from sklearn.model_selection import cross_val_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=pd.read_csv('balance.dat',sep=',')
print(data)
bool_data_L=data[" Class"]==" L"
bool_data_R=data[" Class"]==" R"
print(bool_data_L)
data_L=data.loc[bool_data_L]
print(data_L)
data_R=data.loc[bool_data_R]
print(data_R)
df_final = pd.concat([data[bool_data_L], data_R])
print(df_final)
使用contact对Dataframe类型进行合并操作,其中我对concat函数的使用有了进一步的了解,就是concat的第一个参数要求需要是pandas模块的一个参数迭代,换言之,就是下行代码只能这样写,而不能使用两个Dataframe直接进行合并,否则就会报错,报错结果如下:
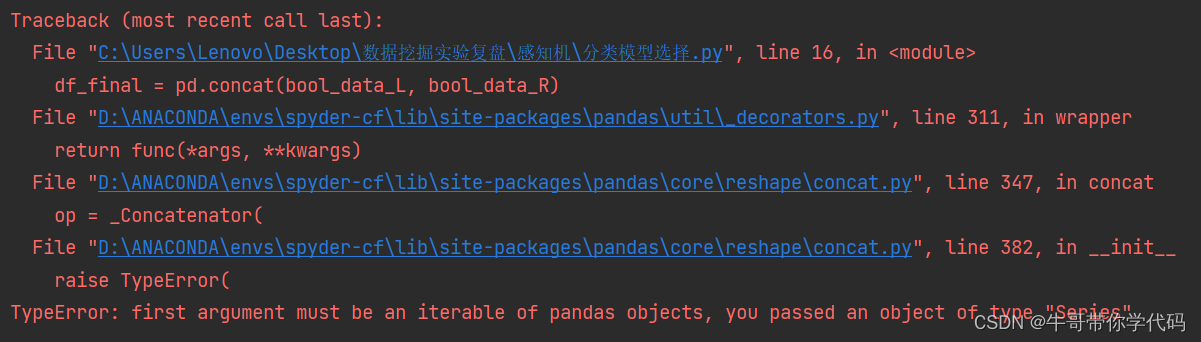
若直接改为下一行代码则不会出现类似情况。
df_final = pd.concat([data[bool_data_L], data_R])因为第一个参数属于pandas对应的对象而不是Series或者Dataframe对象。