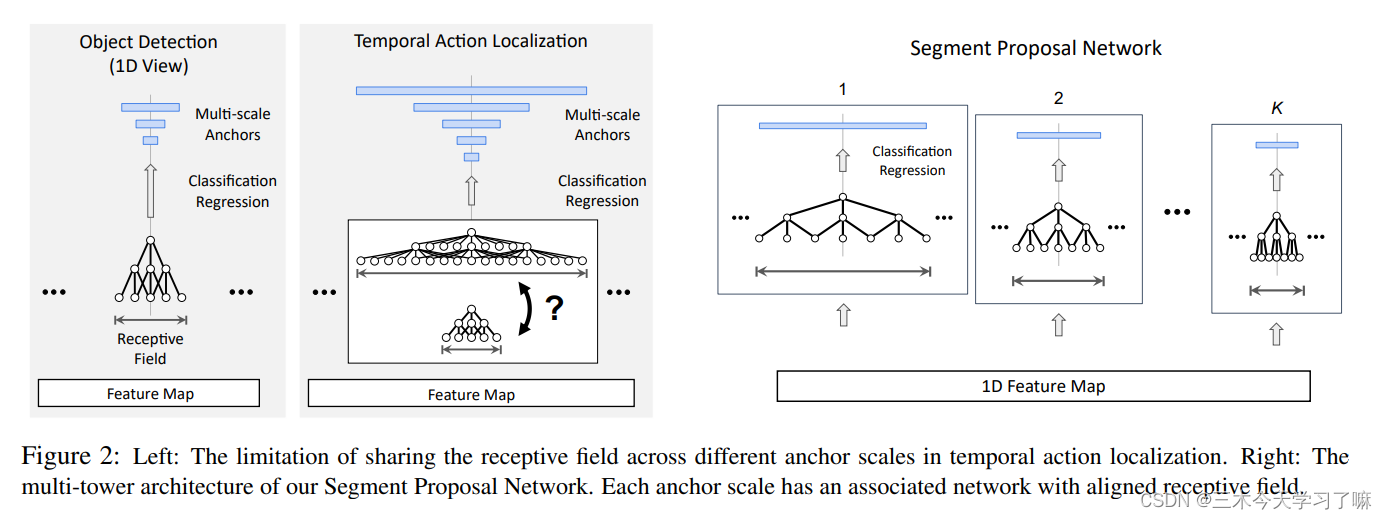 如何设计具有可控感受野大小s的时态卷积网?
如何设计具有可控感受野大小s的时态卷积网?
1)堆叠卷积层。缺点:容易导致过拟合
2)增加池化层,缺点:指数级降低输出特征图的分辨率
为了避免增加模型参数并保持分辨率,提出用dilated temporal convolutions:
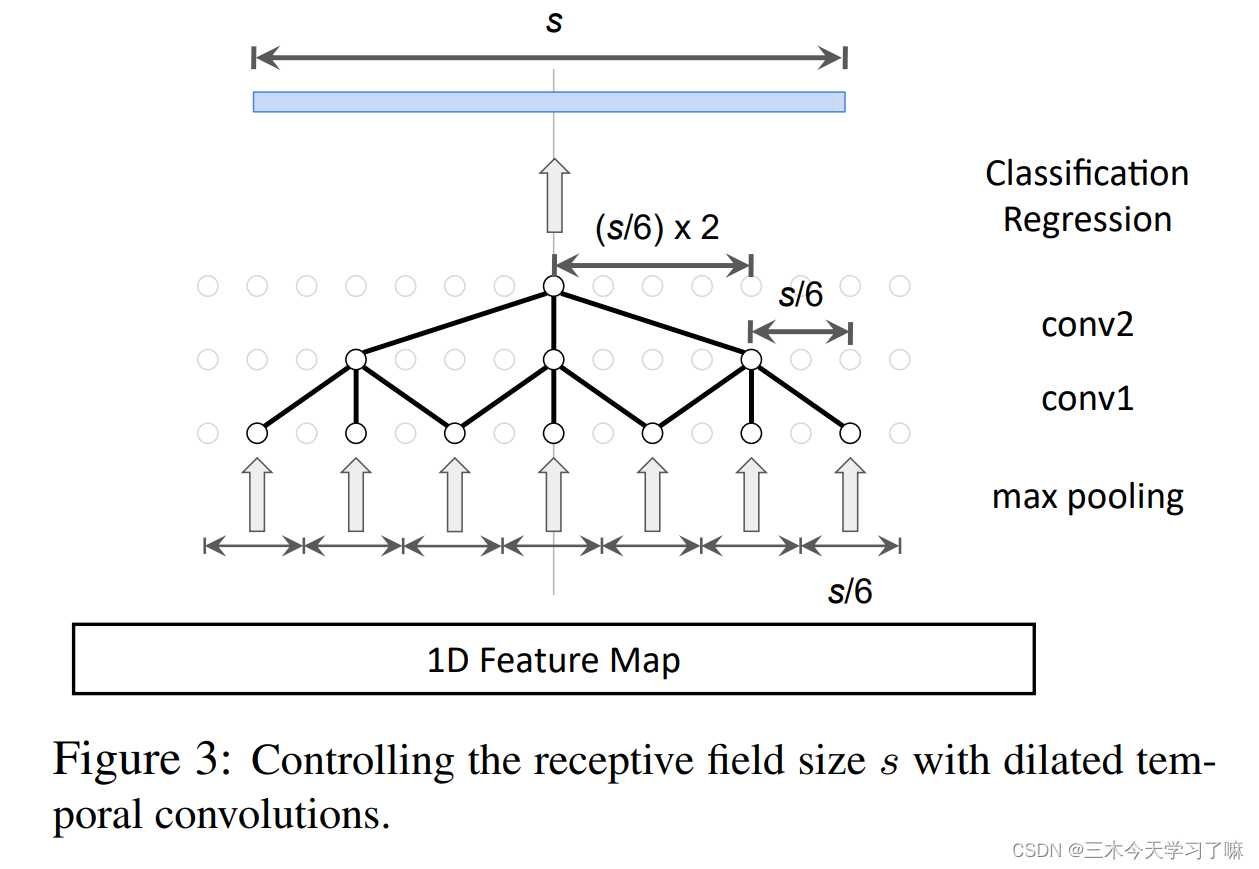 目标感受野尺寸s,定义两层的dialation rate :d1=s/6 ,d2=s/62,为了平滑输入,在第一个conv层前加了一个kernel size = s/6的max pooling。
目标感受野尺寸s,定义两层的dialation rate :d1=s/6 ,d2=s/62,为了平滑输入,在第一个conv层前加了一个kernel size = s/6的max pooling。
为了达到目标感受野的大小s,通过r1=s/6和r2=(s/6)×2来明确计算第l层所需的dilation rate(即子采样率)r_l。 还通过在第一个卷积层之前添加一个内核大小为s/6的max pooling layer来平滑子采样前的输入。 -
Context Feature Extraction:
proposal network:
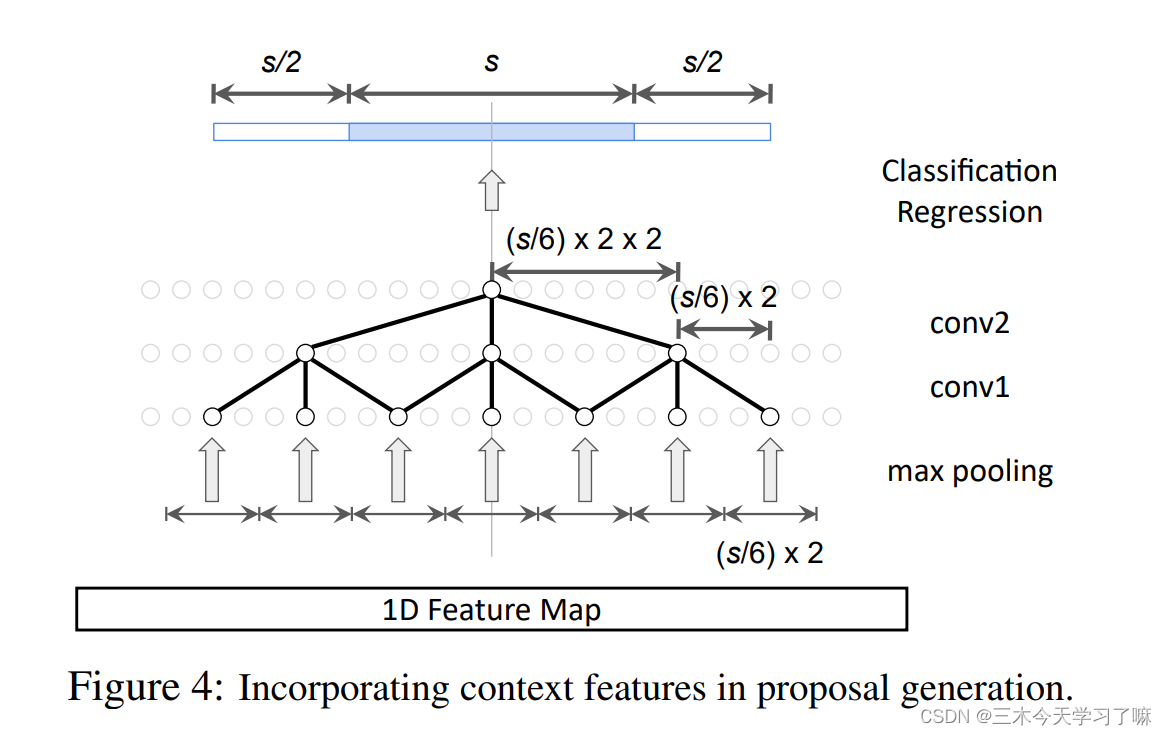 为了确保context feature被用于锚点分类和边界回归,感受野必须覆盖上下文区域。假设锚的规模为s,我们强制要求感受野也覆盖紧邻锚之前和之后的两个长度为s/2的片段。
为了确保context feature被用于锚点分类和边界回归,感受野必须覆盖上下文区域。假设锚的规模为s,我们强制要求感受野也覆盖紧邻锚之前和之后的两个长度为s/2的片段。
action classification:
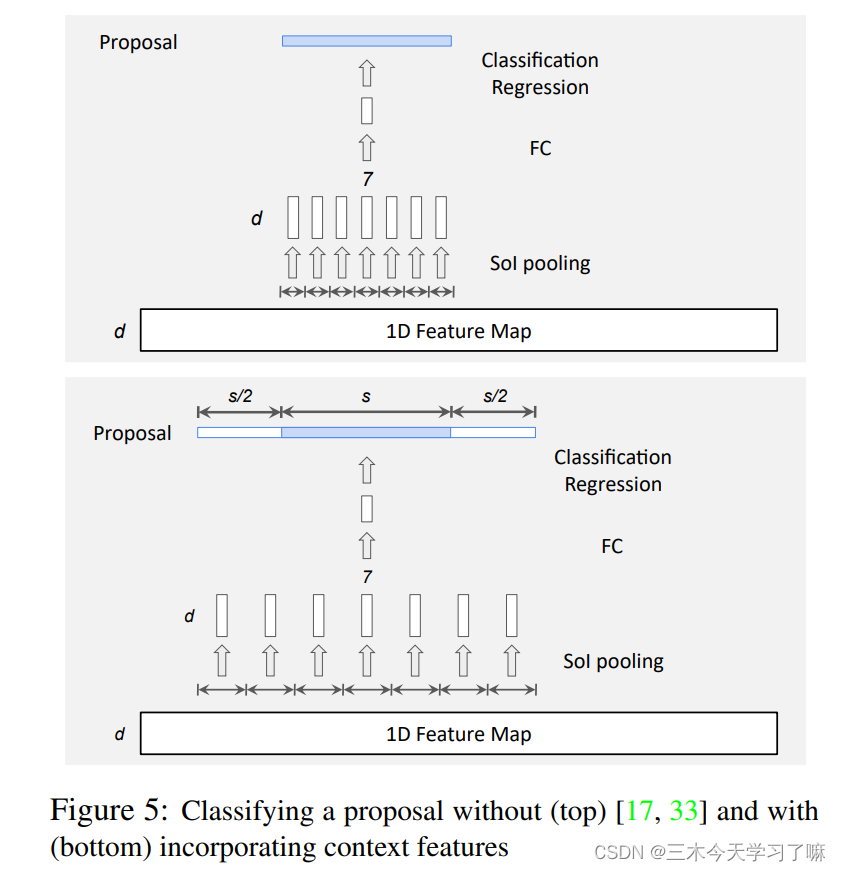
在动作分类中,我们进行SoI池化(即1D RoI池化),为每个获得的提议提取一个固定大小的特征图。我们在图5(顶部)中说明了输出大小为7的SoI池的机制。如图5(底部)所示,对于一个大小为s的提议,我们的SoI池的范围不仅包括提议段,还包括紧接提议之前和之后的两个大小为s/2的段,类似于锚的分类。 -
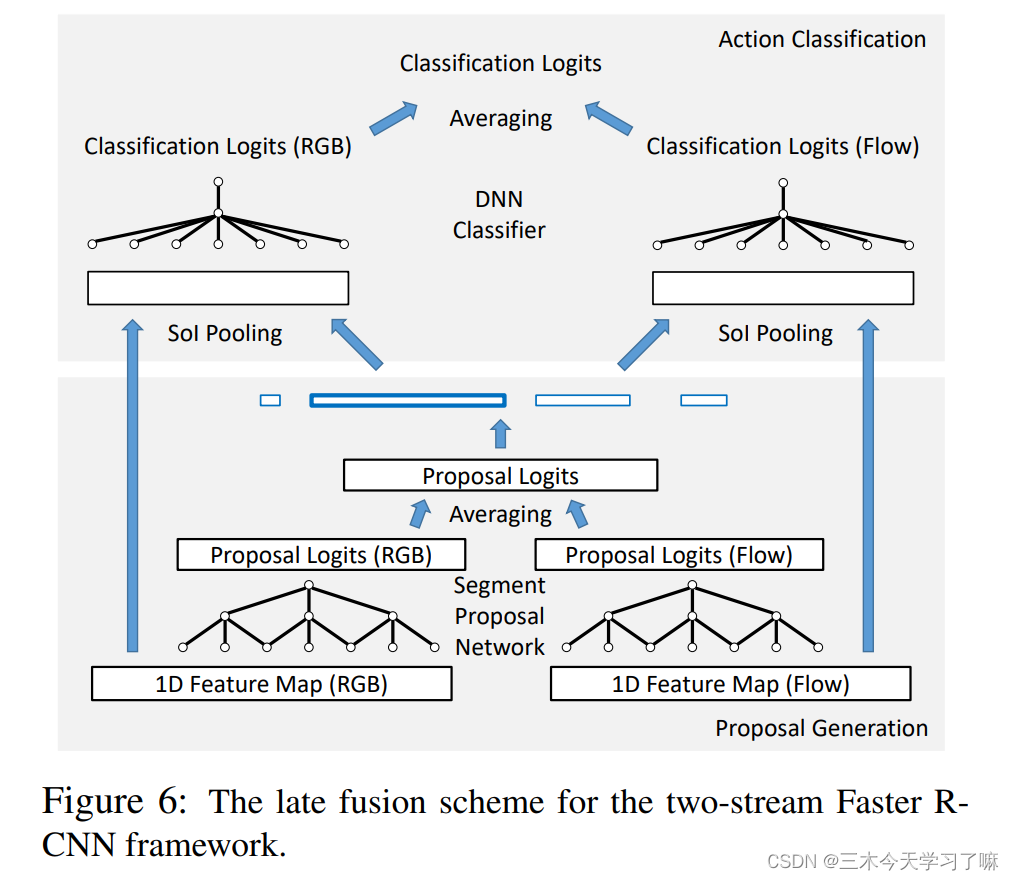
Late Feature Fusion:
先用两个网络分别提取1-D的RGB和FLOW特征,输入proposal生成网络(rpn)最后两个分数做均值产生proposals,再把proposals结合各自网络特征做分类(fast-rcnn部分),再把两个网络结果做average。