Project 4: Inference in Bayes Nets
Code Link
GitHub:UC-Berkeley-2021-Spring-CS188-Project4-Inference-in-Bayes-Nets
Introduction
Project Intro
本题目来源于UC Berkeley 2021春季 CS188 Artificial Intelligence Project4:Inference in Bayes Nets上的内容,项目具体介绍链接点击此处:UC Berkeley Spring 2021 Project4:Inference in Bayes Nets
In this project, you will implement inference algorithms for Bayes Nets, specifically variable elimination and value-of-perfect-information computations. These inference algorithms will allow you to reason about the existence of invisible pellets and ghosts.
在本项目中,您将实现贝叶斯网的推理算法,特别是变量消除和完美信息值计算。这些推理算法将允许您对不可见小球和幽灵的存在进行推理。
Tools Intro
python3+VSCode
Files Intro
| File you’ll edit: | Function |
|---|---|
| factorOperations.py | 因子操作(加入、消除、归一化) |
| inference.py | 推理算法(枚举、变量消除、似然加权) |
| bayesAgent.py | 在不确定性下推理的吃豆子代理 |
| Files you should read but NOT edit: | Function |
|---|---|
| bayesNet.py | BayesNet 和 Factor 类 |
其余文件均为配置文件,可选择忽略。
Solve Process
Previously Done
在对项目框架进行首次的测试运行时,终端报错:
AttributeError:module ‘importlib’ has no attribute 'util’

面对这个措手不及的错误,我在网上大量查阅资料,试图解决问题,现记录一下我踩过的坑们:
既然模块缺失,那再安装一次:pip install importlib

重复命令C:\Python39\python.exe -m pip install --upgrade pip,OSError: [WinError 5] 拒绝访问。: ‘c:\python39\lib\site-packages\pip-21.2.3.dist-info\entry_points.txt’
Consider using the --user option or check the permissions.
此处显示访问权限有误,需要以管理员身份打开终端,于是引入注册表文件,以保证在文件任何位置都能以管理员身份运行cmd。写入.txt文件后另存为.reg文件并运行,便成功通过。
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\Directory\shell\runas]
@="Open cmd here as Admin"
"HasLUAShield"=""
[HKEY_CLASSES_ROOT\Directory\shell\runas\command]
@="cmd.exe /s /k pushd \"%V\""
[-HKEY_CLASSES_ROOT\Directory\Background\shell\runas]
[HKEY_CLASSES_ROOT\Directory\Background\shell\runas]
@="Open cmd here as Admin"
"HasLUAShield"=""
[HKEY_CLASSES_ROOT\Directory\Background\shell\runas\command]
@="cmd.exe /s /k pushd \"%V\""
[-HKEY_CLASSES_ROOT\Drive\shell\runas]
[HKEY_CLASSES_ROOT\Drive\shell\runas]
@="Open cmd here as Admin"
"HasLUAShield"=""
[HKEY_CLASSES_ROOT\Drive\shell\runas\command]
<span>@="cmd.exe /s /k pushd \"%V\""</span>

终端提示下,warning显示:ignoring invalid distribution,参考安装、升级pip,但是python -m pip install --upgrade pip报错的解决办法。可知,实际上是在之前进行unistall和install的过程中,旧版本未被删除完毕,于是找到遗漏版本所在文件夹C:\Python39\Lib\site-packages,对指定删掉即可。

上述方法对于pc中python本来模块出现遗漏来说有用,但本题情况特殊,是在指定文件内缺失,于是选择在该文件顶部引入util库。
在autograder.py中添加
from importlib import util

出现评分界面,bug解决。

Question 1:Bayes Net Structure
本题主要是通过参考bayesNet.py中printStarterBayesNet()函数模块,在bayesAgent.py的constructBayesNet()函数里进行贝叶斯网络的构造。
本项目的贝叶斯网络图如下:
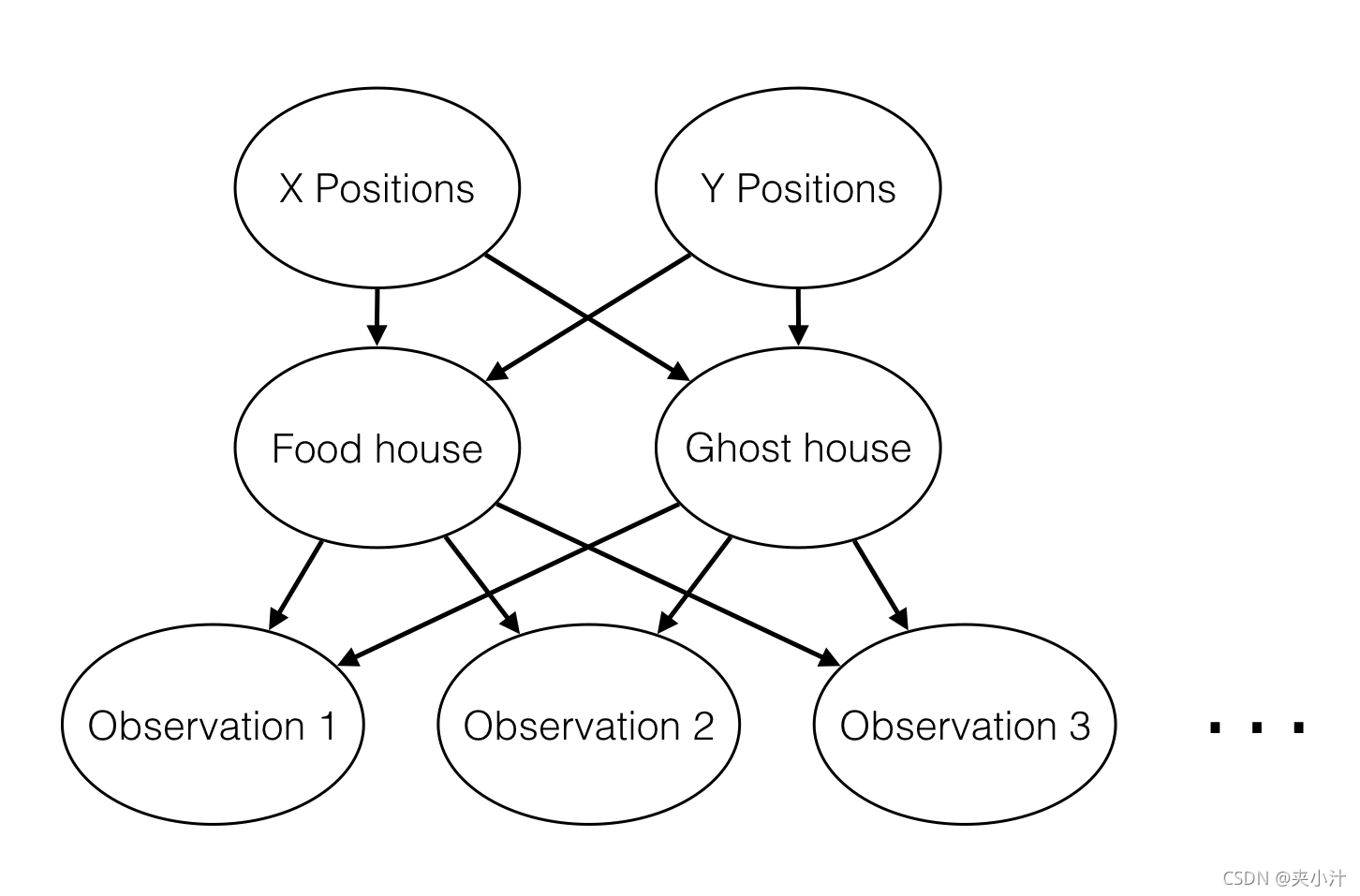
从此图中,我们可以清楚的得到贝叶斯网络的关系:
X Position->Food house;X Position->Ghost House
Y Position->Food house;Y Position->Ghost House
Food house->Observation 1,2,3,…
Ghost house->Observation 1,2,3,…
根据上述关系,着手准备constructBayesNet()的构建。
# This is the example V structured Bayes' net from the lecture # on Bayes' nets independence.
# Constructing Bayes' nets: variables list
variableList = ['Raining', 'Ballgame', 'Traffic']
# Constructing Bayes' nets, edge list: (x, y) means edge from x to y
edgeTuplesList = [('Raining', 'Traffic'), ('Ballgame', 'Traffic')]
# Construct the domain for each variable (a list like)
variableDomainsDict = {}
variableDomainsDict['Raining'] = ['yes', 'no']
variableDomainsDict['Ballgame'] = ['yes', 'no']
variableDomainsDict['Traffic'] = ['yes', 'no']
# None of the conditional probability tables are assigned yet in our Bayes' net
bayesNet = constructEmptyBayesNet(variableList, edgeTuplesList, variableDomainsDict)
根据上述参数可知,贝叶斯网络中需要variableList变量列表、edgeTupleList有向边列表以及variableDomainDict变量值域,在bayesAgent.py中,转化为三个对应的参数,即variableList、edges、variableDomainsDict。
在bayesAgent.py中,预先给了三个变量:
obsVars = [] edges = [] variableDomainsDict = {}
其中edges和variableDomainDict在上面已经出现过,那么obsVars是什么呢?根据题目要求陈述:“这些观察结果是吃豆子在绕着棋盘旅行时所做的测量。请注意,有许多这样的节点——可能是房屋墙壁的每个棋盘位置都有一个。”,这就是我们在贝叶斯网络给定构建图中所知道的Observation变量列表,而且变量列表中的每一个变量(即obsVars中的每一个obsVar),有不同的值相对应。
在本python文件的顶部声明过此变量的模板:
OBS_VAR_TEMPLATE = “obs(%d,%d)”
再结合题目注释里所给的函数:
for housePos in gameState.getPossibleHouses():
for obsPos in gameState.getHouseWalls(housePos)
obsVar = OBS_VAR_TEMPLATE % obsPos
我们便能得到变量列表中每一个变量所对应的位置及变量名
原本以为此问只需要根据bayesNet.py中printStarterBayesNet()的单纯形式,对edges进行构造即可。发现错误的情况是problem 1提交正确,而problem 2提交错误。因为problem 2所使用的bayesNet正是我们在problem 1中所构造的,这不得不促使我在完成problem 2后,又倒退回来重新审视problem 1所遗漏处理的问题。
其实所反映的问题十分简单,我们在观察problem 1的测试用例中也能发现。在对有向边列表edges进行构造时,我只是简单参考bayesNet.py中的构造方法,通过edge=[(x1,y1),(x2,y2)]的形式,却忽略了一些特殊案例:


后来我发现我的这种做法没能将变量之间关系形成真正边,于是参考python中extend()函数和append()函数的区别之后,我恍然大悟,应该使用append(),这样更加严谨。extend()函数和append()都能将元素加至list中,而append()的特殊之处在于,append()以向List中添加任何元素,比如字典,不过字典整体作为List中的一个元素。这样一来,就能实现本问题的,对edge的封装。
更改后的代码如下:(其中注释部分为原有代码)
def constructBayesNet(gameState):
"""
Question 1: Bayes net structure
Construct an empty Bayes net according to the structure given in the project
description.
There are 5 kinds of variables in this Bayes net:
- a single "x position" variable (controlling the x pos of the houses)
- a single "y position" variable (controlling the y pos of the houses)
- a single "food house" variable (containing the house centers)
- a single "ghost house" variable (containing the house centers)
- a large number of "observation" variables for each cell Pacman can measure
You *must* name all position and house variables using the constants
(X_POS_VAR, FOOD_HOUSE_VAR, etc.) at the top of this file.
The full set of observation variables can be obtained as follows:
for housePos in gameState.getPossibleHouses():
for obsPos in gameState.getHouseWalls(housePos)
obsVar = OBS_VAR_TEMPLATE % obsPos
In this method, you should:
- populate `obsVars` using the procedure above
- populate `edges` with every edge in the Bayes Net (a tuple `(from, to)`)
- set each `variableDomainsDict[var] = values`, where `values` is the set
of possible assignments to `var`. These should again be set using the
constants defined at the top of this file.
"""
obsVars = []
edges = []
variableDomainsDict = {
}
"*** YOUR CODE HERE ***"
for housePos in gameState.getPossibleHouses():
for obsPos in gameState.getHouseWalls(housePos):
obsVar=OBS_VAR_TEMPLATE%obsPos #construct a simple variable
obsVars.append(obsVar)
variableDomainsDict[obsVar]=OBS_VALS
variableList=[X_POS_VAR,Y_POS_VAR]+HOUSE_VARS+obsVars
# edges=[(X_POS_VAR,FOOD_HOUSE_VAR),(X_POS_VAR,GHOST_HOUSE_VAR),(Y_POS_VAR,FOOD_HOUSE_VAR),
# (Y_POS_VAR,GHOST_HOUSE_VAR)]
edges.append((X_POS_VAR,FOOD_HOUSE_VAR))
edges.append((X_POS_VAR,GHOST_HOUSE_VAR))
edges.append((Y_POS_VAR,FOOD_HOUSE_VAR))
edges.append((Y_POS_VAR,GHOST_HOUSE_VAR))
# for obsVar in obsVars:
# edges=[(FOOD_HOUSE_VAR,obsVar),(GHOST_HOUSE_VAR,obsVar)]
for obsVar in obsVars:
edges.append((FOOD_HOUSE_VAR,obsVar))
edges.append((GHOST_HOUSE_VAR,obsVar))
variableDomainsDict[X_POS_VAR]=X_POS_VALS
variableDomainsDict[Y_POS_VAR]=Y_POS_VALS
variableDomainsDict[FOOD_HOUSE_VAR]=HOUSE_VALS
variableDomainsDict[GHOST_HOUSE_VAR]=HOUSE_VALS
ABayesNet=bn.constructEmptyBayesNet(variableList,edges,variableDomainsDict)
return ABayesNet,obsVars

Question 2:Bayes Net Probabilities
本题主要是通过参考bayesAgent.py中的fillXCPT()函数,来实现bayesAgent.py的fillYCPT()函数。
因为较为简单,所以不过多赘述。主要方法即:对Y Position变量所指向的Observation变量的每一个值,用Factor.setProbability()进行概率的设定,然后通过setCPT()建立条件概率表即可。
def fillYCPT(bayesNet, gameState):
"""
Question 2: Bayes net probabilities
Fill the CPT that gives the prior probability over the y position variable.
See the definition of `fillXCPT` above for an example of how to do this.
You can use the PROB_* constants imported from layout rather than writing
probabilities down by hand.
BOTH_TOP_VAL, BOTH_BOTTOM_VAL, LEFT_TOP_VAL, LEFT_BOTTOM_VAL
"""
from layout import PROB_BOTH_TOP
from layout import PROB_BOTH_BOTTOM
from layout import PROB_ONLY_LEFT_TOP
from layout import PROB_ONLY_LEFT_BOTTOM
yFactor = bn.Factor([Y_POS_VAR], [], bayesNet.variableDomainsDict())
"*** YOUR CODE HERE ***"
yFactor.setProbability({
Y_POS_VAR: BOTH_TOP_VAL},PROB_BOTH_TOP)
yFactor.setProbability({
Y_POS_VAR: BOTH_BOTTOM_VAL},PROB_BOTH_BOTTOM)
yFactor.setProbability({
Y_POS_VAR: LEFT_TOP_VAL},PROB_ONLY_LEFT_TOP)
yFactor.setProbability({
Y_POS_VAR: LEFT_BOTTOM_VAL},PROB_ONLY_LEFT_BOTTOM)
bayesNet.setCPT(Y_POS_VAR,yFactor)
"*** END YOUR CODE HERE ***"

Question 3:Join Factors
本问题主要是需要通过参考bayesNet.py中的printStarterBayesNet()来完成factorOperations.py中的joinFactors()的函数来实现条件概率表中Factor的乘积。
根据提示,我们会用到的有效函数如下:
Factor.getAllPossibleAssignmentDicts
Factor.getProbability
Factor.setProbability
Factor.unconditionedVariables
Factor.conditionedVariables
Factor.variableDomainsDict
参考bayesNet.py中的Factor类,上述函数有了准确定义:
| Function | Use |
|---|---|
| getAllPossibleAssignmentDicts() | Use this function to get the assignmentDict for each possible assignment for the combination of variables contained in the factor.Returns a list of all assignmentDicts that the factor contains rows for, allowing you to iterate through each row in the actor when combined with getProbability and setProbability使用此函数获取因子中包含的变量组合的每个可能赋值的assignmentDict。返回因子包含行的所有assignmentDict的列表,允许您在与getProbability和setProbability组合时迭代因子中的每一行 |
| getProbability() | Returns the probability entry stored in the factor for that combination of variable assignments.返回存储在因子中的该变量赋值组合的概率项。 |
| setProbability() | Input probability is the probability that will be set within the table.输入概率是表中设置的概率。 |
| unconditionedVariables() | Retuns a copy of the unconditioned variables in the factor重新运行因子中无条件变量的副本 |
| conditionedVariables() | Retuns a copy of the conditioned variables in the factor重新运行因子中条件变量的副本 |
| variableDomainsDict() | Retuns a copy of the variable domains in the factor重新运行因子中变量域的副本 |
在了解以上函数的大致用途后,可根据条件概率表的构造步骤以及乘积的计算方法,列出本问题的伪代码。
在joinFactors()函数中,题目事先给了提示:
1、应该计算无条件变量集unconditionedVariables和条件变量集conditionedVariables用于连接这些因素的变量;
2、输入的是含有许多factors的列表factorList,返回一个新的factor,并且包含这些变量及其输入factor对应行乘积的概率条目,即返回一个新的条件概率表newCPT;
3、可以假设所有输入factor的variableDomainsDict都是相同的,因为它们来自相同的BayesNet,即variableDomainDict取factorList中任何一个factor.variableDomainsDict()均可;
4、joinFactors只允许非条件变量出现在一个输入因子中,即一旦多个输入因子同时出现非条件变量的情况不允许,需要进行过滤判断;
5、将assignmentDict作为输入的Factor方法(如getProbability和setProbability)可以处理分配的变量多于该Factor中的变量的assignmentDict,即使用assignmentDict对于迭代所有赋值组合具有重要意义。
在对题目要求进行充分剖析之后,本问题具体步骤如下:
1、声明所需的所有集合,即上述提到的:unconditionedVariables=[];conditionedVariables=[];factorList=[] ;variableDomainsDict=[]
2、集合的初始化;
3、由于joinFactors只允许非条件变量出现在一个输入因子中,所以进行过滤判断:不符合条件的remove();
4、建立一个条件概率表newCPT;
5、使用assignmentDict实现表中因子的乘积,并更新表;
6、返回表。
转化后的具体代码如下:
def joinFactors(factors):
"""
Question 3: Your join implementation
Input factors is a list of factors.
You should calculate the set of unconditioned variables and conditioned
variables for the join of those factors.
Return a new factor that has those variables and whose probability entries
are product of the corresponding rows of the input factors.
You may assume that the variableDomainsDict for all the input
factors are the same, since they come from the same BayesNet.
joinFactors will only allow unconditionedVariables to appear in
one input factor (so their join is well defined).
Hint: Factor methods that take an assignmentDict as input
(such as getProbability and setProbability) can handle
assignmentDicts that assign more variables than are in that factor.
Useful functions:
Factor.getAllPossibleAssignmentDicts
Factor.getProbability
Factor.setProbability
Factor.unconditionedVariables
Factor.conditionedVariables
Factor.variableDomainsDict
"""
# typecheck portion
setsOfUnconditioned = [set(factor.unconditionedVariables()) for factor in factors]
if len(factors) > 1:
intersect = functools.reduce(lambda x, y: x & y, setsOfUnconditioned)
if len(intersect) > 0:
print("Factor failed joinFactors typecheck: ", factors)
raise ValueError("unconditionedVariables can only appear in one factor. \n"
+ "unconditionedVariables: " + str(intersect) +
"\nappear in more than one input factor.\n" +
"Input factors: \n" +
"\n".join(map(str, factors)))
"""iterate over assignments in newFactor.getAllPossibleAssignmentsDicts():
iterate over factors:
Call factor.getProbability(assignment) [and do something with it so you can do
the setProbability step in the next line]
setProbability in the newFactor."""
"*** YOUR CODE HERE ***"
unconditionedVariables=[]
conditionedVariables=[]
factorList=[]
variableDomainsDict=[]
for factor in factors:
factorList.append(factor)
variableDomainsDict=factorList[0].variableDomainsDict()
for factor in factorList:
for i in factor.unconditionedVariables():
if i not in unconditionedVariables:
unconditionedVariables.append(i)
for j in factor.conditionedVariables():
if j not in conditionedVariables:
conditionedVariables.append(j)
#judge whether is wrong
for variable in unconditionedVariables:
if variable in conditionedVariables:
conditionedVariables.remove(variable)
#Fill in the CPT
newCPT=Factor(unconditionedVariables,conditionedVariables,variableDomainsDict)
#use factor.getAllPossibleAssignmentDicts() to iterate through all combinations of assignments:
for assignmentDict in newCPT.getAllPossibleAssignmentDicts():
probability=1
for factor in factorList:
probability=probability*factor.getProbability(assignmentDict)
newCPT.setProbability(assignmentDict,probability)
return newCPT
"*** END YOUR CODE HERE ***"

Question 4:Eliminate
本问题主要是通过完善factorOperations.py中eliminateWithCallTracking()函数下的eliminate()部分。
和问题3不同的是,本题的输入factor只有一个,而不是像factorList一样的是一个列表。输入消除变量是要从因子中消除的变量。并且:eliminationVariable必须是因子中的非条件变量unconditionedVariables。
应计算通过消除变量eliminationVariable获得的因子的非条件变量unconditionedVariables和条件变量集conditionedVariables,返回一个新因子newFactor,其中提及eliminationVariable的所有行与匹配其他变量赋值的行求和。
此题的解法与上题类似,上题是希望返回变量及其输入factor对应行乘积的概率条目,而本题是返回匹配其他变量赋值的行的和。两个问题中都需要调用factor.getProbability()和factor.setProbability()函数,但不同之处在于,由于本题是求和,所以概率值probability应初始化为0而不是1。
Factor.getAllPossibleAssignmentDicts
Factor.getProbability
Factor.setProbability
Factor.unconditionedVariables
Factor.conditionedVariables
Factor.variableDomainsDict
以上函数在Question 3中有提及,此处不予再提。
由于eliminationVariable必须是因子中的非条件变量unconditionedVariables,所以在构造新因子newFactor之前,对非条件变量中的变量进行eliminate消除。即:如果unconditionedVariables中的变量在eliminationVariable中的话消除,不在则保留。
最开始的时候我使用单纯的嵌套判断来进行指定元素的append(),但是由于数据量计算量大,在我的电脑上跑崩无数次之后,我换了性能更高的室友的电脑,命令行报错为MemoryError:


于是我参考他人换为了其他的表达方式:
# for unconditioned in unconditionedVariables:
# if unconditioned!=eliminationVariable:
# unconditionedVariables.append(unconditioned)
unconditionedVariables=[unconditioned for unconditioned in unconditionedVariables
if unconditioned !=eliminationVariable]
完整代码如下:
def eliminateWithCallTracking(callTrackingList=None):
def eliminate(factor, eliminationVariable):
"""
Question 4: Your eliminate implementation
Input factor is a single factor.
Input eliminationVariable is the variable to eliminate from factor.
eliminationVariable must be an unconditioned variable in factor.
You should calculate the set of unconditioned variables and conditioned
variables for the factor obtained by eliminating the variable
eliminationVariable.
Return a new factor where all of the rows mentioning
eliminationVariable are summed with rows that match
assignments on the other variables.
Useful functions:
Factor.getAllPossibleAssignmentDicts
Factor.getProbability
Factor.setProbability
Factor.unconditionedVariables
Factor.conditionedVariables
Factor.variableDomainsDict
"""
# autograder tracking -- don't remove
if not (callTrackingList is None):
callTrackingList.append(('eliminate', eliminationVariable))
# typecheck portion
if eliminationVariable not in factor.unconditionedVariables():
print("Factor failed eliminate typecheck: ", factor)
raise ValueError("Elimination variable is not an unconditioned variable " \
+ "in this factor\n" +
"eliminationVariable: " + str(eliminationVariable) + \
"\nunconditionedVariables:" + str(factor.unconditionedVariables()))
if len(factor.unconditionedVariables()) == 1:
print("Factor failed eliminate typecheck: ", factor)
raise ValueError("Factor has only one unconditioned variable, so you " \
+ "can't eliminate \nthat variable.\n" + \
"eliminationVariable:" + str(eliminationVariable) + "\n" + \
"unconditionedVariables: " + str(factor.unconditionedVariables()))
"*** YOUR CODE HERE ***"
unconditionedVariables=[]
conditionedVariables=[]
variableDomainsDict=[]
#differ from the problem 3,factor there is single but not a list
#to solve problems,we can just use the functions the problem 4 said
unconditionedVariables=list(factor.unconditionedVariables())
conditionedVariables=factor.conditionedVariables()
variableDomainsDict=factor.variableDomainsDict()
#new factor(return)
#newFactor=Factor(unconditionedVariables,conditionedVariables,variableDomainsDict)
#calculate the set of unconditioned variables and conditioned variables
# for the factor obtained by eliminating the variable eliminationVariable.
# for unconditioned in unconditionedVariables:
# if unconditioned!=eliminationVariable:
# unconditionedVariables.append(unconditioned)
unconditionedVariables=[unconditioned for unconditioned in unconditionedVariables
if unconditioned !=eliminationVariable]
newFactor=Factor(unconditionedVariables,conditionedVariables,variableDomainsDict)
#use factor.getAllPossibleAssignmentDicts() to iterate through all combinations of assignments:
for assignment in newFactor.getAllPossibleAssignmentDicts():
probability=0
for eliminateValues in variableDomainsDict[eliminationVariable]:
oldAssign=assignment.copy() # In order to remain the ordinary sample
# record eliminationVariables
oldAssign[eliminationVariable]=eliminateValues
probability+=factor.getProbability(oldAssign)
newFactor.setProbability(assignment,probability)
return newFactor
"*** END YOUR CODE HERE ***"
return eliminate
eliminate = eliminateWithCallTracking()

Question 5:Normalize
本题是需要实现factorOperations.py中的normalize()函数,来实现归一化操作。
根据题目所述可以知晓,归一化因子的一组条件变量由输入因子的条件变量以及任何输入因子的无条件变量组成,而且在它们的域中只有一个条目,这个只有一个条目的特征可以成为我们之后判断的依据。题目表述得有些拗口,大致意思就是,需要将域中只有一个值的变量分配给该单个值。
题目还提到,所有在其域中具有多个元素的变量都被假定为无条件的,所以可以从无条件变量unconditionedVariables出发,遍历并选出长度为1的非条件变量,将其加到条件变量conditionedVariables中,这就是一个简化的过程,也就是题目所想表达的归一化。
至于为什么要选择长度为1的,是因为在变量域variableDomainsDict里,包含了我们上述所提到的非条件变量和条件变量,但是变量域只有一个条目,也就是非条件变量和条件变量不能同时取相同的值,否则就要简化。
除此之外,还需要注意题目所给的初始条件:
1、返回一个新因子,其中表中所有概率的总和为 1;
2、如果输入因子中的概率总和为 0,则应返回 None;
在解决本题的时候,我也犯了上一题一样的错误,已将错误做法进行注释,以下是本题全部代码:
def normalize(factor):
"""
Question 5: Your normalize implementation
Input factor is a single factor.
The set of conditioned variables for the normalized factor consists
of the input factor's conditioned variables as well as any of the
input factor's unconditioned variables with exactly one entry in their
domain. Since there is only one entry in that variable's domain, we
can either assume it was assigned as evidence to have only one variable
in its domain, or it only had one entry in its domain to begin with.
This blurs the distinction between evidence assignments and variables
with single value domains, but that is alright since we have to assign
variables that only have one value in their domain to that single value.
Return a new factor where the sum of the all the probabilities in the table is 1.
This should be a new factor, not a modification of this factor in place.
If the sum of probabilities in the input factor is 0,
you should return None.
This is intended to be used at the end of a probabilistic inference query.
Because of this, all variables that have more than one element in their
domain are assumed to be unconditioned.
There are more general implementations of normalize, but we will only
implement this version.
Useful functions:
Factor.getAllPossibleAssignmentDicts
Factor.getProbability
Factor.setProbability
Factor.unconditionedVariables
Factor.conditionedVariables
Factor.variableDomainsDict
"""
# typecheck portion
variableDomainsDict = factor.variableDomainsDict()
for conditionedVariable in factor.conditionedVariables():
if len(variableDomainsDict[conditionedVariable]) > 1:
print("Factor failed normalize typecheck: ", factor)
raise ValueError("The factor to be normalized must have only one " + \
"assignment of the \n" + "conditional variables, " + \
"so that total probability will sum to 1\n" +
str(factor))
"*** YOUR CODE HERE ***"
# If the sum of probabilities in the input factor is 0,
# you should return None.
unconditionedVariables=[]
conditionedVariables=[]
variableDomainsDict=[]
unconditionedVariables=list(factor.unconditionedVariables())
conditionedVariables=factor.conditionedVariables()
variableDomainsDict=factor.variableDomainsDict()
SumOfProbability=0
for assignment in factor.getAllPossibleAssignmentDicts():
SumOfProbability+=factor.getProbability(assignment)
if SumOfProbability==0:
return None
# Because:all variables that have more than one element in their domain are assumed to be unconditioned
# So:Traverse into the unconditionedVariables,if the length==1 ,add to the conditionedVariables
for unconditioned in unconditionedVariables:
if len(variableDomainsDict[unconditioned])==1:
conditionedVariables.add(unconditioned) #add()是加到末尾,不用append()
# ATTENTION:Normalize:value is single
# if unconditioned not in conditionedVariables:
# unconditionedVariables.append(unconditioned)
unconditionedVariables=[unconditioned for unconditioned in unconditionedVariables
if unconditioned not in conditionedVariables]
newFactor=Factor(unconditionedVariables,conditionedVariables,variableDomainsDict)
for assignment in newFactor.getAllPossibleAssignmentDicts():
probability=factor.getProbability(assignment)
newFactor.setProbability(assignment,probability/SumOfProbability)
return newFactor
"*** END YOUR CODE HERE ***"

Question 6:Variable Elimination
本题需要实现inference.py中inferenceByVariableEliminationWithCallTracking()下的inferenceByVariableElimination()函数,以实现变量消除。
在完成本题之前,先对题目所提供的提示函数含义进行详细理解。
| Functions | Explanation |
|---|---|
| BayesNet.getAllCPTsWithEvidence() | 返回所有条件概率表 |
| normalize() | Question 5:归一化 |
| eliminate() | Question 4:消除 |
| joinFactorsByVariable() | 连接包含变量的所有因子(以便自动分级器识别您执行了正确的连接交错和消除) |
| joinFactors() | Question 3:连接因子 |
再来对本函数的参数进行简单了解:
inferenceByVariableElimination(bayesNet, queryVariables, evidenceDict, eliminationOrder)
| Parameters | Explanation |
|---|---|
| bayesNet | 我们在其上进行查询的贝叶斯网络 |
| queryVariables | 推理查询中无条件的变量列表 |
| evidenceDict | 在推理查询中作为证据(条件)呈现的变量的赋值字典 {variable : value} |
| eliminationOrder | 消除变量的顺序 |
说在前面:此函数应执行返回因子的概率推理查询:P(queryVariables | evidenceDict)。
factorOperations.py中的joinFactorsByVariable()函数有两个参数:输入的因子列表factor以及要加入的变量joinVariable。此函数会检查被连接的变量是否仅在一个输入因子中显示为无条件变量。然后对包含该变量的因子中的所有因子调用 joinFactors,最后返回一个未加入的、由 joinFactors 产生的元组。
Question 6调用了Question 3 & 4 & 5所实现的函数,并结合了Question 4 & 5,用joinFactorsByVariable()构造newFactor,如之前一般判断无条件变量newFactor.unconditionedVariables()的长度是否为1。如果只有一个无条件变量,即长度为1的话直接丢弃,不用于消除。
结合factorOperations.py里的joinFactorsByVariable()函数,这个函数正是要实现本题,去连接包含变量的所有factor,来看是否执行了正确的连接交错和消除。因为需要返回P(queryVariables | evidenceDict),所以根据题目给的函数:BayesNet.getAllCPTsWithEvidence(),去获得所有的条件概率表,即factors列表,然后通过我刚提到的函数joinFactorsByVariable()的定义进行判断,最后归一化,执行normalize()函数。
注:枚举推理首先连接所有变量,然后消除所有隐藏变量。相反,变量消除通过迭代所有隐藏变量来交错连接和消除,然后在继续之前对单个隐藏变量执行连接和消除到下一个隐藏变量。 所以要在消除的过程中进行变量的连接。
def inferenceByVariableEliminationWithCallTracking(callTrackingList=None):
def inferenceByVariableElimination(bayesNet, queryVariables, evidenceDict, eliminationOrder):
"""
Question 6: Your inference by variable elimination implementation
This function should perform a probabilistic inference query that
returns the factor:
P(queryVariables | evidenceDict)
It should perform inference by interleaving joining on a variable
and eliminating that variable, in the order of variables according
to eliminationOrder. See inferenceByEnumeration for an example on
how to use these functions.
You need to use joinFactorsByVariable to join all of the factors
that contain a variable in order for the autograder to
recognize that you performed the correct interleaving of
joins and eliminates.
If a factor that you are about to eliminate a variable from has
only one unconditioned variable, you should not eliminate it
and instead just discard the factor. This is since the
result of the eliminate would be 1 (you marginalize
all of the unconditioned variables), but it is not a
valid factor. So this simplifies using the result of eliminate.
The sum of the probabilities should sum to one (so that it is a true
conditional probability, conditioned on the evidence).
bayesNet: The Bayes Net on which we are making a query.
queryVariables: A list of the variables which are unconditioned
in the inference query.
evidenceDict: An assignment dict {variable : value} for the
variables which are presented as evidence
(conditioned) in the inference query.
eliminationOrder: The order to eliminate the variables in.
Hint: BayesNet.getAllCPTsWithEvidence will return all the Conditional
Probability Tables even if an empty dict (or None) is passed in for
evidenceDict. In this case it will not specialize any variable domains
in the CPTs.
Useful functions:
BayesNet.getAllCPTsWithEvidence
normalize
eliminate
joinFactorsByVariable
joinFactors
"""
# this is for autograding -- don't modify
joinFactorsByVariable = joinFactorsByVariableWithCallTracking(callTrackingList)
eliminate = eliminateWithCallTracking(callTrackingList)
if eliminationOrder is None: # set an arbitrary elimination order if None given
eliminationVariables = bayesNet.variablesSet() - set(queryVariables) - \
set(evidenceDict.keys())
eliminationOrder = sorted(list(eliminationVariables))
"*** YOUR CODE HERE ***"
factors = bayesNet.getAllCPTsWithEvidence(evidenceDict)
for elimination in eliminationOrder:
factors, newFactor = joinFactorsByVariable(factors, elimination)
# Solve as before
if len(newFactor.unconditionedVariables()) > 1:
tmpFactor = eliminate(newFactor, elimination)
factors.append(tmpFactor)
resFactor = joinFactors(factors)
# the last step:to normalize
return normalize(resFactor)
"*** END YOUR CODE HERE ***"
return inferenceByVariableElimination

Submission
python submission_autograder.py
–2021/10/09 (Question 1 to Question 3)
ERROR - Download failed: HTTP Error 403: Forbidden
目前暂时无法提交,正在尝试GitHub提交给GradeScope的方法。
–2021/10/20(Question 4 to Question 6)
还是不行,先暂时不提交了~/:-)
Conclusion
–2021/10/09(Question 1 to Question 3)
本次实习在一开始的准备上花了很多时间,由于不知道报错如何解决,整个人一头雾水,几乎要把整个浏览器翻遍,试完所有的办法,但是仍旧没辙。最后一步一步扎实做,也算是解决了,且感觉很满足,有一种“山重水复疑无路,柳暗花明又一村”的真实体会。实际上在最开始的时候,光是题目意思我就花了很长的时间去阅读并理解,虽然不难,但是需要从头到尾梳理贝叶斯网络的基本内容以及相关概念,这是一件需要用心去做的事情。
–2021/10/20(Question 4 to Question 6)
Q4-Q6于我而言还是很难的,而且有许多内容绕来绕去的有些分辨不清,导致我在测试的时候出现了问题。对于归一化,在梳理了其与标准化standardization的区别之后,更好地运用进来,也让我对归一化的记忆更为深刻。在完成Q6的时候,由于题目说明的繁杂,和需要结合的函数数量较多,我不得不从头看起,梳理脉络。
Reference
1、安装、升级pip,但是python -m pip install --upgrade pip报错的解决办法
2、Python中append和+以及extend的区别
3、NickLai169/CS188-Project4-bayesNets
4、MattZhao/cs188-projects/P4 Bayes Nets
5、归一化(normalization)、标准化(standarization)