总体网络结构图
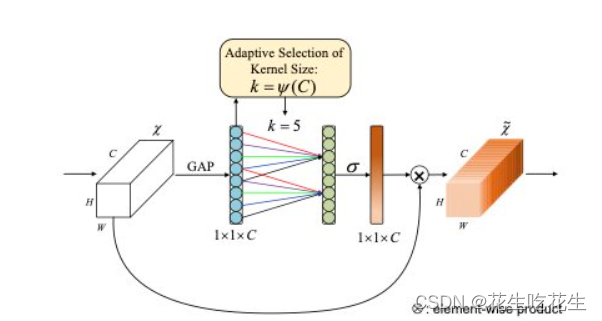
- 输入特征图,首先经过全局平均池化,将h和w维度都变成1,只保留channel维度,那么特征图就被拉成长条状,
- 经过1D卷积,使得每层的channel于相邻层的channel进行信息交互,共享权重。
- 使用Sigmoid进行处理。
- 将输入特征图与处理好的特征图权重进行相乘,那么权重就会加在特征图上了。
代码
使用pytorch进行编写:
from numpy import pad
import torch
import torch.nn as nn
import math
"""
ECA注意力机制,和SE注意力主要的区别是避免降维,减少了参数数量的增加。
提出了一种自适应卷积核的1D卷积。在通道之间进行信息交互,获取信息。
步骤:全局平均池化-》1D卷积-》Sigmoid激活-》输出
"""
class ECA(nn.Module):
def __init__(self, channel, gamma=2, b=1):
super(ECA, self).__init__()
# 计算卷积核大小
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
# 计算padding
padding = kernel_size // 2
self.avg = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(
1, 1, kernel_size=kernel_size, padding=padding, bias=False
)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
y = self.avg(x).view([b, 1, c])
y = self.conv(y)
y = self.sig(y).view([b, c, 1, 1])
out = x * y
return out
model = ECA(8)
model = model.cuda()
input = torch.randn(1, 8, 12, 12).cuda()
output = model(input)
print(output.shape) # (1, 8, 12, 12)