1.引言
在图神经网络中,我们怎么去做一个注意力机制?
就比如我们这个图中,就5个节点,每一个节点的邻居对自身的重构影响肯定不一样。
2号和3号点对1号点的重构贡献一样大,肯定就没意义了。
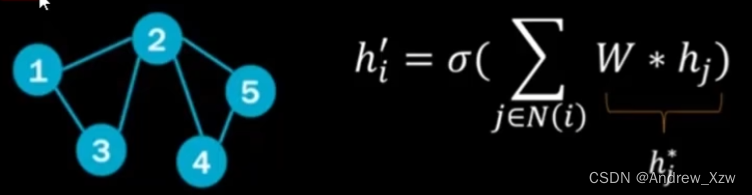
传统GNN,就是邻接矩阵×特征向量,再×一个可训练的参数权重矩阵,就得到了重构特征(特征聚合)。
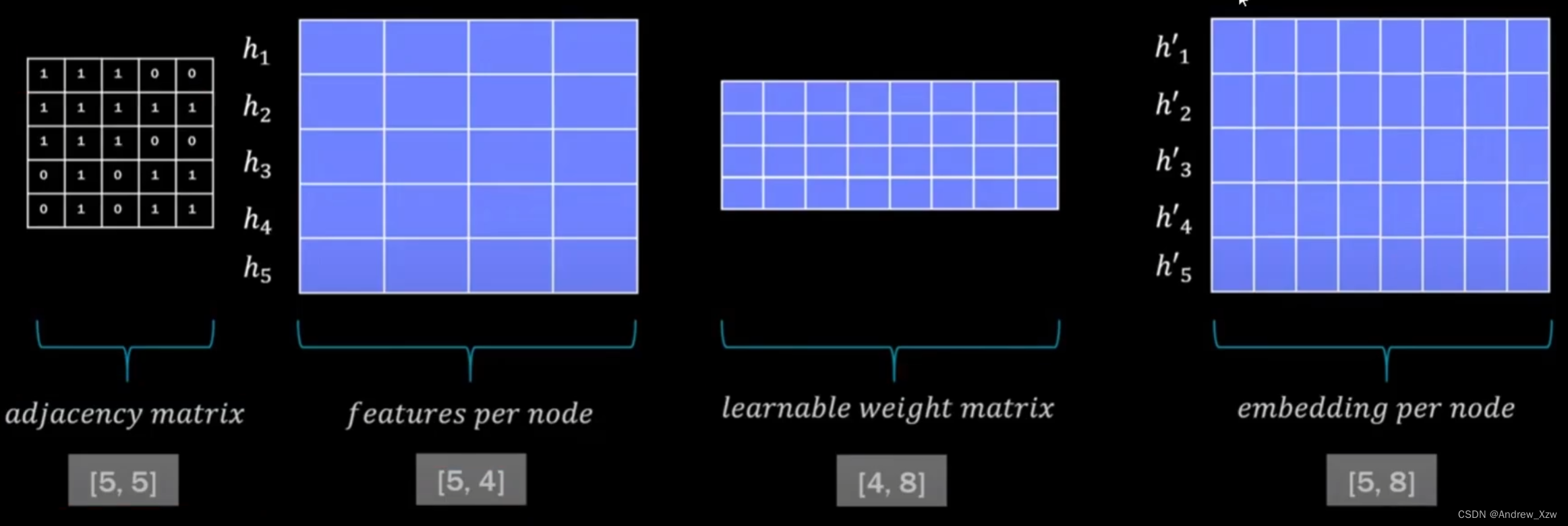
图注意力机制,在特征聚合的操作时,把特征的重要性考虑进去。
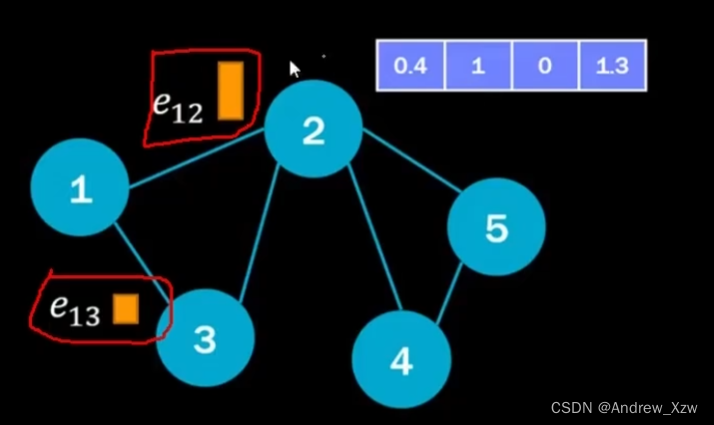
1号和2号的边,1号和3号的边,分别计算权重是多少。比如e12是0.8,e13是0.2。这样就知道,在重构1号特征时,就知道更多地关注2点,更少地关注3点。
其实就是在传统GNN的流程,再加上一个权重项。可以当作是把“边”加上一个权重。
2.求权重
求权重有很多种方法:
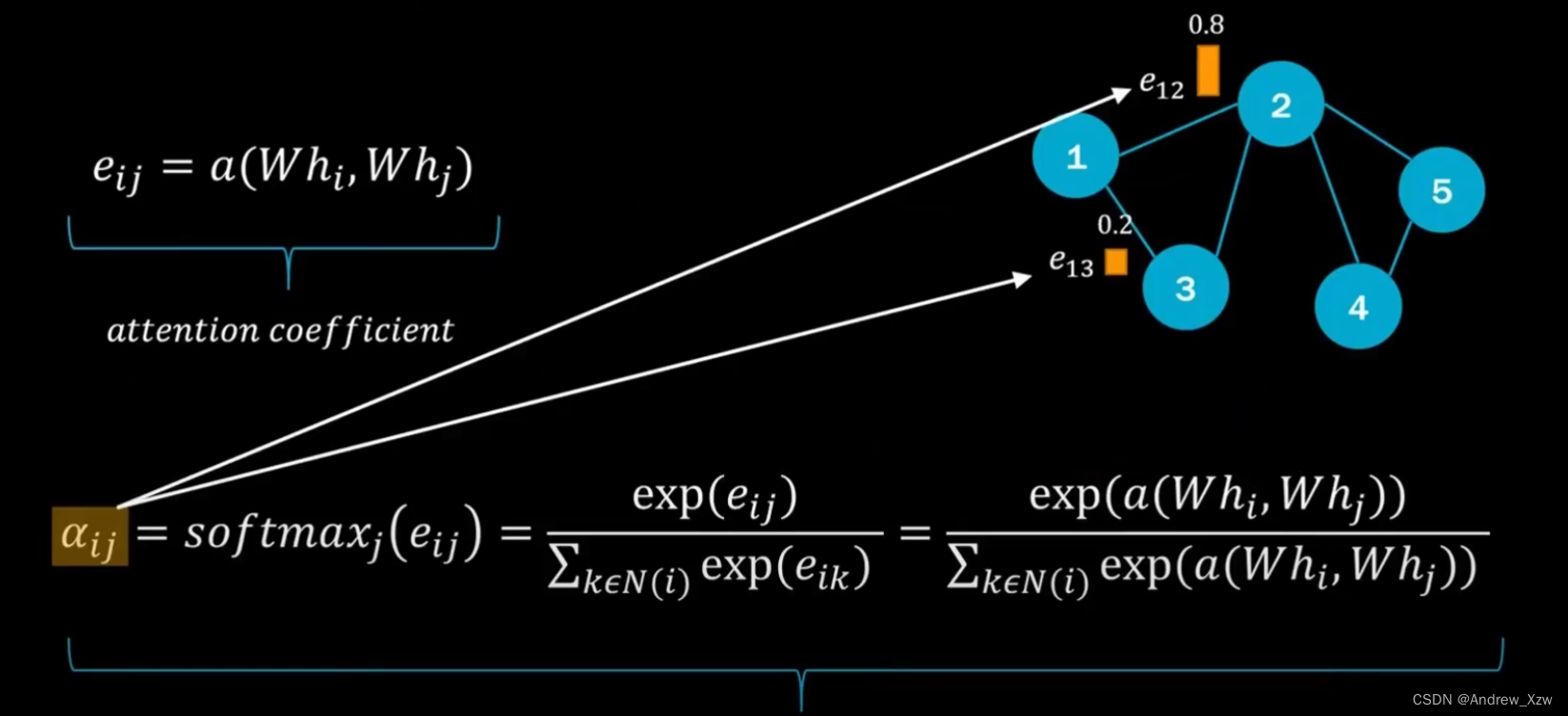
2.1 内积+softmax
比如,想算1号点和2号点之间的关系,hi,hj,就是i=1,j=2,代表是1号和2号点的特征。W是可训练的权重参数,对特征进行一个维度映射。
Whi,Whj还是两个向量,做向量内积,可以得到权重值。

最后,关键就是这个a(attention)怎么计算。
softmax的目的就是,让和自身相关的所有边的权重值和为1。
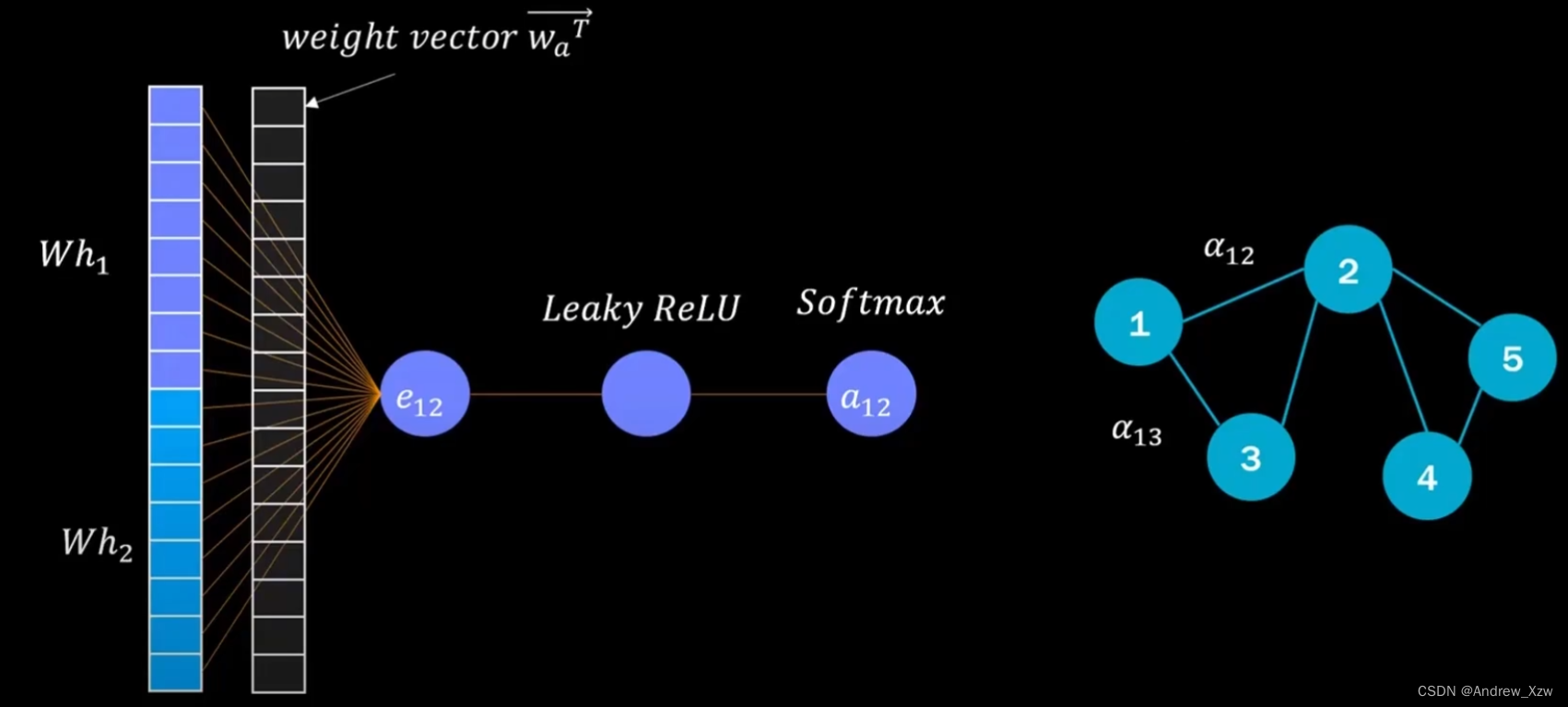
2.2 特征映射×可训练权重矩阵+softmax
1号和2号点的特征h1和h2(假设初始维度为5),特征映射后(比如×一个5×8的矩阵),Wh1,Wh2。这里Wh1和Wh2拼接后,为16维的新特征。
这个时,我们不用向量内积的话,可以再加一个16×1的可训练参数矩阵。最后得到权重值。
Leaky Relu可以使得权重尽可能为正数;softmax使得最终所有和重构特征点的边权重和为1。
3.原理的本质
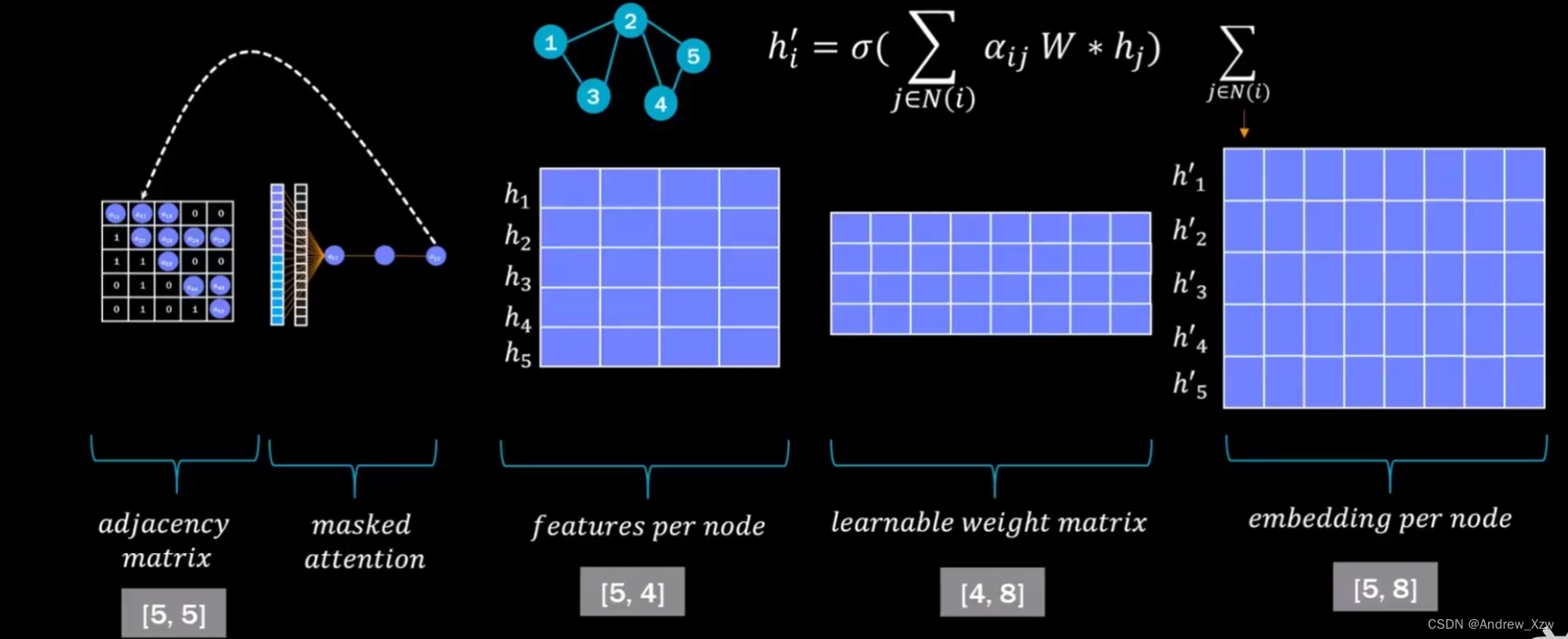
本质其实就是对“邻接矩阵”做了加权。Attention其实是对“邻接矩阵”做重构。
比如之前的邻接矩阵,除了自身,和其他相关联的邻居点,都为1,是不是就相当于默认每个邻居对自己重构的贡献一样大。

如果,说加了Attention机制后,相关联的邻居变成了相对应的权重。比如0.8和0.2。网络自然就知道哪个点的贡献更大了。

整个GNN的流程,输入特征向量,可训练权重参数矩阵都没变。只是对邻接矩阵做了变换。
用我们上面讲到的计算得到的权重,去邻接矩阵中对应位置进行相乘。这样使用加了权重的新邻接矩阵×特征向量进行重构后,就不是每个邻居都是1了,就知道哪个点对自身的重构贡献更大了。
4.计算流程
1号点只和2号、3号点有关系。输入特征h1,h2,h3。×一个可训练权重参数矩阵,进行特征映射。Wh1,Wh2,Wh3。最后×每一个边求得的权重值。
