句和文档的embedding
链接: 数据集 提取码: 6cgu
《Distributed Representations of Sentences and Documents》
—句子和文档的分布式表示学习
作者:Quoc Le and Tomas Mokolov
单位:Google
发表会议及时间:ICML 2014
一 论文导读
- 句子分布式表示简介
- 句子分布式表示相关方法
- 前期知识
1. 句子分布式表示简介
- 句子分布式表示:句子的分布式表示就是将一句话或者一段话(这里将句子和文档同等看待,文档相当于较长的句子)用
固定长度的向量表示 - 意义:如果能够用一个向量准确地表示一句话,那么可以直接能够用这个向量用于文本分类、信息检索、机器翻译等等领域
如下图所示:

2. 句子分布式表示相关方法
一 历史模型:
1 基于统计的句子分布式表示方法:
- Bag-of-words
- Bag-of-n-grams
2 基于深度学习的句子分布式表示
- 加权平均法
- 深度学习模型
(1)Bag of words
算法:
- 构建一个词表,词表中每个元素都是一个词
- 对于一句话s,统计词表中每个词在s中出现的次数
- 根据词表中每个词在s中出现的次数,构造一个词表大小的向量
实例图下:

思考:Bag-of-words 的缺点,如何改进
(2)对于Bag-of-n-gram,词表中的元素可以为词也可以为n-gram短语
(3)加全平均法:
算法:
- 构建词表,词表中每个元素都是词
- 使用词向量学习方法(skip-gram等)学习每个词的词向量表示
- 对于句子s中的每个词(w1,w2,w3,…,wn)对应的词向量(e1,e2,e3,…,en)加权平均,结果为句子的分布式表示:
(下图公式只有平均,没有加权)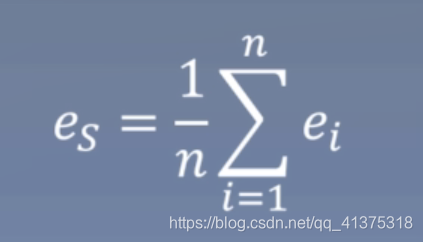
(4)深度学习方法:
算法:
- 构建词表,词表中每个元素都是词
- 使用词向量学习方法(skip-gram等)学习每个词向量表示
- 将句子s中的每个向量作为输入送进深度神经网络模型(CNN或RNN),然后通过监督学习,学习每个句子的分布式表示。
模型一般形式如下图,在concatenation部分将句子的每个词进行了加权平均得到了句子的分布式表示
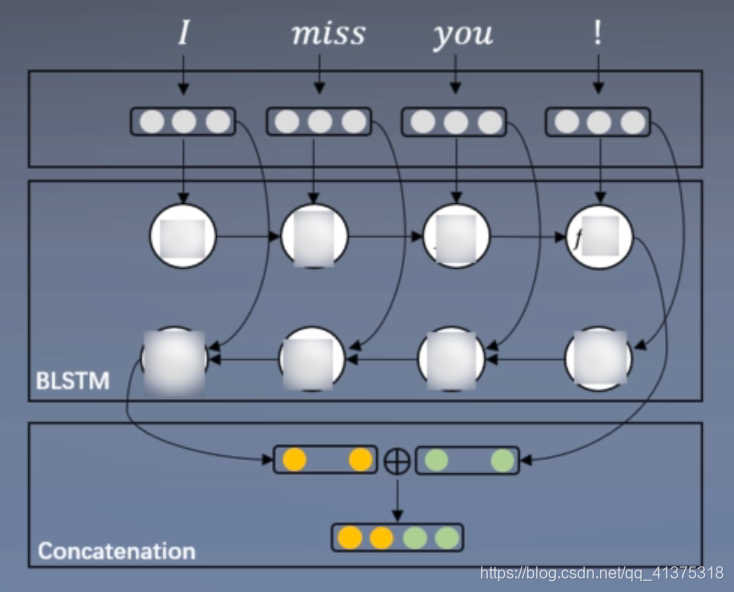
3. 前期知识
- 熟悉词向量的相关知识
- 了解使用语言模型训练词向量的方法
训练模型如下图: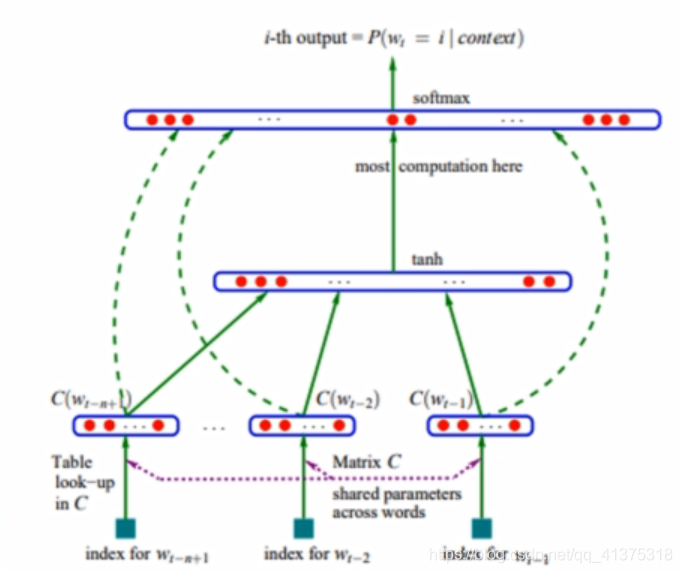
二 论文精读
- 论文整体框架
- 传统/经典算法模型
- 论文提出改进后的模型
- 实验结果
- 讨论和总结
1. 论文整体框架
0.摘要

1.介绍
2.句子分布式表示模型
3.实验
4.相关工作
5.结论
2. 传统/经典算法模型
-
Bag-of-words
其模型的缺点:
一 因为是词袋模型,所以丢失了词之前的位置信息
二 句向量知识单纯地利用了统计信息,而没有得到语义信息,或者只得到很少的语义信息 -
Bag-of-n-gram模型的缺点:
一 因为使用了n-gram,所以保留了位置信息,但是n-gram不会太大,最多是4-gram,所以保留的位置信息很少
二 N-gram同样没有学习到语义信息 -
加权平均法的缺点
对所有的词向量进行平均,丢失了词之前的顺序信息及词与词之间的关系信息 -
基于深度学习模型的缺点
只能使用标注数据训练每个句子的句向量,这样训练得到的向量都是任务导向的,不具有通用性 -
基于语言模型的词向量训练
语言模型:语言模型可以给出每个句子是句子的概率:
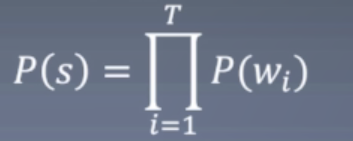
而每个词的概率定义成n-gram形式,即每个词出现只与前n-1个词有关:
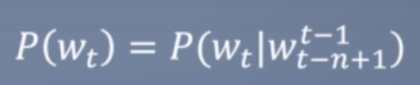
评价语言模型的好坏的指标困惑度(perplexity) -
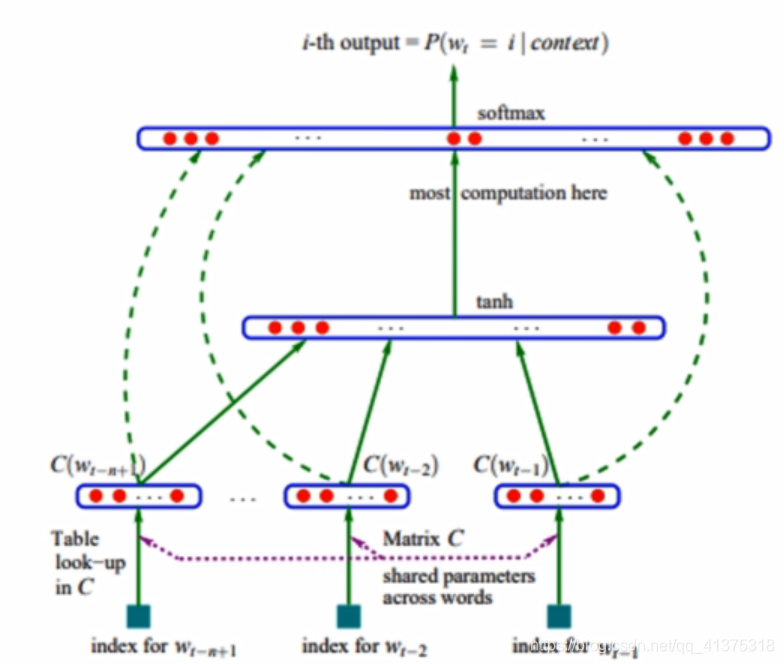
接下来就是基于语言模型的词向量训练
算法: -
对于每个词随机初始化一个词向量
-
取得一个连续的n-1个词,将n-1个词对应的词向量连接(concatenate)在一起形成向量e
-
将e作为输入,送入一个单隐层神经网络,隐层的激活函数为tanh,输出层的神经元个数为词表的大小
优点:就像原文提到的,即训练出一组词向量,又得到一个语言模型,其次不需要标注数据,可以使用很大的数据集
论文:《A Neural Probabilistic Language Model 》
3. 论文提出改进后的模型
本文的模型就是基于语言模型改进而来的分布式句向量训练模型。
算法:
- 类似于前面提到的基于语言模型的词向量训练模型,这里的句向量训练模型也是利用前几个预测后一个词
- 不同的是,这里将每句话映射成一个句向量,联合预测后一个词出现的概率
这样就学习到了每个词的词向量和每句话的句向量
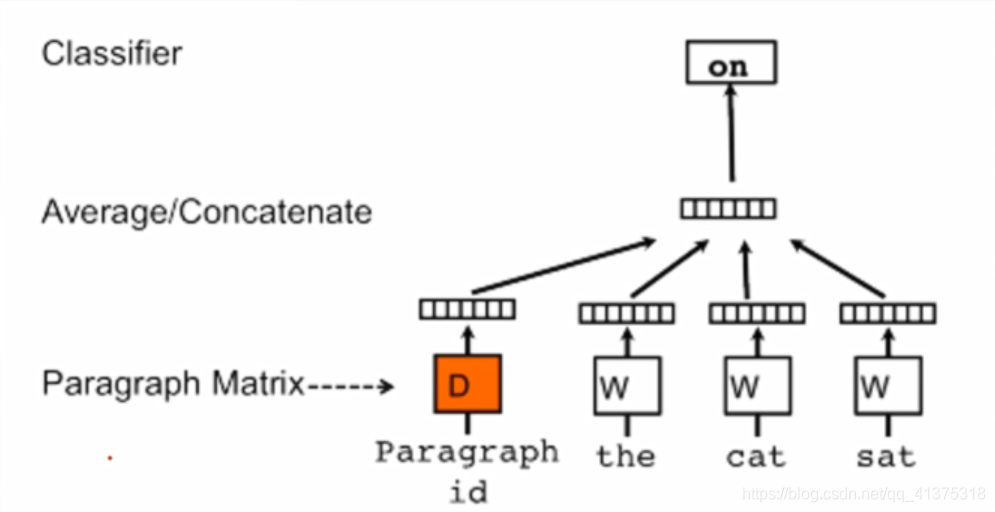
橘色的是句向量,右边三个是词向量
句向量+词向量得到映射的一个词
本模型可以学到语义和语法信息
窗口大小包括预测的那个词
训练阶段:
通过训练集构建词表,并随机初始化词向量W和训练集的句向量矩阵D。设置n-gram,文中为窗口大小,然后利用句向量训练模型,训练矩阵模型的所有参数,包括词向量矩阵和句向量矩阵
最后将学习到的句向量用于分类器预测句子的类别概率
测试阶段:
固定词向量矩阵W和模型的其他参数,重新构建句向量矩阵D并随机初始化,然后利用梯度训练矩阵D,从而得到测试集每个句子的句向量
无序句向量训练模型
文本还提出了一种Bag-of-words,即忽略词序信息的模型
算法:
- 每个句子通过随机初始化句向量矩阵映射成一个句向量,然后通过句向量每次随机预测句子中的一个词。
- 然后将学习到的句向量送到已经训练好的分类器,预测句子的概率
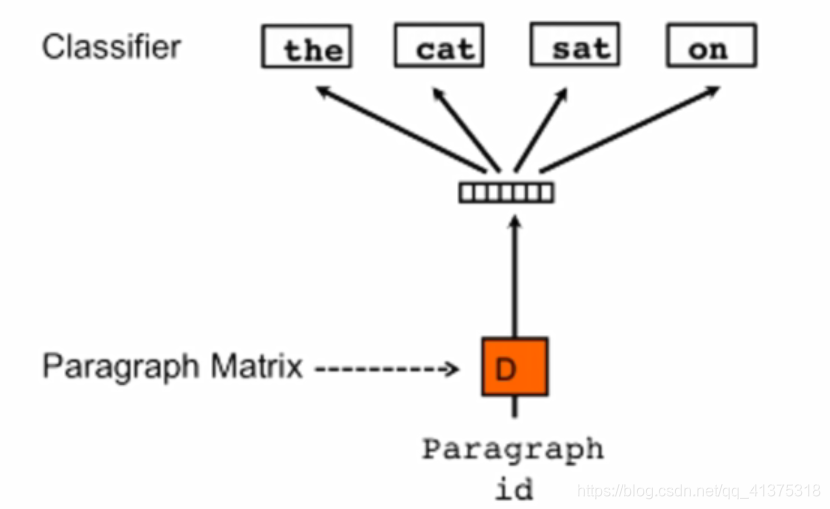
本文分别使用提出的两种模型训练得到两个句向量,然后将两个句向量合并(concatenate),得到最终的句向量表示
4. 实验结果
一 数据集:
SST
IMDB
评价方法:SST:5分类也可以2类 IMDB:2分类
二 实验结果
第二列为二分类结果,第三列为五分类结果,实验结果显示本文提出的句向量方法优于朴素贝叶斯、SVM、词向量平均法、神经网络方法,在二分类和五分类任务都取得了最好的结果。
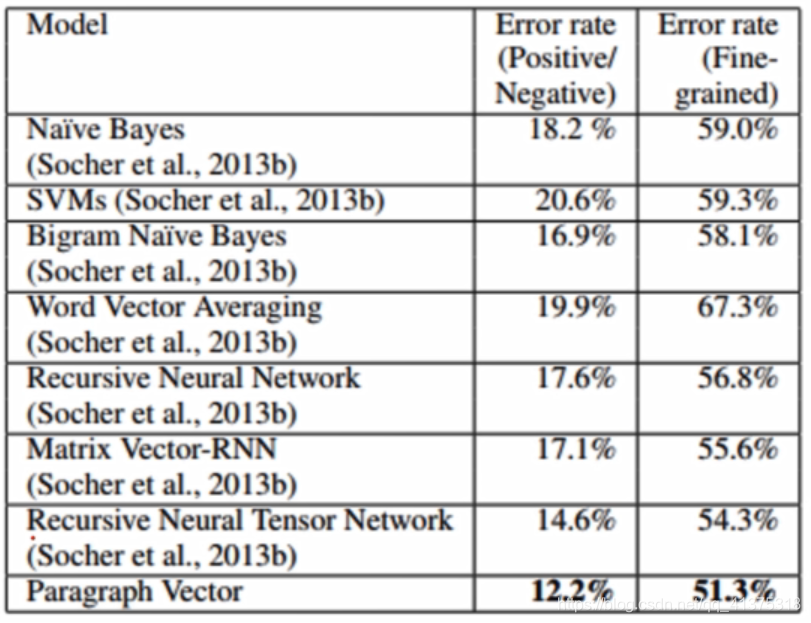
在IMDB也取得了最好结果
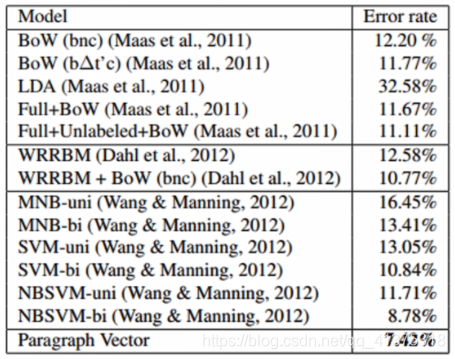
5. 讨论和总结
-
目前主流的句向量表示方法:
基于神经网络的句向量学习方法(多快好省),使用预训练的词向量,神经网络可以得到非常好的句向量表示 -
训练过程还需要训练,大大降低了效率? 是
使用基于神经网络的句向量学习方法,当前流行的ELMO,BERT -
是否还有其他句向量训练方法?
后人提出的seq2seq模型句向量训练方法 -
主要创新点
A 提出了一种新的无监督句向量训练方法
B 可以直接用于下游任务
C 在论文发表的时候取得了SOTA的结果
三 代码实现
四 问题思索
- 思考:Bag-of-words 的缺点,如何改进
