Boston房价数据是R语言中一类重要的数据,常被用来做各种方法分析,即它是波士顿不同地区的506个家庭住房信息,其中包括影响房价的14个因素如城镇的人均犯罪率、氮氧化合物浓度、城镇黑人的比例、低教育程度的人口比例等,而且每个因素对房价的影响都是不同显著程度的,因此,本文对Boston房价数据进行多元线性回归,运用R语言中一些函数对数据进行分析,筛选出对房价影响程度比较显著的因素,从而建立正确的回归模型。
线性回归模型
线性回归模型是众多回归模型中最常见、最基础的一类模型,因此,在我们数据分析、模型建立过程中都起到了非常重要的作用,基于该模型的研究也是十分重要的课题。下面对该模型进行简单的阐述。线性回归模型从自变量个数来说,分为两种:一种是一元线性回归模型,另一种是多元线性回归模型,顾名思义,一元线性回归模型是指在回归分析中有且仅有一个自变量和一个因变量,并且两者是近似呈线性关系的;多元线性回归模型是指在回归分析中有多个(两个及两个以上)自变量和一个因变量,并且因变量与自变量之间的关系是近似呈线性关系的。
1.多元线性回归模型

2.线性回归模型中参数估计
一般地我们采用最小二乘估计,所谓最小二乘估计,就是寻找参数的估计值,使其离差平方和达到极小值,即寻找满足:

3.显著性检验
在我们将线性回归模型中的系数估计出来之后,我们不知道模型估计的效果如何,尤其是在实际问题中。因此,我们要对回归方程和回归系数进行显著性检验。在实际问题中,起初我们是不知道因变量y与自变量之间是线性还是非线性关系,当我们建立了线性回归模型,这也就意味着我们假设它们之间的关系是线性的,但也有可能它们之间的关系是非线性的,因此我们在求出经验回归方程以后要对回归方程进行显著性检验。

4.Boston房价数据分析
本节选取Boston房价数据,Boston房价数据是波士顿不同地区的506个家庭住房信息,其中包括决定房价的多种因素。Boston房价数据共有506个观测样本、14个变量,其中各个变量的解释如下:

结果分析:
首先,识别数据中有没有缺失值,根据R语言中语句is.na( ),结果可以看出,数据中是没有缺失值的。多元线性回归要求自变量与因变量存在线性关系,故我们利用散点图和相关 系数图来判断自变量与因变量之间存在的关系,使之后可以更好地建立模型。其中散点图和相关系数图分别如下的图1和图2、3,方阵散点图看着比较费劲,而且很难看出来各个变量之间的影响程度,因此,可以观察各变量的相关性矩阵系数图,有图3

图 1 散点图

图 2 相关系数矩阵图
其中蓝色表示两个变量呈正相关,红色表示变量呈负相关。色彩越深,表示变量相关性。
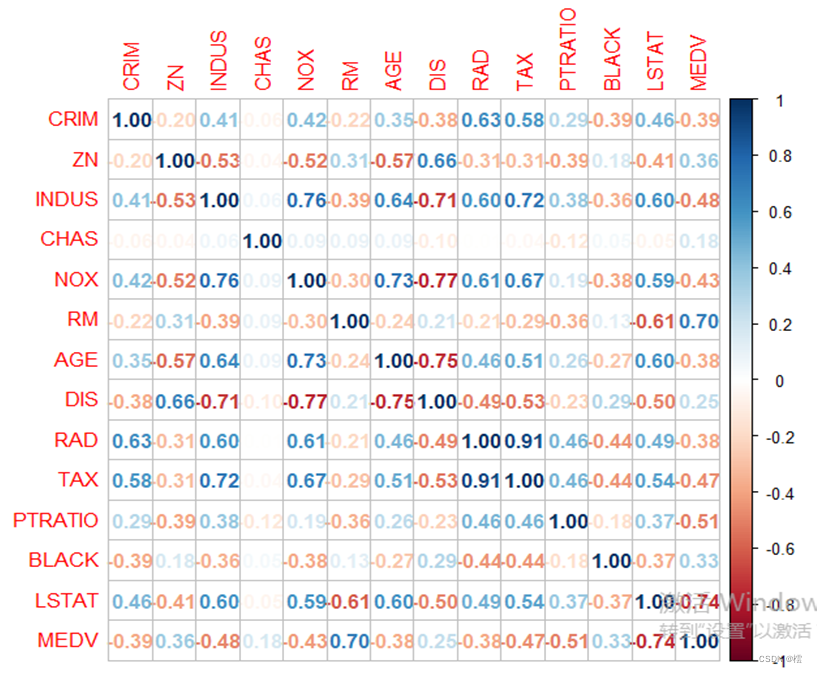
图 3 相关系数矩阵图
由上相关系数图可以看出,每个变量和每个变量之间都有相关性,不过是相关系数大小的问题,也代表各个变量之间相互影响的强弱关系。同时可以看出变量CHAS与其他变量的相关系数大概都在0.1左右,说明影响不大,因此,在以下的研究以及建立模型时不考虑变量CHAS,即只研究其他12个变量对MEDV的影响程度。接下来,利用R软件具体的给出其余每个变量对MEDV的影响程度,并建立准确的回归方程。
第一步:用lm语句建立普通的回归方程,并用summary显示各个变量对MEDV的显著性,其中,一般情况下,p值在0~0.001之间是非常非常显著,通常用’***’号表示;在0.001~0.01之间是非常显著,通常用‘**’号表示;在0.01~0.05之间是比较显著,通常用‘**’号表示;在0.05~0.1之间是显著,通常用‘.’号表示;在0.1~1之间是不显著,直接用’ ’表示,运行结果如下:
结果分析:根据运行结果可以看出,回归模型为
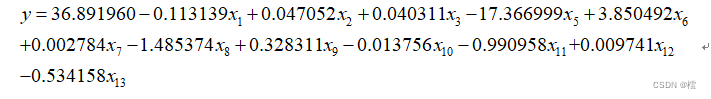

p值为2.2e-16小于0.05,拒绝原假设,认为这CRIM等12个变量对MEDV是有影响的,拟合系数R²=0.7291,详细来看,除了INDUS、AGE之外其他的变量都是非常显著的,这表明其他变量对MEDV有很强的影响。
第二步:进一步,运用car包中的influencePlot( )函数可以将离群点、杠杆值和强影响点的信息整合到一幅图形中,并用outlierTest( )函数检测数据中的异常值点。

图 4离群点、杠杆值和强影响点

如图4所示,纵坐标超过+2或小于-2的样本可被认为是离群点,水平轴超过0.2或0.3的样本有高杠杆值,圆圈大小与影响成比例,圆圈很大的点可能是强影响点,因此,用outlierTest( )函数找到具体异常值,结果如下:

第三步:将第二步找出的异常值点删除,进行拟合,则
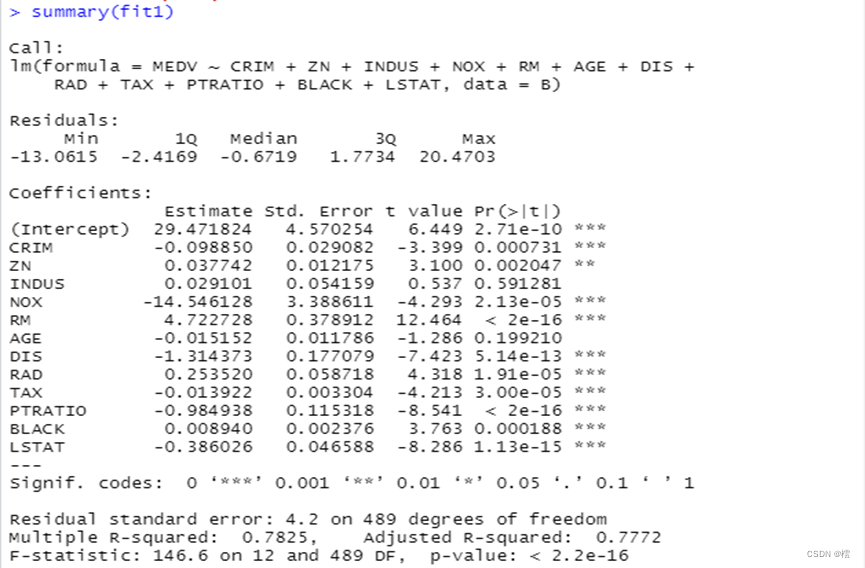
由结果可以看出,删除异常值后,变量中还有不显著的,说明我们删除异常值后对结果影响不大,但是R²相较未删除时值增大了,即R²=0.7825,回归方程为:
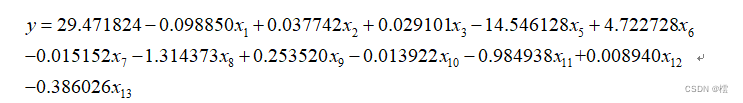
第四步:运用vif( )函数检查数据中的共线性,当vif值大于4时表明存在多重共线性,运行结果为:

上述结果显示,NOX,RAD,TAX的vif值大于4,存在多重共线性,因此,要进行变量筛选。
第五步:变量选择,使用全子集回归:
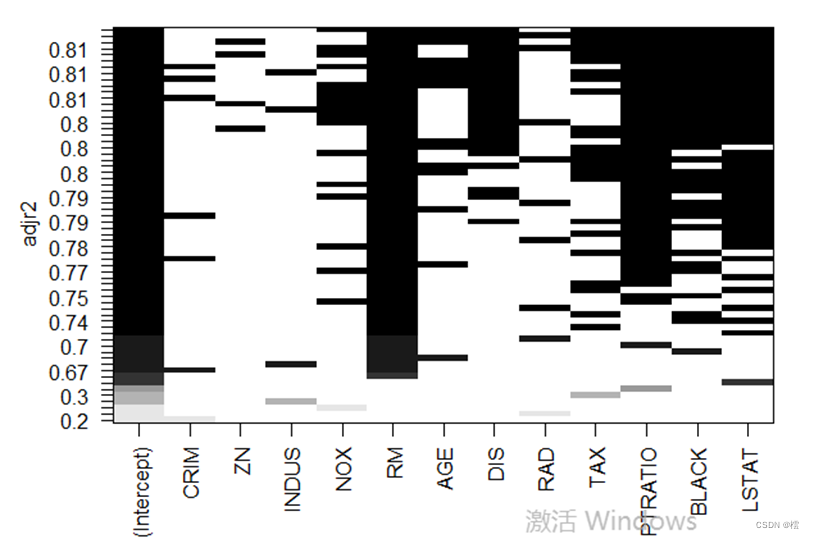
从图5可以看出,CEIM,ZN,INDUS,RAD影响不大,因此将这四个变量进行删除,然后将删除后的数据重新进行拟合,结果如下:
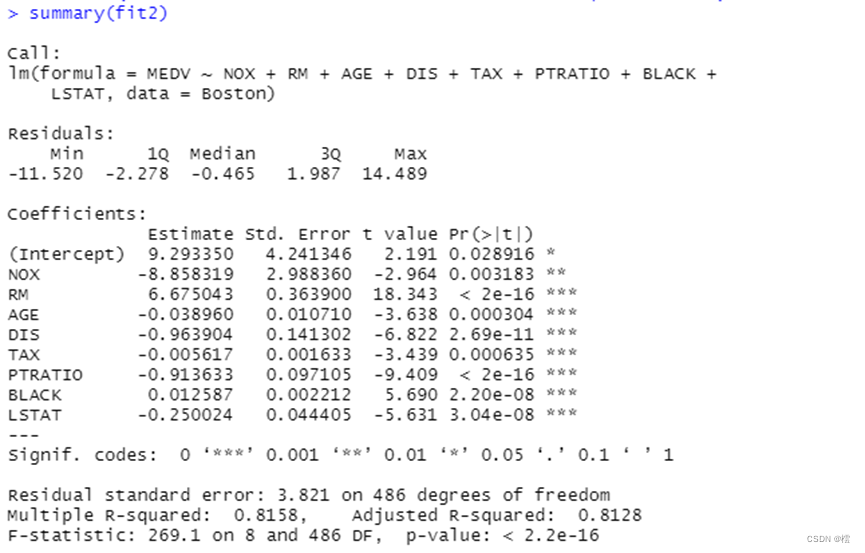
上述结果显示,删除变量后,p值为2.2e-16小于0.05,拒绝原假设,认为NOX等8的变量对MEDV影响均显著,且调整后的R²=0.8158,这表明我们的调整是有效的,即回归方程为:
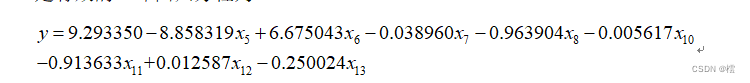
第六步:回归诊断
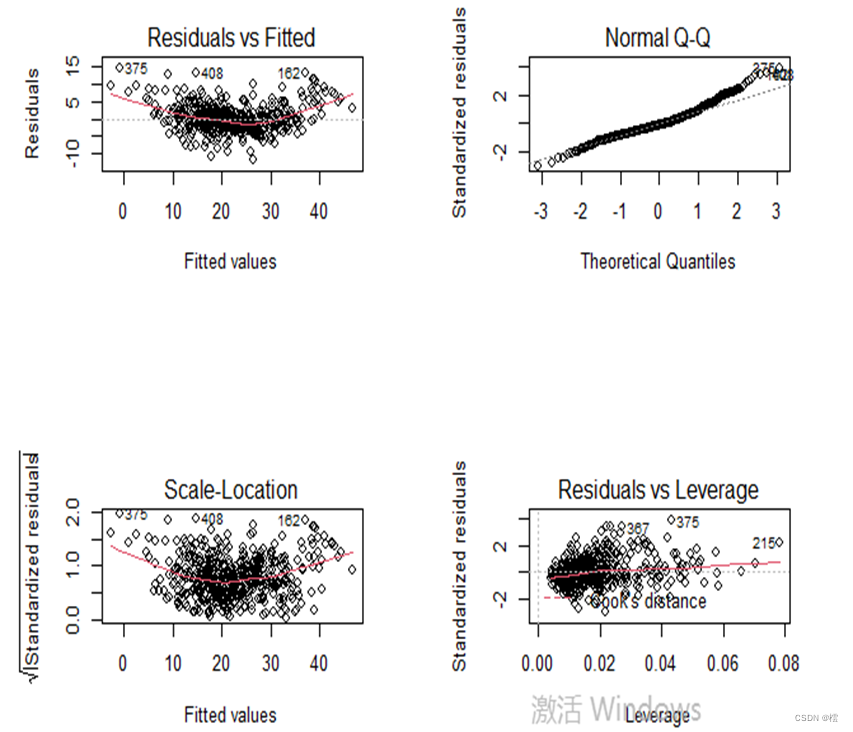
通过图6中“残差拟合图”可以发现,残差值与拟合值存在一个曲线关系,因此回归模型不满足线性假设;通过“正态Q-Q图”发现,显然,图上的点基本落在呈45度角的直线上,因此回归模型是满足正态性的;通过“位置尺度图”可以看出,图形显示非水平趋势,那么就表明回归模型不满足同方差性。
第七步:接下来通过变量与房价中位数的散点图和核密度估计曲线判断变量之间的关系,然后进行变量变换,改善模型效果。

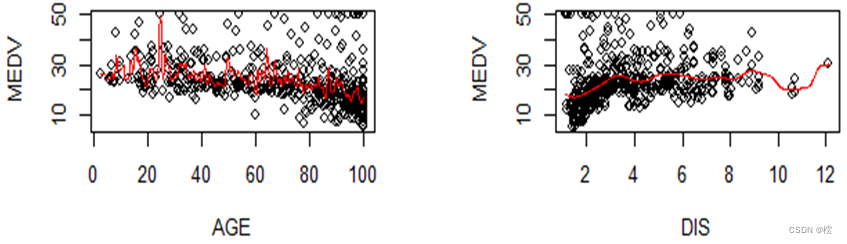
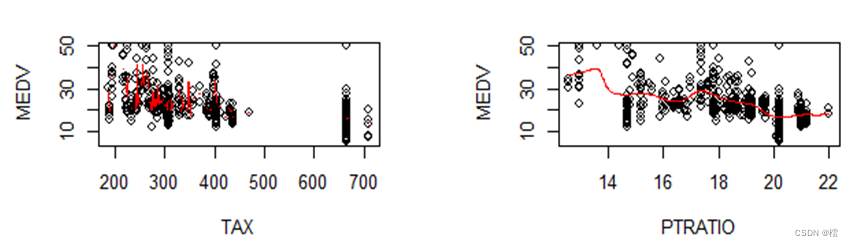
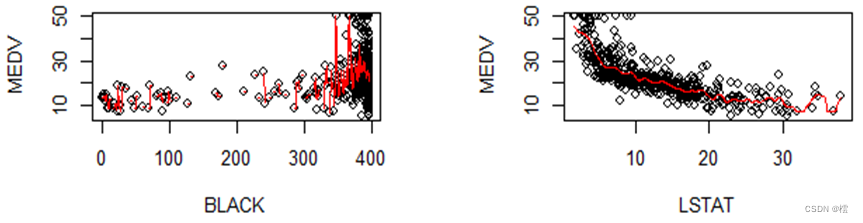
图7结果显示,RM与MEDV可能存在二次相关,LSTAT与MEDV可能存在倒数相关,其它变量与MEDV的相关程度不明显。
第八步:重新建立回归模型,在原有模型基础上添加RM²与1/LSTAT两项,结果如下:
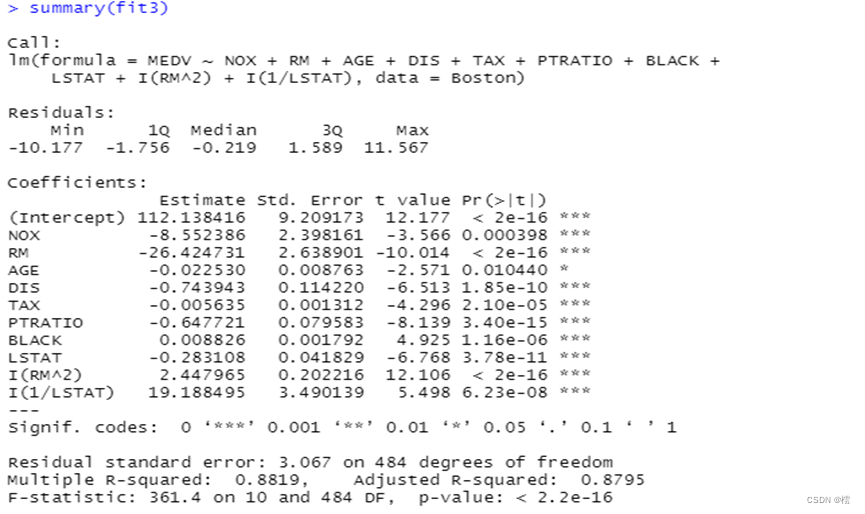
由检验结果可知,p值为2.2e-16,拒绝原假设,同时模型的调整R²=0.8819,拟合优度有了明显的提升,且各个变量对房价MEDV影响均显著,结合模型的回归系数与散点图发现,影响房价的主要因素是房屋房间数(RM)和人口中地位较低者(LSTAT)的比例;房间数越多,房价越高,且呈指数式增长;人口中地位较低者的比例越高,人均可支配收入越低,房价越低;与波士顿五个中心区域的加权距离(DIS)越远的地段的房价也越低;一氧化氮浓度(NOX)较低的地区房屋分布较多,房价也较高。师生比例(PTRATIO)偏高的地区房屋价格较低,教师资源不足地区,房价也越高;房产税(TAX)偏高的地区房价较低,但该变量对房价的影响较小。
第九步:最终的回归模型为:
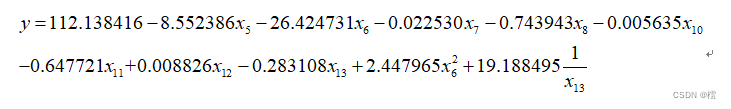
代码:
install.packages("corrplot")
library(car)
library(corrplot)
boston<-read.csv("F:/boston.data.CSV")
attach(boston)
#识别缺失值
is.na(boston)
#方阵散点图
scatterplotMatrix(boston,smoother=F)
#相关系数矩阵图
mycor<-cor(boston)
corrplot(mycor, method = "shade", shade.col = NA, tl.col ="black", tl.srt = 45, order = "AOE")
datacor<- cor(boston)
corrplot (datacor, method ="number")
#拟合
fit<-lm(MEDV~CRIM+ZN+INDUS+NOX+RM+AGE+DIS+RAD+TAX+PTRATIO+BLACK+LSTAT,data=boston)
summary(fit)
#删除异常值
influencePlot(fit, id. method="identify", main="Influence Plot", sub="Circle size is proportional to Cook's distance")
outlierTest(fit)
#删除异常值后重新拟合
Boston<- boston[-c(366,369,373,381,419,372,370,371,368,413,365),]
fit1<-lm(MEDV~CRIM+ZN+INDUS+NOX+RM+AGE+DIS+RAD+TAX+PTRATIO+BLACK+LSTAT,data=Boston)
summary(fit1)
#多重共线性
vif(fit)
#筛选变量
library(leaps)
leaps<-regsubsets(MEDV~CRIM+ZN+INDUS+NOX+RM+AGE+DIS+RAD+TAX+PTRATIO+BLACK+LSTAT,data=Boston,nbest=8)
plot(leaps, scale="adjr2")
#删除变量
fit2<-lm(MEDV~NOX+RM+AGE+DIS+TAX+PTRATIO+B+LSTAT, data=Boston)
summary(fit2)
#回归诊断
par(mfrow=c(2,2))
plot(fit2)
#变量与房价中位数的散点图和核密度估计曲线判断变量之间的关系
par(mfrow=c(1,1))
plot(NOX,MEDV)
lines(ksmooth(NOX,MEDV, bandwidth =1,kernel = "normal"), col="red")
plot(RM,MEDV)
lines(ksmooth(RM,MEDV, bandwidth =1,kernel = "normal"), col="red")
plot(AGE,MEDV)
lines(ksmooth(AGE,MEDV, bandwidth =1,kernel = "normal"), col="red")
plot(DIS,MEDV)
lines(ksmooth(DIS,MEDV, bandwidth =1,kernel = "normal"), col="red")
plot(TAX,MEDV)
lines(ksmooth(TAX,MEDV, bandwidth =1,kernel = "normal"), col="red")
plot(PTRATIO,MEDV)
lines(ksmooth(PTRATIO,MEDV, bandwidth =1,kernel = "normal"), col="red")
plot(BLACK,MEDV)
lines(ksmooth(BLACK,MEDV,bandwidth =1,kernel = "normal"),col="red")
plot(LSTAT,MEDV)
lines(ksmooth(LSTAT,MEDV, bandwidth =1,kernel = "normal"), col="red")
#重新建立准确的模型
fit3<-lm(MEDV~NOX+RM+AGE+DIS+TAX+PTRATIO+BLACK+LSTAT+I(RM^2)+I(1/LSTAT),data=Boston)
summary(fit3)